
数据工程2-数据存储2-数据存储







它是数据工程概念系列10个部分的第二部分。我们将讨论这个部分的数据存储。
内容:数据库2.数据湖3.数据Lakehouse4.数据网格5.数据虚拟化6.数据虚拟化6。.DataFabric
数据工程概念:第一部分,数据建模
数据库是什么?
数据库是指从不同的相关来源中收集数据,并进行相应的转换,使数据适合分析,然后存储到中央存储库的过程。
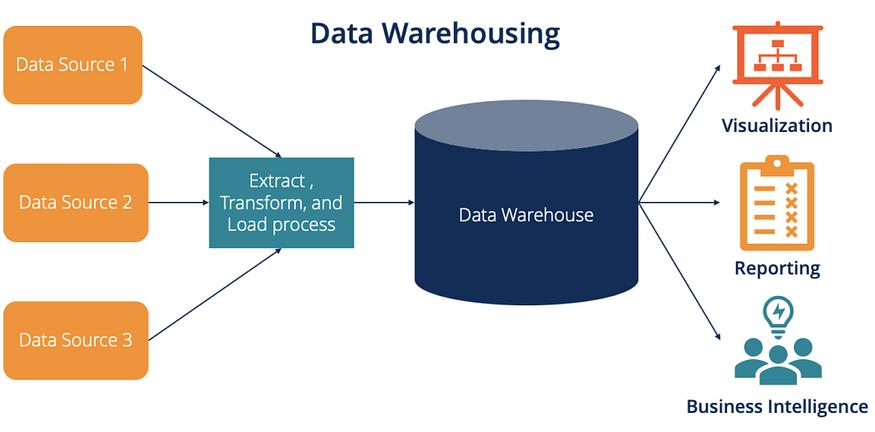
数据库解决方案:
AzureSynapseAnalytics
AmazonRedshift
GoogleBigQuery
数据库的特点
历史数据的存储如果数据库只存储当前数据,就很难随着时间的推移观察数据的趋势。因此,我们需要将历史数据存储在数据仓库中,我们可以使用它来做出由数据驱动的业务决策。
示例:在零售业务中,数据仓库可以存储往年的销售数据,使分析师能够跟踪一段时间的趋势,为未来的营销策略做出明智的决策。
2.集成从多个来源和格式数据可以集成到单个版本的事实中,从而使数据更清晰,并且有一个很好的结构。
示例:医疗保健公司可以在数据仓库中集成电子健康记录、实验室系统和计费系统中的患者数据。这种整合为提高护理协调和决策提供了患者信息的综合视图。
3.数据质量数据库在使用一定的转换后存储数据,这些转换涉及到数据清理、验证和标准化,使其适应并且易于分析团队浏览。
示例:对于金融企业来说,交易可能是由不同的货币进行的,因此需要标准化进行比较。
4.数据安全数据库的访问仅限于获得授权的人员,并有多种加密和审核机制来识别任何欺诈活动。
示例:在教育系统中,需要加密相关学生的表现或SSN号码以及个人详细信息的敏感信息,以避免危害其安全的攻击造成危害。
数据仓库架构有两种很有名的:
Inmon数据仓库架构
数据库鼻祖BillInmon认为统一的信息源是非冗余的、干净的、结构化的,因此必须以3NF标准化的格式存储。
Inmon的方法是一种自上而下的方法,其中数据仓库被分解为代表公司中不同系统(商品、销售、人力资源局财务)的部门数据集市,并根据其特定要求对数据进行划分。
中央数据仓库被称为公司数据仓库。它保证了整个系统的数据完整性和一致性。
优势:1.在成立之前,所有部门都同意单一事实的来源。2.通过标准化建模很容易保存在3NF中,所以没有必要再建模。3.由于缺乏重复,存储量较少,矛盾值的风险很低。
缺陷:1.由于标准化,连接多,报告和查询速度慢。2.组织数据,决定在公司数据仓库中使用哪些业务规则的大量前期工作。3.很难整合和分析不同部门的数据。
示例:在制造业中,与库存、工作时间、销售和商品相关的数据是相互关联的,因此在这里使用Inmon的集中数据存储是有意义的。
Kimball数据仓库架构
RalphKimball提出了这一结构,他致力于根据特定的业务需要通过维度数据建模来创建数据市场,然后一旦所有的数据都加载到数据市场中,它们就会在数据仓库中进行组合。
这是一种基本的方法,首先根据关键工作流程和问题处理数据的关键特征,然后将相应的ETL存储到相应的ETL中。在星形或雪花模式下。
优势:快速、增量地构建数据仓库,让用户参与设计过程,然后快速生成报告。2、优先选择非标准版本,提高用户查询效率。三、星形模式灵活,可扩展,能够适应业务的变化。
缺陷:1.ETL因为不规范而复杂,所以需要时间。2.数据在不同的数据市场上会有冗余,可能会有矛盾。3.由于增量开发,维护将非常困难。
示例:在这种情况下,Kimball架构将是合适的,因为它是一个行业领域,需要查看一些信息而不是整体视图。
数据湖是什么?
