
大型AI模型落地,为什么央国企先行?







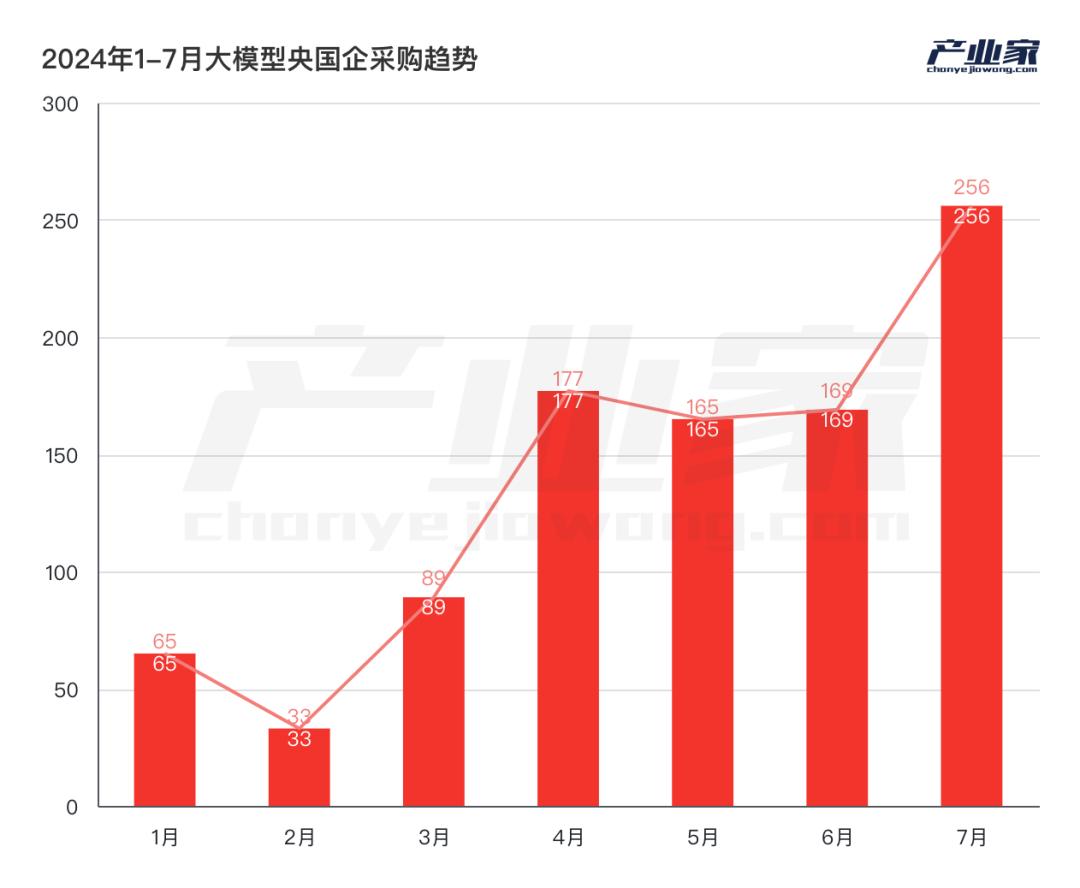
从2024年1月到7月,中央国企采购了950多个大型项目,在智算中心、大型预训练、Agent和应用领域均匀布局。除了政策影响,中央国企落地大模型背后还有哪些推动因素?
最高191亿元,最低1万元。经过两年的狂奔,国内已经形成了“AGI队”。与此同时,还有央国企的大型项目建设。
八月六日,神州数码集团宣布,其子公司神州鲲泰中标《中国移动2024-2025年新型智算中心采购(标包1)》,投标价格约191亿元,中标份额约10.53%。湖南省委党校湖南行政学院于2024年7月发布招标信息,采购数字机器人服务,价格9000元。


一是智能计算中心采购,二是数字机器人服务;可以看出,目前在中央国有企业,大型项目的建设已经走到了一半。毫不夸张地说,在模型浪潮席卷的当下,中央国有企业逐渐成为推动国内大部分AI模型落地项目的先锋力量。
根据不完全统计,从2024年1月到7月,中央国有企业采购了950多个大型项目,在智算中心、大型预训练、Agent和应用领域均匀布局。
大模型陆续落地国有央企。在如此壮丽的战斗背后,政策推动成为决定性因素。根据沙丘智库,自2023年以来,国有资产监督管理委员会多次要求中央企业发展人工智能。其中,在2024年2月的中央企业人工智能专题推广会上,中央企业提出“开展AI” 专项整治”。会上,10家央企签署了一份倡议,表示将积极向社会开放人工智能技术场景。
同年7月,国务院办公室召开“推进创新发展”系列主题新闻发布会,提出央企预计未来五年安排大规模设备更新改造总投资超过3万亿元,更新部署一批高科技、高效、高可靠的先进设备。
政策的推进当然是不可忽视的因素。但除了政策的影响,央国企落地大模型背后还有哪些推动因素,站在产业数字化和数字化智化的最前沿?一个更值得思考的问题是,与云计算时代金融行业成为先锋不同,为什么央国企在当今的AI模型时代成为先锋?
