
284毫瓦的LPU芯片:真能颠覆大模型推理吗?







本文来自微信公众号:歪睿老哥,作者:歪睿老哥
朋友们,今天来聊聊一款颇具争议的AI推理芯片。
一家韩国公司研发出了一款AI推理芯片,其功耗仅为284毫瓦。没错,不是284瓦,而是284毫瓦。就是这样一款低功耗芯片,却声称在LLM推理性能上超过了NVIDIA H100,能效比更是比H100高出33%。如果这是真的,那无疑是AI芯片领域的一大突破。今天我们就来深入分析这款名为LPU的芯片,看看它究竟是真材实料还是夸大其词。
1. 指甲盖千分之一大小的芯片,为何如此强悍?
先来看一组参数,绝对让你惊讶。
首先是LPU这个名字,它的全称是Latency Processing Unit(延迟处理单元),而非LLM Processing Unit(大语言模型专用处理器),不过它确实是用于处理LLM大语言模型推理的,只能说命名思路比较特别。
这款芯片的架构如下:
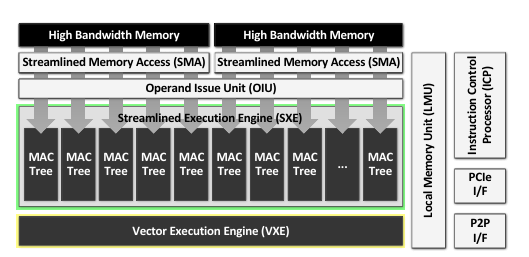
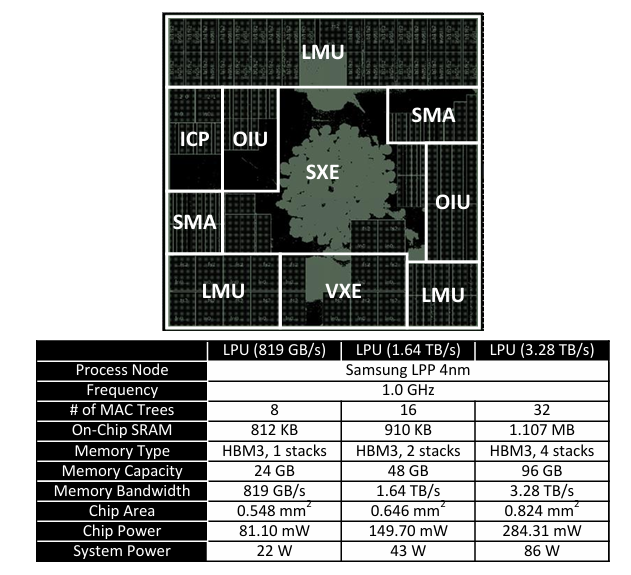
据研发团队介绍,该芯片采用三星4nm工艺制造,芯片面积仅0.824平方毫米。这是什么概念呢?我们的指甲盖大约有100平方毫米,这款芯片的面积还不到指甲盖的1%。它的功耗为284.31毫瓦,仅相当于手机充电器功率的零头。
就是这样一款“袖珍”芯片,性能却不容小觑。处理13亿(1.3B)参数的大模型时,每生成一个token仅需1.25毫秒;两颗LPU协同处理660亿参数的大模型时,每生成一个token的速度为20.9毫秒,比GPU快1.37到2.09倍。更关键的是,它的能效比H100高1.33倍,比L4高1.32倍。
要是在三年前,有人说284毫瓦的芯片能与1100瓦的H100抗衡,恐怕会被认为是天方夜谭。但HyperAccel公司确实进行了对比测试。
2. LPU的核心优势:高效、精准、协同
这款芯片之所以性能出色,与其独特的架构密不可分。
第一大优势:Streamlined Memory Access(SMA,流线型内存访问)
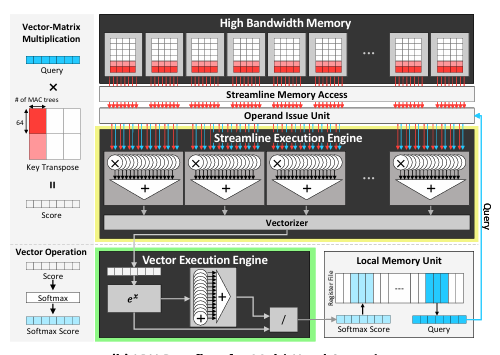
简单来说,就是对内存访问进行了专门优化。大模型推理的主要瓶颈并非算力不足,而是内存带宽。GPU效率低的原因在于,它是为并行计算设计的,拥有大量核心同时工作,但LLM推理的特点是每次只处理一个向量,完成后再处理下一个,导致GPU的多数核心处于闲置状态。
LPU则不同,它专为大模型推理设计了“流线型”内存访问机制,数据从HBM直接传输到计算单元,中间无需绕路,带宽利用率可达90%。而H100在处理小模型时带宽利用率仅为28.5%,处理大模型时也只有70%左右,差距明显。
第二大优势:Operand Issue Unit(OIU,操作数分发单元)
这个单元负责数据调度,就像一位智能管家,提前准备好计算所需的数据,一旦计算单元需要,就能立即提供,避免了等待时间。
第三大优势:Streamlined Execution Engine(SXE,流线型执行引擎)
这是LPU的计算核心,内置了大量定制的MAC树(乘加运算单元),专门用于处理向量乘矩阵的运算,而这正是大模型推理中最耗时的操作。LPU将这些MAC树排列得十分规整,数据流进来后能一路计算到底,中间不停顿,就像一条高效的生产线。
