
Nature:也许AI可以有常识,但不是现在。







【导读】七十年前科学家们想象的「机器常识」LLM实现了吗?最近一篇关于Nature的评论文章给出了否定的答案,并且坚定地指出:常识推理是AGI的必需品。
自2022年ChatGPT问世以来,LLM已经进入了一天万里、突飞猛进的发展阶段。
一些专家和研究人员推断,这些模型的出现代表着我们。「通用人工智能」(AGI)人工智能的实现已经迈出了决定性的一步,从而完成了 (AI) 对70年来的探索进行研究。
在这个过程中,一个重要的里程碑,就是机器能展示出来「常识」。
对于人类而言,「常识」这是关于人与日常生活的问题。「很明显的事情」。举例来说,我们要从经验中知道,玻璃是易碎的,或是给吃素的朋友端上一盘肉是不礼貌的。
然而,在「常识」在这一点上,即使是今天最先进、最强大的LLM也常常不符合要求。

在2022年的英国Glastonbury音乐会上,一位机器人艺术家为表演者画画。
LLM非常擅长在与记忆相关的测试中取得高分。比如GPT-4最受称赞的成绩之一就是可以通过美国医生和律师的执业考试,但是还是很容易被简单的谜题搞糊涂。
假如你问ChatGPT「Riley很痛苦,以后她会有什么感觉?」,它将从许多列表中挑选出来「觉察」(aware)与人类相比,这是一个正确的答案。「痛苦」(painful)。
为解决这方面的不足,很多这样的选择题都被纳入了流行的基准测试,用来衡量AI对常识的掌握。
然而,这些问题很少真正体现在现实世界中,包括人类对物理定律的直觉理解,以及社会背景和情境。因此,有必要量化LLM。「类人」水平仍然是一个尚未解决的问题。
与AI相比,我们可以发现人类所理解的一些差异。
第一,人类善于处理不确定和模糊的情况,将局限于一种情况。「令人满意但不一定是最好的」答案,很少消耗大量的认知资源来寻找最佳的解决方案。
第二,人类可以存在「直觉推理」和「慎重考虑」方法间灵活转换,从而更好地应对小概率的突发情况。
AI能否实现类似的思维能力?怎样才能准确地知道AI系统是否正在获得这种能力?
这不仅是AI或计算机科学的问题,也涉及到心理学、认知哲学等学科的发展。同时,为了设计更好的指标来评价LLM的表现,我们还需要对人们认知过程的生物基础有更深入的了解。
AI从什么时候开始发展常识?
机器常识的研究还是要追溯到1956年新罕布什尔州达特茅斯的暑期研讨会,这是深度学习领域不得不提到的时间点。
这次会议聚集了当时顶级的AI研究人员,然后基于逻辑的符号框架诞生了,用字母或逻辑操作符来描述对象和概念之间的关系,用来构建关于时间、事件和物理世界的常识知识。
例如,一系列「假如出现…,那就会发生…」这些句子可以手工编程到机器中,用来教授一个常识性的事实,例如,不受支持的物体会因重力而下落。
这一研究确立了机器常识的愿景,即构建能像人类一样有效地从经验中学习的计算机程序。