运营商、政务、能源抢先建设智算中心
AI模型史上最大的项目,应该属于“智算中心”。
随着预训成本的疯狂上升和推理需求的不断上升,智算中心已经成为必需品。最近,OpenAI CEO Sam 在一次采访中,Altman表示,“OpenAI今年不会发布ChatGPT-5,目前公司正致力于ChatGPT-o1的研发和运营。”
GPT-5为什么不发?为什么原本预计延迟发布的o1提前出现?这背后的原因不禁让人深思,培训成本是关键因素之一。
离家近一点,国内对大模型预训练的需求越来越迫切。在加快建设国内AGI梯队的同时,性能不断刷新的大模型需要大规模智算集群的支持。现在,万卡集群已成为大型军备赛的必需品。除了国内的AI企业和通信运营商,为了提高AI大模型的实践和推理效率,正在加快建立中央国有企业的智算集群。
一般来说,智能计算中心是由地方政府或通信运营商主导建设的。据中国信通院不完全统计,截至2024年7月底,已有87个智能计算中心(包括已建和新建)被纳入监测。
沈阳智能计算中心新基建工程总承包2023年10月(EPC)交易结果公布后,百度与中国建筑第八工程局有限公司(中国建筑第八局)成功中标,中标金额9.1亿元。主要包括机房建设、机柜设计、智算中心平台、百度提供的AI软硬件能力综合解决方案。
对于这样的智能计算中心采购项目,央国企已经开始铺天盖地的建设。对此,根据金额,产业家列举了近两年央国企采购智能计算中心项目金额最高的10个。
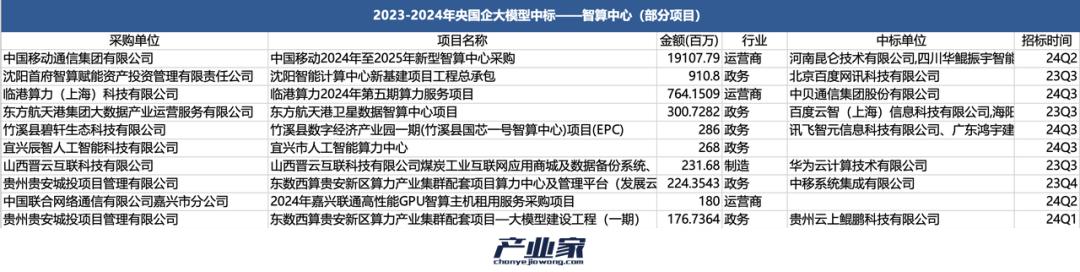
与云计算时代相比,传统数据中心的中标人大多是IDC制造商;在当今的AI时代,有许多AI公司和互联网制造商。
此外,从行业分布来看,政府和运营商对智能计算中心的投资更大。对此,产业家统计了智能计算中心项目在运营商、能源和政府三大领域的比例:数据显示,政府行业对智能计算中心的投资更大,包括GPU租赁、硬件和计算率调度平台的采购。

实际上,从智算中心的投资比例可以看出央国企对AI大模型的需求。
可看出,自2023年第三季度以来,中央国有企业已开始密集规划智算中心建设。而且智算中心只是中央国有企业落地AI的起点之一。
一方面,这正好符合上述政策时间点;另一方面,2023年第三季度刚刚形成了以百度、阿里、华为、通信运营商为首的“国内AGI梯队”。
除智算中心外,央国企对AI大模型建设的另一个重点是应用领域,即为特定场景搭建大模型平台或应用。
以通信运营商为例,据不完全统计,自2023年以来,运营商已经建设了238个AI模型项目,其中除了75个智能计算中心外,其余都围绕特定情况构建了大型模型,主要包括智能客服、营销和数字采购。
对AI大模型的需求因行业而异,项目的重点自然也不同。对于政府和运营商行业来说,智能计算中心之所以占比更大,除了政策推动之外,更重要的原因是对私有部署和地方部署的需求极高,尤其是在政府领域。另一方面,与其他行业对单点或不同阶段的大模型应用开发相比,政府和运营商对大模型的需求更加系统化,需要从GPU资源到计算率调度平台来发挥作用。