第四大优势:ESL(Expandable Synchronization Link,可扩展同步链路)
这是LPU的关键技术。运行大模型时,单颗芯片的内存往往不足,需要多颗芯片协同工作。多颗芯片之间如何通信呢?GPU采用NVLink,带宽达900GB/s,看似很快,但通信时计算必须停止等待,导致效率下降。双GPU的加速比平均只有1.38倍,四GPU的加速比更低。
LPU的ESL技术则不同,它能隐藏通信延迟,实现通信与计算的重叠进行。因此,双LPU的加速比能达到1.75倍,接近理论极限的2倍。
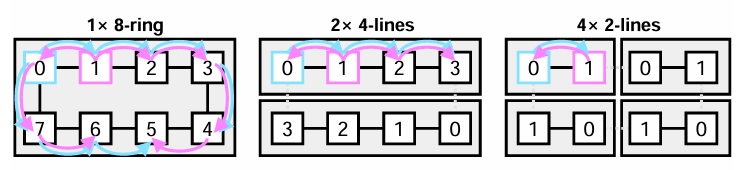
这种可扩展性,连GPU都望尘莫及。
3. 软件生态:HyperDex让使用更便捷
硬件性能再强,如果软件不好用也难以推广。HyperAccel公司开发了名为HyperDex的软件框架,功能十分全面:
它支持自动编译,能根据模型参数生成内存映射和指令;同时支持HuggingFace API,主流的LLM模型都能在上面运行。这对开发者来说是个好消息,无需重新学习一套全新的工具。
不过,新架构的生态建设是一个长期过程。NVIDIA的CUDA生态已经发展了十几年,护城河十分深厚。LPU要想撼动NVIDIA的地位,仅靠性能优势还不够,还需要吸引更多开发者和厂商加入。
4. LPU能超越NVIDIA吗?还需冷静看待
看到这里,你可能会问:LPU真的这么厉害吗?
需要明确的是,这只是一款原型芯片。
首先,它是原型专用芯片,而非通用芯片。LPU只能用于大模型推理,无法完成其他任务;而GPU则能兼顾训练、推理、游戏、挖矿等多种用途,应用场景完全不同。
其次,论文数据与量产实际情况存在差异。论文中的数据是在理想条件下测试得到的,而真实场景中模型类型多样、请求复杂,能否保持这样的效率还不确定。
最后,生态差距巨大。NVIDIA拥有CUDA、TensorRT以及众多优化库,而LPU目前还只是一个新入局者。
不过,专用芯片在特定领域超越通用芯片的情况并非没有先例。比如比特币挖矿,最初使用GPU,后来专用ASIC芯片出现后,GPU就被淘汰了。大模型推理是否会走同样的道路呢?可能性很大。毕竟推理任务相对固定,不像训练那么复杂。如果专用芯片能降低成本和功耗,云厂商没有理由不采用。
5. 对我们的影响:端侧AI推理或迎爆发
作为普通用户,你可能觉得这与自己无关,但事实并非如此。
端侧推理AI芯片可能会迎来爆发。284毫瓦的功耗,在手机上也能使用。未来,我们的手机或许能本地运行大模型,无需联网,这样隐私、延迟、费用等问题都能得到解决。
不过,目前存储仍是瓶颈。这款284毫瓦的芯片使用了FPGA原型上的HBM来存储数据,就像一辆摩托车拉着一个大油罐。但这也说明,当前大模型推理芯片的瓶颈更多在存储,而非计算。
6. 总结
LPU芯片让我们看到了专用AI芯片的潜力,在特定场景下,专用架构确实能比通用架构高效得多。但要说它能颠覆NVIDIA,现在还为时过早,毕竟生态建设不是一蹴而就的。
不过可以确定的是,AI推理芯片领域的竞争会越来越激烈。除了LPU,还有Gorq、SambaNova、Tenstorrent、Taalas等众多参与者,未来会有更多架构加入这场竞争。
你认为专用AI推理芯片能撼动NVIDIA的地位吗?
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com