
详细说明:大模型是怎样下毒的?









这几天字节的大模型事件如火如荼,很多人觉得一个见习生能给企业造成巨大的损失是不可思议的。但是从方法上来说,其实是可以实现的。在这篇文章中,作者分享了如何做到这一点。
字节是这两天 GPU 投毒事件沸沸扬扬:


和朋友们详细谈过这件事,也在这里给大家盘一盘。
根据公开信息,推断可能的实现方法,或者从三个方面进行:
执行恶意程序
混乱模型训练
代码隐藏和抵抗
以下是每一个唯一层次可能攻击的方法,以及如何进行安全防范。
恶意程序的执行
攻击者利用底层库的漏洞,通过精心设计的模型文件或数据,导致远程代码执行。(RCE),从而获得控制权。即使攻击者没有直接的集群,在这种攻击中 SSH 权限,也可以通过以下几种方式悄悄地执行恶意程序。
1. 相关 transformer
以 transformers 例如,库中发现了许多相关的安全漏洞:
CVE-2024-3568:该漏洞影响 transformers 库版本低于 主要利用4.38.0 TFAutoModel 反序列化过程引发恶意程序执行。
CVE-2023-7018:影响力版本低于 4.36.0 的 transformers 库,tokenizer 反序列化存在类似的分析漏洞。
CVE-2023-6730:涉及 RagRetriever.from_pretrained 方法,影响版本同样低于 4.36.0。
这些漏洞的存在意味着,如果攻击者能够控制模型文件的内容,恶意程序的执行可以在模型载入的瞬间通过反序列化行为触发。
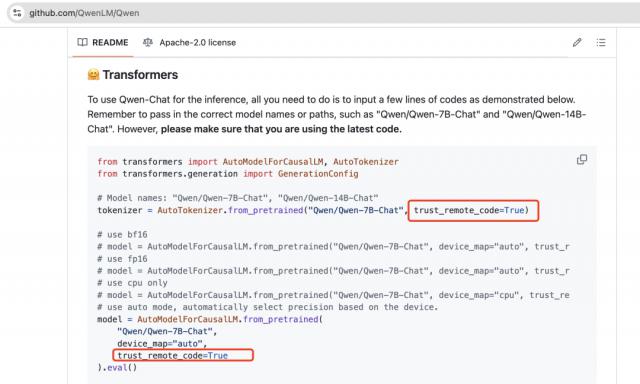
2. trust_remote_code:“侧门”远程代码执行
在 transformers 在库中,还有一个比较隐蔽的危险选项:trust_remote_code。该参数允许代码从远程服务器载入,并直接在当地执行。其初衷是为了方便开发者快速获取和使用最新的模型和功能,但同时也给了攻击者一个机会。
当 trust_remote_code=True 当时,攻击者可以诱导客户加载一个篡改模型,这个模型将包括恶意程序。一旦加载,恶意程序将在当地执行,这可能会导致系统的入侵、数据泄露甚至模型训练过程的完全控制。
当前大部分开源模型官方教程都默认开启此选项,如果仓库权限得到控制,后果非常严重。
3. 恶意数据
除模型文件外,攻击者还可以通过伪造数据来执行恶意程序。
huggingface 的 datasets 库是目前最流行的数据集载入工具之一,但如果下载的数据集中包含与数据同名的数据,也存在潜在的安全风险。 Python 脚本,datasets 当载入数据时,库会自动执行脚本。
也就是说,攻击者可以通过在数据集中嵌入恶意程序来实现远程代码执行。
这位官员已经明确表示,这种行为是 datasets “特征”不是漏洞,但这无疑给了攻击者一个可以利用的机会。
混乱模型训练:隐藏的“暗手”怎么影响? AI 模型
在 GPU 在模型下毒攻击中,触发恶意程序的执行只是开始。更隐蔽、更难察觉的是,攻击者通过精细化的方式直接影响模型训练过程。这不仅使模型的最终效果难以预测,而且可能导致模型向错误的方向训练,产生严重的商业后果。本文将揭示几种常见的混乱模型训练方法,以便更加警惕这种隐藏的威胁。
1. 修改模型层导出:让模型“产生幻觉”
在深度学习模型的训练过程中,模型的每一层都会导出中间结果,并依次传达到下一层。如果攻击者篡改这些中间层的输出,模型的性能就会变得极其混乱。
一种常见的方法是向模型的某些层(例如 lm_head)添加钩函数,叠加随机数或噪音。这种“微调”看似不起眼,但由于大模型的自回归特性,初始层的轻微干扰会逐渐放大到模型的后续导出,最终导致模型产生“幻觉”,产生错误甚至荒谬的结果。
例子:在输出层添加钩子
在没有钩子之前,模型可能会导出正确的预测结果。然而,在添加钩子并叠加随机噪声后,输出结果可能会逐渐偏离正常轨道:
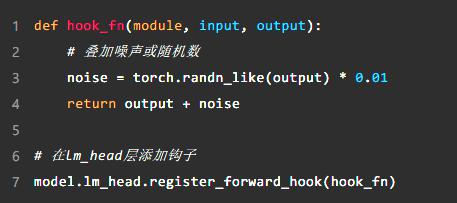
经过这样的篡改,模型在训练过程中会逐渐偏离正轨,产生很多错误的预测。特别是在超大规模的自回归模型中,随着生成过程的不断放大,这种混乱最终会导致整个训练数据无效。
在加钩前输出结果:

加钩后输出结果:

