
突破智能光计算训练难题的清华交叉团队







原创 清华大学 清华大学
清华大学电子工程系方璐教授课题组
戴琼海教授自动化研究小组
另辟蹊径
首创全向智能光计算训练架构
开发了“太极”-II"光训练芯片
完成光计算系统
高效、精确的大规模神经网络训练
该研究成果
“光神经网络全向训练”问题
八月七日晚于北京时间
在线发表于《自然》期刊

清华大学电子系是论文第一单位,方璐教授、戴琼海教授是论文的通讯作者。清华大学电子系博士生薛智威和博士后周天?电子系博士生徐智昊和之江实验室虞绍良博士参加了这项工作。本课题得到了国家科技部、国家自然科学基金委、北京信息科学与技术国家研究中心、清华大学-之江实验室联合研究中心的支持。
在审稿评论中,Nature审稿人提到“这篇文章提出的想法很新颖,这种光学神经网络(ONN)训练过程是前所未有的。提出的方法不仅有效,而且容易实现。因此,它有望成为广泛应用于光学神经网络和其他光学计算系统的工具。"
巧用对称,助力光计算摆脱GPU依赖
近年来,具有高计算能力和低功耗特征的智能光计算逐渐走上了计算率发展的舞台。通用智能光计算芯片“太极”的出现就是其中的一个缩影。它首次将光计算从原理验证推向大规模实验应用,以160TOPS/W的系统级能效为大规模复杂任务“推理”带来曙光,但未能释放智能光计算的“训练能力”。
与模型推理相比,模型训练需要大规模的计算率。然而,目前的光神经网络训练严重依赖GPU进行离线建模,需要物理系统的准确对齐。就这样,光学训练的规模受到了很大的限制,光学高性能计算的优势似乎被无形的枷锁所束缚。
此时,方璐和戴琼海研究组找到了“光子传播对称”的钥匙,将神经网络训练中的前向和反向传播等同于光的前向传播。
论文第一作者、电子系博士生薛智威表示,在太极-II结构下,梯度下降中的反向传播已经转化为光学系统的前向传播,光学神经网络的训练可以通过数据-偏差两次前向传播来实现。两次前向传播具有自然对齐的特点,保证了物理梯度的精确计算。这样,高精度的练习可以支持大规模的网络训练。
太极-II架构不再依赖电计算进行离线建模和训练,因为不需要反向传播,大规模神经网络的精准高效光训练终于实现了。
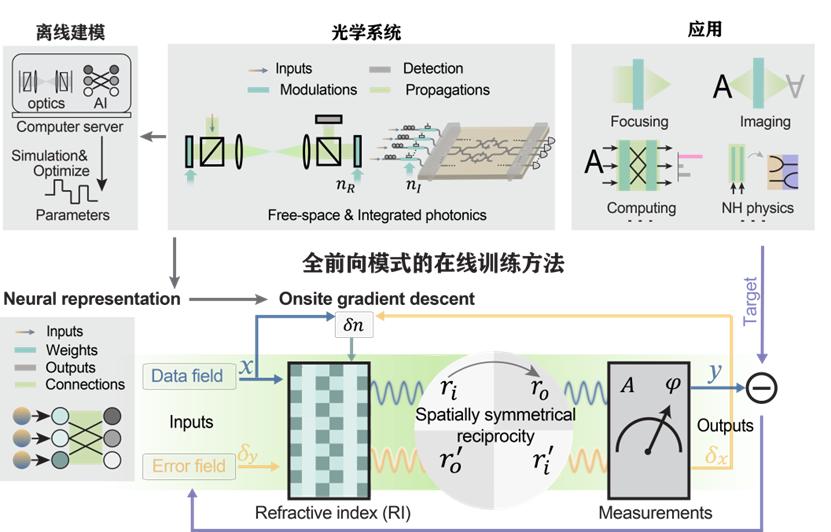
全面向智能光计算训练架构
高效率、精确,智能光训练可以为一切做事
以光为计算媒介,以光的可控传播构建计算模型,光的计算自然具有高速、低功耗的特点。利用光的全向传播来实现训练,可以大大提高光网训练的速度和能效。
文章研究表明,太极-II能够练习各种不同的光学系统,并且在各种任务下都表现出优异的性能。
大规模学习领域:突破计算精度与效率的矛盾,将数百万参数光网训练速度提升一个数量级,代表性智能分类任务准确率提升40%。
复杂情景智能图像:在暗光环境下(每个像素光强度仅为亚光子),能量效率为5.40。×10^6 TOPS全光处理/W,系统级能效提升6个量级。千HZ帧率的智能显像在非视觉场景中完成,效率提升2个量级。
拓扑光子学领域:在不依赖任何模型的情况下,可以自动搜索非厄米奇异点,为高效、精确地分析复杂的拓扑系统提供了新的思路。
通用智能光训练赋能复杂系统
携手太极,推动AI光算率航行远航。
继太极I芯片之后,太极-II的出现进一步揭示了智能光计算的巨大潜力。
例如两仪分立,太极II和II各自完成了高能效AI推理和训练;
另一个例子是两个仪器的和谐,太极I和II共同构成了大规模智能计算的完整生命周期。
方璐说:“我们将这样描述太极系列的辨证合作结构,‘两个仪器的太极之道,正反八荒之道’。我们相信,他们将共同努力为未来的AI模型注入计算率发展的新动力,打造光计算能力的新基础”。
研究小组在原理样片的基础上,积极向智能光芯片产业化迈进,在各种端侧智能系统上进行应用部署。
可以预见,通过包括太极系列在内的光计算领域的不懈努力,智能光计算平台有望为人工智能大模型、通用人工智能、复杂智能系统的高速高效计算开辟新的路径,能耗更低,边际成本更小。

标题:“清华交叉队突破智能光计算训练难题”
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com