数据湖是一种数据存储。它将所有结构化、半非结构化的数据和结构化的数据存储在一个集中存储库中,并以其原始格式存储数据,无需任何预处理。为了满足你的分析需求,有必要为数据元素建立一个唯一的标志和标签。
这些提供了非常好的可扩展性,适用于数据科学家和数据工程师,他们需要使用原始格式并进行分析以获得业务观点。数据湖是一种读取方式(只需要在搜索数据时定义方式),在存储保质期和快速实施方面更具成本效率,因为不需要转换。数据仓库可以将历史数据归档到数据湖中,使其查询更快、更好。
数据湖将支持不同类型的连接器,这些连接器支持数据的批量和流量摄入,并提供控制哪些数据进入数据湖以及如何管理数据的治理功能。
示例:在供应链中,供应商的详细信息可能隐藏在许多系统中,因此很难发现任何问题或找出问题。如果我们从供应商数据、内部订单、承运人数据、天气预报等外部数据源中使用数据来收集信息,那么我们就可以识别延迟的原因和瓶颈。
资料湖解决方案:
AzureDataLake
AmazonS3
ApacheHadoop
数据湖屋是什么?
数据湖屋是数据湖的灵活性和数据仓库管理的融合,由交易层推动。交易层负责确保ACID的合规性(原子、一致性、隔离性和长期性)和并发读取和写入数据类型,如Parquet。、ORC和Avro。ACID合规支持数据治理、隐私法规和高效浏览。
为了实现性能、可访问性和可用性的优化,数据湖屋还提供了添加元数据、缓存和检索的功能。此外,数据可以通过SparkSQL和其他数据帧API工具使用,以满足构建机器学习管道和BI报告的要求。
示例:一家电子商务公司从其网站、移动应用、社交平台、客户支持互动和第三方供应商那里收集数据。通过数据湖屋架构,企业可以将这些不同的数据集提取到集中存储库中,将数据湖的可扩展性和灵活性与数据仓库的结构化查询和ACID事务相结合。利用数据湖站,电子商务公司可获得相关客户行为、产品特性、营销效率和运营效率的宝贵见解。
资料湖屋解决方案:
DeltaLakebyDatabricks
ApacheIceBerg
ApacheHudi
数据网格是什么?
数据网格架构是一种将数据分为特定领域的产品和所有权范式。每个领域都负责自己的品牌,可以拥有适合自己数据的数据模型和基础设施。每个数据产品都应该由用户至上设计和定义良好的交互界面来构建。
根据一系列全球政策和行业法规,治理分布在各个团队中,每个团队都有责任使数据产品可靠、可互操作、可用。
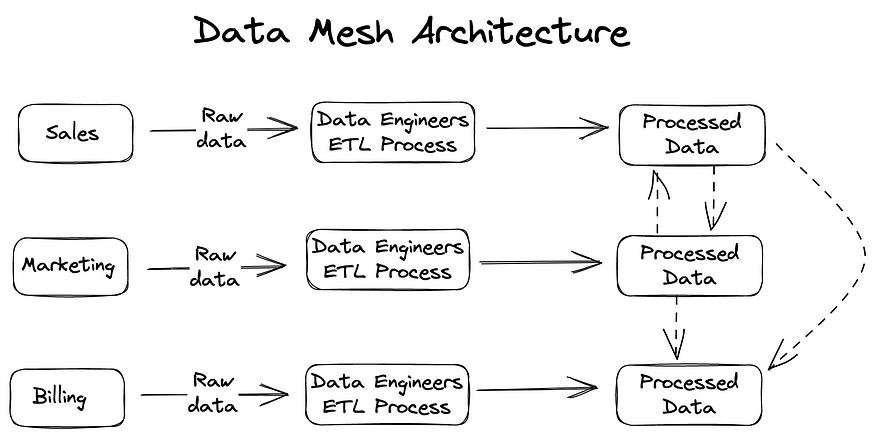
示例:例如,包括电子商务、营销、供应链和金融在内的多个业务部门的大型零售组织。在数据网格架构中,每个业务单元作为一个独立的数据领域运行,负责管理自己的数据资产。通过分散数据所有权和治理,可以优化各个领域的数据资产,满足其业务部门的具体需求,促进整个组织的信息共享和合作。
资料网格解决方案:
GoogleCloudBigQuery
AzureSynapseAnalytics
AWSS3andAthena
dbtandSnowflake
数据虚拟化意味着什么?
在过去的30年里,传统的数据结构一直很出色,但是随着行业信息量呈指数级增长,传统的复制数据的方法变得更加困难。
在这种情况下,数据虚拟化是为了允许浏览数据库而不需要获得集中存储。设计了一个抽象层,让用户可以通过API、相关元数据和目录获取数据,这有助于区分具体业务定义的数据。
另外,为了保证移动数据的安全性,中间件提供了治理和访问限制。
示例:辉瑞,世界领先的制药和生物技术公司(Pfizer)利用TIBCO数据虚拟化软件,加快向研究人员提供数据的速度。过去,该公司采用传统的ETL数据集成方法,往往导致数据过时。辉瑞通过数据虚拟化,成功缩短了50%的项目实施时间。该公司除快速检索和传输数据外,还对产品数据进行标准化,以确保所有研究和医疗单位产品信息的一致性。
数据编织是什么?
DataFabric是一种结构,旨在在集中存储中集成和安排不同的数据库、服务和应用程序,创建一个统一的生态系统。它基于数据虚拟化的概念,具有内置的人工智能和机器学习功能,以促进数据的投影和编程。
元数据是AI/ML算法支持的主动格式,建立知识图是为了找出不同数据元素之间的关系。DataOps将使用AI通过分析元数据来预测数据的摄入量和业务需求,DataOps将根据需求对数据进行管理和处理。
示例:Domino模型隐含地依赖于来自多个源的各种数据。Domino实施了数据编织,以集成和统一分布式数据。这种数据结构使Domino's能够在整个数据生命周期(从销售点系统到供应链中心和所有营销工作)中实现端到端的跟踪。
本文来自微信微信官方账号“数据驱动智能”(ID:Data作者:晓晓,36氪经授权发布,_0101)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com