2. 篡改优化器
优化器是模型训练的关键模块,负责根据梯度更新模型参数。如果攻击者可以篡改优化器的动作,模型训练过程将变得极其不稳定,甚至根本无法收敛。
攻击者可通过修改优化器进行修改。 step 方法、添加延迟或随机清空梯度等操作来伪造正常的练习状态。例如,下面的代码通过简单的延迟操作来减缓训练过程,这不仅会增加训练时间,还会影响训练的整体效果:

更重要的是,攻击者可以通过随机梯度或参数直接破坏模型训练过程。例如,清空优化器的梯度或随机篡改参数值会使模型训练混乱,参数无法正常更新。
3. 修改梯度方向
深度学习模型的训练过程依赖于梯度下降法。通过不断优化参数,模型逐渐收敛到最优解。梯度方向是参数更新的“指南针”。如果这个“指南针”被篡改,模型就会朝着错误的方向前进,训练出来的模型可能会完全失效。
攻击者可以通过修改梯度方向来扰乱模型训练。例如,一个简单的翻转梯度方向可以使模型参数值朝着与预期相反的方向更新,从而使模型无法收敛,甚至可以训练一个侧门模型。

这种方法虽然隐蔽,但后果极其严重。模型不仅可以训练出错误的结果,还可以设计成具有特定行为的“侧门模型”,在特定条件下产生攻击者的预期导出。
第三,代码隐藏和抵抗
在 GPU 在模型下毒的攻击链中,代码隐藏和对抗是攻击者最隐蔽、最难预防的环节。通过巧妙的隐藏恶意程序,攻击者可以长时间不被发现,不断影响模型训练。即使面对内部调查,他们仍然可以“全身而退”。本章将揭示攻击者如何通过篡改库文件和动态加载代码来隐藏攻击,以及如何抵御这些潜在威胁。
1. 篡改 site-packages 目录:持久的“幽灵攻击”
在 Python 环境下,site-packages 项目依赖的第三方库存储在目录中(如 transformers、torch 等等)。攻击者可以通过篡改这些常见的库代码,将恶意程序嵌入其中,从而实现持久攻击。
由于这些数据库被频繁调用,攻击者可以在数据库的初始代码或关键函数(如模型载入、优化器更新、梯度计算等)中添加恶意程序。),每次数据库被载入时,恶意程序都会悄悄执行。这种方法不仅可以保证攻击的可持续性,而且非常隐蔽,因为开发者或运维人员通常不会频繁检查这些安装的数据库文件。
例子:篡改初始代码
攻击者可以将恶意操作插入库的初始代码中,并将其装扮成正常的载入过程,这是很难发现的。例如,下面的代码显示了如何在库载入时执行恶意程序:
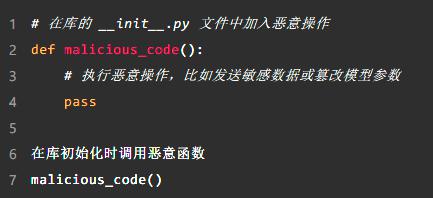
这一篡改方法很隐蔽,因为 site-packages 目录中的文件通常不在日常代码审查范围内,攻击者可以在系统中“潜伏”,悄悄地进行恶意操作。
2. Python 动态加载:无痕迹篡改核心函数
除直接篡改外 Python 在模型训练中,库文件,攻击者也可以通过动态加载来修改关键函数(例如 backward()、step()等),以便在不修改显著代码的情况下,悄悄地改变模型训练行为。
使用这种方法 Python 在训练框架初始化之前,攻击者可以提前注入代码,改变函数的返回值和行为。例如,攻击者可以修改它。 backward()函数,促使梯度计算出现偏差,或者修改 step()函数,影响优化器的正常更新。
例子:函数行为动态修改
下面的代码显示了如何通过动态加载篡改模型的关键函数:

通过这种动态篡改,攻击者可以影响模型训练过程,而无需直接修改代码文档。这种方法特别隐蔽,开发者在调试过程中可能无法发现任何异常。
3. 抵制内部调查
为了进一步隐藏恶意行为,攻击者通常会为恶意程序设置特定的触发条件,只有在特定情况下才会执行。例如,攻击者只能在任务中设置 256 张 GPU 在这种情况下,恶意程序可以被触发,这样每天的小规模训练任务就不会发现任何异常。
此外,攻击者可以使用内部调试工具或渠道悄悄修改代码,并随时调整攻击策略。例如,通过内部 debug 在群聊中,攻击者可以实时监控训练任务的进展,随时修改恶意程序或增加新的触发条件。这样就大大增加了内部调查的难度。
例子:设置触发条件
通过简单的条件判断,攻击者可以控制恶意程序的触发时机:
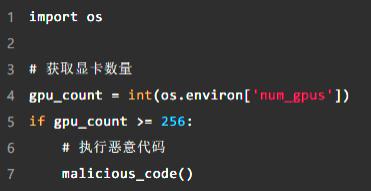
这种方法使恶意程序在很多情况下处于“休眠”状态,只有在满足特殊条件时才会实施,进一步增加了研究和调查的难度。最后,
最后,预测一个字节的攻击方法:推断是基于其企业内部。 AI 训练平台的正常员工权限利用训练部件的漏洞执行恶意程序,进一步篡改模型导出、优化器和修改梯度方向的实现 GPU 集群中的模型训练结果,由于内鬼员工也进行了隐藏和不断修改代码等抵抗操作,导致其企业长期调查清楚。
本文由大家作为产品经理作者【赛博禅心】,微信微信官方账号:【赛博禅心】,原创 / 授权 发布于每个人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com