相比之下,在使用AI模型最多的三个行业中,能源领域对智能计算中心的投入较少,而更多的是关注大模型的训练和开发,尤其是如何训练和优化特殊情况下的算法,如何微调模型等等。
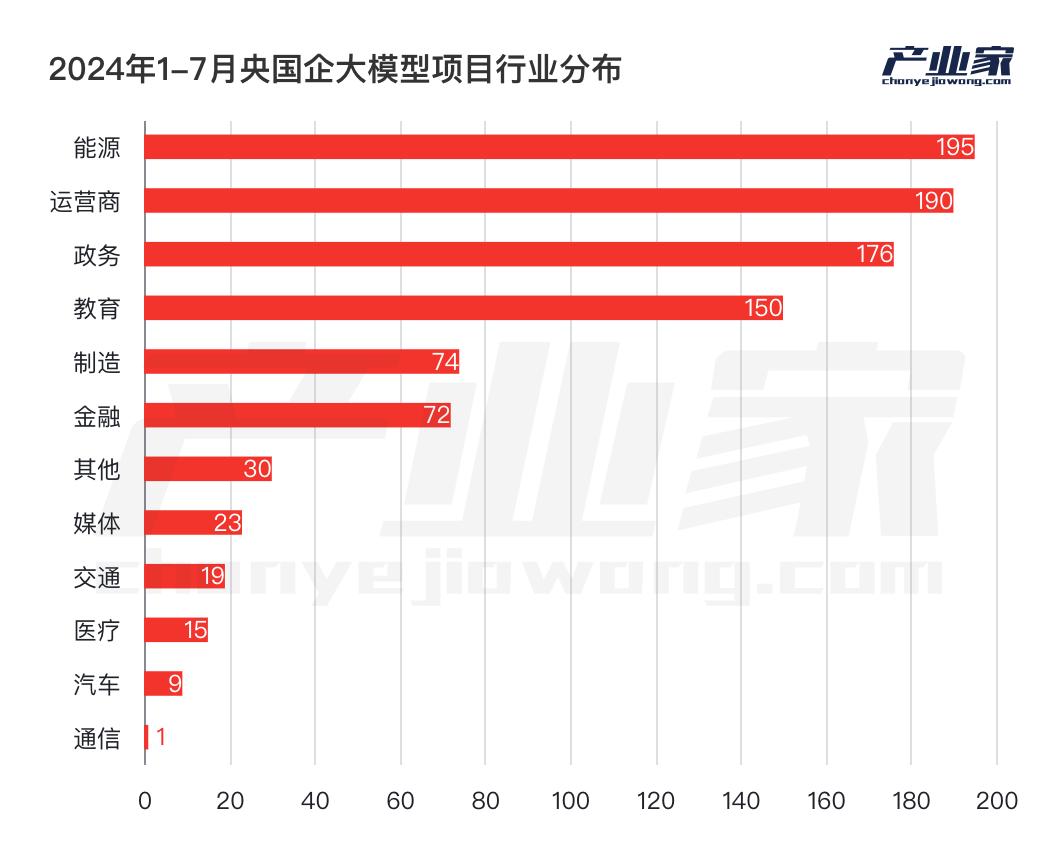
此外,值得注意的是,对于这些对行业know-how要求较高的领域,他们在选择中标人时更加重视;比如在选择计算率调度平台和大模型预训练开发阶段时,中标人围绕以百度、科大讯飞为首的AI公司;但是,在模型开发过程中,当需要特定的技术研究时,会选择更了解know-how的南方电网公司。
最后,与云计算时代不同,金融业成了头部落地试验田;在当今AI大模型时代,在中央国有企业中,教育、能源、运营商、政务四大行业脱颖而出;然而,金融业并没有表现出云计算时代那么强的想法。
AI模型:改变传统IT架构背后的大模型:
时代变迁。
在过去的云计算时代,大企业需要从购买或租赁服务器到选址建设数据中心,再到选择合适的云架构进行数字化转型,再到平台开发阶段和上层应用的建设。
一般来说,对于能源或工业企业等大型公司来说,面对分布在各个环节的数据,通常需要搭建一个底层的PaaS平台,实现灵活的调用和数据共享;然而,数据孤岛和烟囱仍然存在。
然而,这种从IaaS到PaaS再到SaaS的结构在当今的AI模型时代已经被完全颠覆。公司通常需要一个大的行业模型来完成它,而不是花时间建立PaaS平台来建立多个复杂的应用程序。
诚然,公司在云计算时代支付的学费并没有浪费。在AI模型时代,在政策引导、需求迫使、环境因素等多方面的影响下,央国企已经开始推出AI模型。
而且在这其中,很大一部分是围绕过去云计算时代一些无法解决的顽症,希望在AI大模型中找到更好的解决办法。
我们可以观察到一个现象。目前,中央国有企业侧重于两个方面,一个是智算中心,一个是应用领域。后者包括大模型预训练、大模型开发和大模型应用或解决方案,用于各个阶段或特定场景。
一般而言,后者基于特定场景的大模型解决方案,在过去的云计算时代是无法实现的。
以运营商为例。虽然智能客服已经存在很多年了,但准确地说,自云计算时代以来,各种智能客服软件和解决方案层出不穷。但是对于整个行业来说,人工转移率还是很高的,一般都在80%以上。当时的列车刚刚进入大模型时代,智能客服成为大模型落地的第一个实验场。

例如,在能源行业,如何沉淀知识,如何让新人使用,一直是个大问题。即使在云计算时代,工业互联网平台也很多,很多问题仍然没有答案。而且在当今大模型时代,一个行业大模型可以解决很多问题。其中,RAG建设阶段在行业大模型建设过程中起着关键作用,相当于企业知识库,任何输入知识都可以轻松调用。

如上所示,对于一些行业来说,大模型不是“鸡肋”。相反,它可以扮演“超级大脑”的角色,将企业的所有智慧聚集在一起,发挥有针对性的作用。
但是,对于一些行业来说,大模型目前还没有找到立足之地。
比如在金融行业,很难深入核心业务,因为很多项目都集中在知识库问答上。一方面是出于金融监管和数据隐私的顾忌;另一方面,更重要的是,目前很难完全解决AI幻觉问题,任何AI算法可能对金融行业造成的错误预测和建议都可能带来巨大的经济损失。