从技术角度来看,这个目标是制造一台机器,在给定一组规则的情况下,「根据已知的内容和信息,我们可以自己推断出足够广泛的直接结果。」 。

一个人形机器人在加州举行的机器人挑战赛中后退
所以,机器常识不仅仅局限于有效的学习,还包括自我反省和抽象。
本质上,常识需要事实知识和推理知识的能力。仅仅记住很多事实是不够的。从现有信息中推断新信息同样重要,这样我们就可以在新的或不确定的前提下做出决定。
20世纪80年代,研究人员开始初步尝试,希望赋予机器常识和管理能力。主要手段是建立结构化的知识数据库,比如CYC。、特色如ConceptNet。
这个名字的灵感来源于CYC「百科全书」(encyclopedia),不但包含了事物之间的关系,而且试图利用关系符号来整合前后相关知识。
所以,有了CYC,机器就能区分事实知识(例如「乔治·华盛顿是美国第一任总统。」)以及常识知识(例如「椅子是用来坐的」)。
ConceptNet项目也有类似的原理,它还将关系逻辑映射到一个由三元词组组成的庞大网络中(例如「苹果」—「用于」—「吃」)。
但是,不管是CYC,还是ConceptNet,都没有推理能力。
常识性推理的挑战在于抽象,因为在提供更多信息之后,情况或问题将变得难以确定。
举例来说,想要回答「Lina和Michael都在节食,他们来做客的时候我们要不要准备蛋糕?」如果增加了另一个事实,这个问题「它们有cheat days」,回答会变得更复杂,更难做出选择。
基于符号和规则的逻辑无法处理这种抽象,即使下一个token的LLM是通过概率生成的,也无济于事,因为关于引入。「cheat days」额外的信息不但可以降低确定性,而且可以完全改变情况。
AI系统如何应对这种未见和不确定的情况,将直接决定机器常识进化的速度。我们要做的就是开发更好的评价方法来跟踪相关的进展,但是「衡量常识」这项任务看起来并不那么容易。
LLM有常识吗?这个很难评价
目前,在80多个著名的AI系统常识推理能力测试中,至少有75%是多项选择测试。但是,从统计学的角度来看,这样的测试最多只能给出模糊的结果。
向LLM提出一个相关领域的问题,并不能揭示模型是否有更广泛的事实知识,因为LLM在响应特定查询时,不会以统计上有价值的方式从知识库中取样。
举例来说,即使向LLM提出两个非常相似的问题,也有可能得到完全不同的答案。
对不涉及多选题的检测,如为图像生成合适的标题,也难以充分探测模型的多步、常识推理能力。
不涉及多项选择测试的测试(例如,为图像生成适度的图像标题)不会完全检测模型显示灵活性、多步骤、常识推理的能力。
因此, 与机器常识相关的测试方法和方法仍然需要开发,从而更加清晰地区分「知识」和「推理」。
有一种方法可以用来改善目前的测试,那就是要求AI解释给出当前答案的原因。比如一杯咖啡放在室外会变冷,这是常识,但推理过程涉及热传递、热平衡等物理概念。
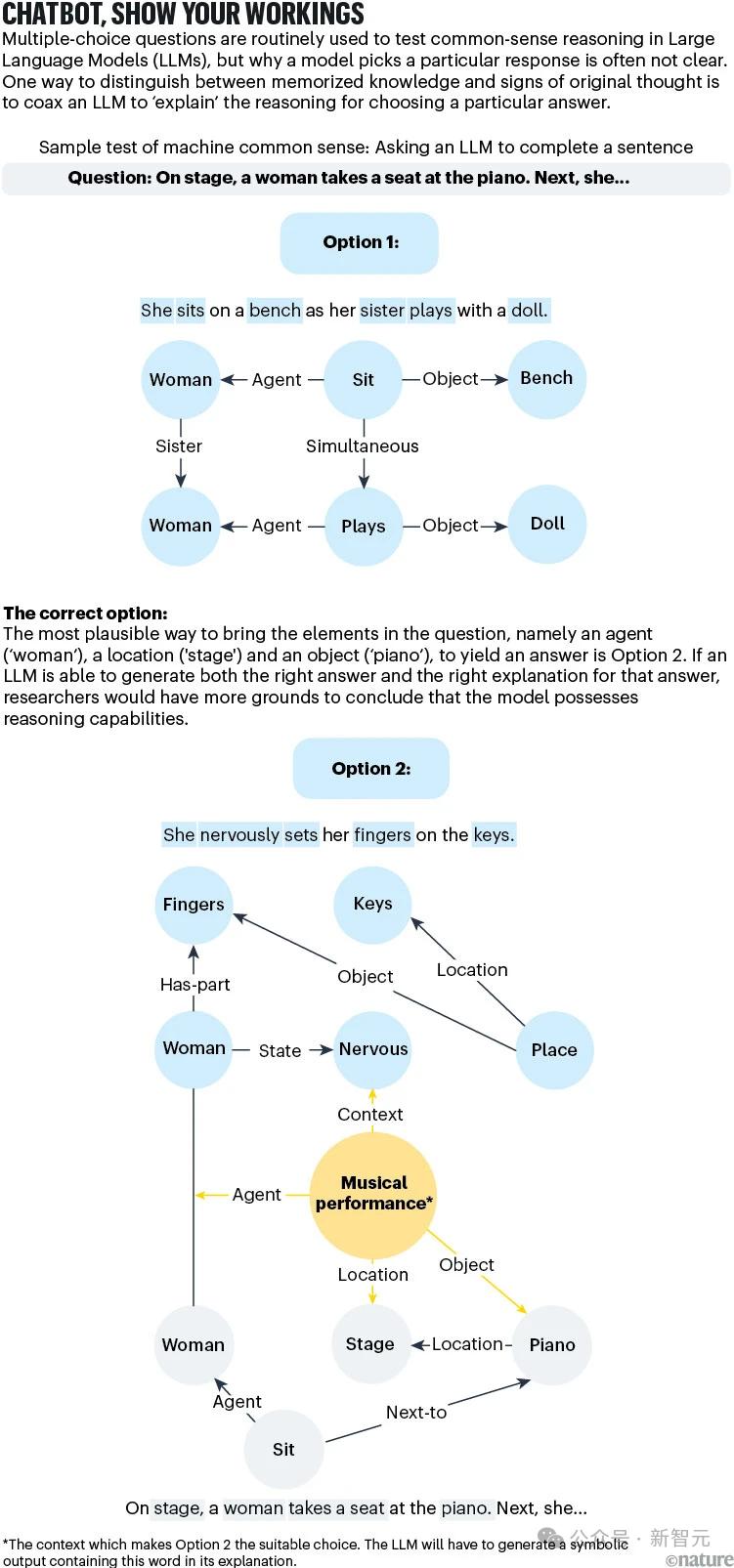