无论是智能客户服务还是行业模式,无论是政务领域、运营商还是能源、政务、教育等领域,中央国有企业落地大模式背后都有三个核心原因。
首先,在模型时代,央企多年积累的数据可以发挥作用。它们不仅包括已经总结整理好的结构化数据,如财务报表、交易明细等,还包括聊天记录、文档、照片等一些重要的公司资产。散落在系统结构内部。现在这些非结构化数据可以成为AI模型中的“公司知识库”,发挥其价值;
其次,与过去云计算时代从IaaS到PaaS再到SaaS的三层架构不同,大模型具有很强的协同性。前期只需要在大模型开发阶段进行练习和微调,后期可以直接基于数据支持前端行为。
最后,也是非常重要的一点,中央国有企业本身拥有庞大的服务器集群,其自身具有强大的计算基础,基于这些基础可以更好地推动大模型的落地。
竞争点:预训练、安全和行业know-how
就中标而言,可以毫不夸张地说,央国企撑起了国内大型商业化的半壁江山。
但是,在大模型落地过程中,仍有许多亟待解决的问题。
根据中信建设证券的数据,2024-2027年全球大模型推理的峰值计算能力需求复合增长率为113%,远高于培训的78%。预训练成本和推理成本的叠加也增加了整个AI基础设施的市场份额。
根据艾瑞咨询,2023年中国AI基础数据服务市场规模为45亿元,预计到2028年,其市场规模将达到170亿元,未来五年复合增长率将达到30.4%。
这样也解释了央国企近两年抢建智算中心的原因。但是,阻碍大模型落地过程的不仅仅是计算资源的匮乏。
虽然从IaaS到PaaS再到SaaS的传统三层架构已经颠覆了大模型时代,但在新时代,新的架构也迎来了一些新的挑战,比如AI。 到达InfraMaaS,在上层AI应用中,涉及到许多模型建设的环节,这些都需要大型服务提供商和企业共同探索落地路径。
对于中央国企来说,虽然用AI大模型赋能已经成为共识,但公司对于如何使用大模型,在哪个环节增加大模型,如何发挥大模型的作用,如何开发和训练大模型并没有太多的想法。因此,这对AI大模型供应商提出了更高的要求。
这个过程中,供应商是否掌握行业know?-how,有时甚至可以成为能否获得目标的重要因素。对于这一点,以百度、华为、科大讯飞为首的AI大模型公司,都在2024年掀起了“行业大模型”的旗帜。
根据统计,在能源领域,2024年上半年出现了许多在预训练过程中进行某些技术研究的投标项目。

另外,值得注意的是,随着AI应用向深水区发展,数据安全、信息共享、数据追溯等问题也开始逐一转移到台面上。据悉,10月9日,中办、国办正式发布《关于加快公共数据资源开发利用的意见》,提出到2025年初步建立公共数据资源开发利用制度规则;到2030年,公共数据资源开发利用制度规则更加成熟,资源开发利用制度全面建成。
虽然今天的AI模型可以实现数据追溯,但AI服务提供商和公司应该探索责任划分和数据安全等问题。
本文来自微信微信官方账号“产业家”,作者:思杭,编辑:皮爷,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com