尽管LLM可能会产生正确的答案。(「因为热量逸散到周围的空气中」),但是基于逻辑的反应需要一个循序渐进的推理过程来解释原因。
如果LLM能够使用CYC项目创建的符号语言来复制正确的原因,我们更有理由认为模型不仅仅是通过参考训练语料材料来找到答案,而是通过常识推理能力来发展。
另外一种开放式测试,就是考察LLM的计划或战略规划能力。
想象一个简单的游戏:能量令牌随机分布在棋盘上,玩家需要在棋盘上移动20次,收集尽可能多的能量,放在指定的地方。
这类游戏中,人类可能找不到最好的解决办法,但是常识推理足以帮助我们获得合理的分数。那么LLM呢?
经过研究人员的测试,发现模型的性能远低于人类。
从LLM的动作来看,它似乎明白了游戏规则:它可以在棋盘上移动,有时它可以找到能量令牌并收集它们,但它们很容易犯各种看似愚蠢的错误,比如把能量令牌放在错误的位置。
鉴于LLM容易犯这种常识性的人不会犯的错误,我们很难指望这种模式在处理更混乱的现实规划问题时会有更好的表现。
下一步该怎么走
为系统地为机器常识奠定基础,可选择采取以下步骤:
「把盘子做大」
研究人员需要超越简单的AI或计算机科学领域的经验,参与认知科学、哲学和心理学,找出如何学习和应用常识的关键原则。
这一原则应引导我们建立一个可以进行类人推理的AI系统。
拥抱理论
同时,研究人员需要设计一个全面的理论驱动基准测试,反映广泛的常识推理技能,如理解物理特征、社会性和逻辑关系。
对于这些基准测试的目标,我们必须量化AI系统跨领域总结常识知识的能力,而不是专注于一组狭窄的任务。 。
超越语言的探索
夸大LLM能力的风险之一是夸大语言的重要性,这可以让我们与另一个重要的愿景脱节——构建一个具体的系统,可以在混乱的现实环境中感知和导航。
MustafafadDeepMind创始人 Suleyman认为,实现「有实力」的AI(capable)这可能是一个比AGI更有效的里程碑。
至少在人类的基本水平上,具体的设备常识是非常必要的,如果你想建立一个具有物理能力的人工智能。然而,目前的AI似乎还处于获得儿童水平和身体智力的初始阶段。
令人高兴的是,研究人员开始在上述方面取得进展,但是仍然有很长的路要走。
随着人工智能系统,尤其是LLM已经成为各种应用的主要内容,理解人类推理的能力将在医疗卫生、法律决策、客户服务和自动驾驶领域产生更可靠、更可靠的结果。
例如,具有社会常识的客户服务机器人即使没有明确表达,也能推断出用户的抑郁情绪。
从长远来看,也许机器常识领域的最大贡献就是让人们对自己有更深的了解。
参考资料:
https://www.nature.com/articles/d41586-024-03262-z
本文来自微信微信官方账号“新智元”,作者:新智元,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com