
GPU垄断松动,非GPU芯片势力崛起重塑全球算力格局






芯东西12月17日报道,上海GPU龙头沐曦股份在上交所科创板敲钟,开盘价700.00元/股,截至午间休市股价大涨687.79%,总市值达3298.82亿元,将全球算力产业竞争推向新高度。
近期,全球算力产业处于重磅事件密集爆发期。
海外方面,非GPU赛道的谷歌TPU斩获千亿级订单,在GPU垄断的算力市场撕开缺口。上周博通CEO透露,Anthropic向博通下达总计210亿美元(折合人民币约1486亿元)的订单,Meta等科技巨头也有采购意向;GPU领域,因担忧失去中国市场,美国批准英伟达H200 AI芯片对华出售。
国内算力产业热度同样攀升,北京AI芯片企业清微智能拿下超20亿元大额融资,投资阵容业内少见。此外,国内AI芯片创企密集披露并购、上市计划,本土算力生态加速成型。
海内外算力产业的密集动向,共同指向不可逆的行业变革:全球算力市场长期由英伟达GPU垄断的格局正在松动。
大模型发展初期,市场对通用算力的强需求让英伟达GPU迅速占据绝对主导地位,几乎形成“无GPU不训练”的局面。
如今,一方面谷歌TPU、亚马逊Trainium3等非GPU芯片在部分场景实现对GPU的规模化替代,国内市场2025年上半年非GPU算力卡占比已达30%,寒武纪MLU、昆仑芯ASIC、清微智能可重构芯片(RPU)等产品形成差异化优势;另一方面,投资市场中,英特尔拟以16亿美元(约合人民币112.9亿元,含债务)收购非GPU路线AI芯片独角兽SambaNova,非GPU路线独角兽Groq两年间拿下超30亿美元(折合人民币约213亿元)融资。
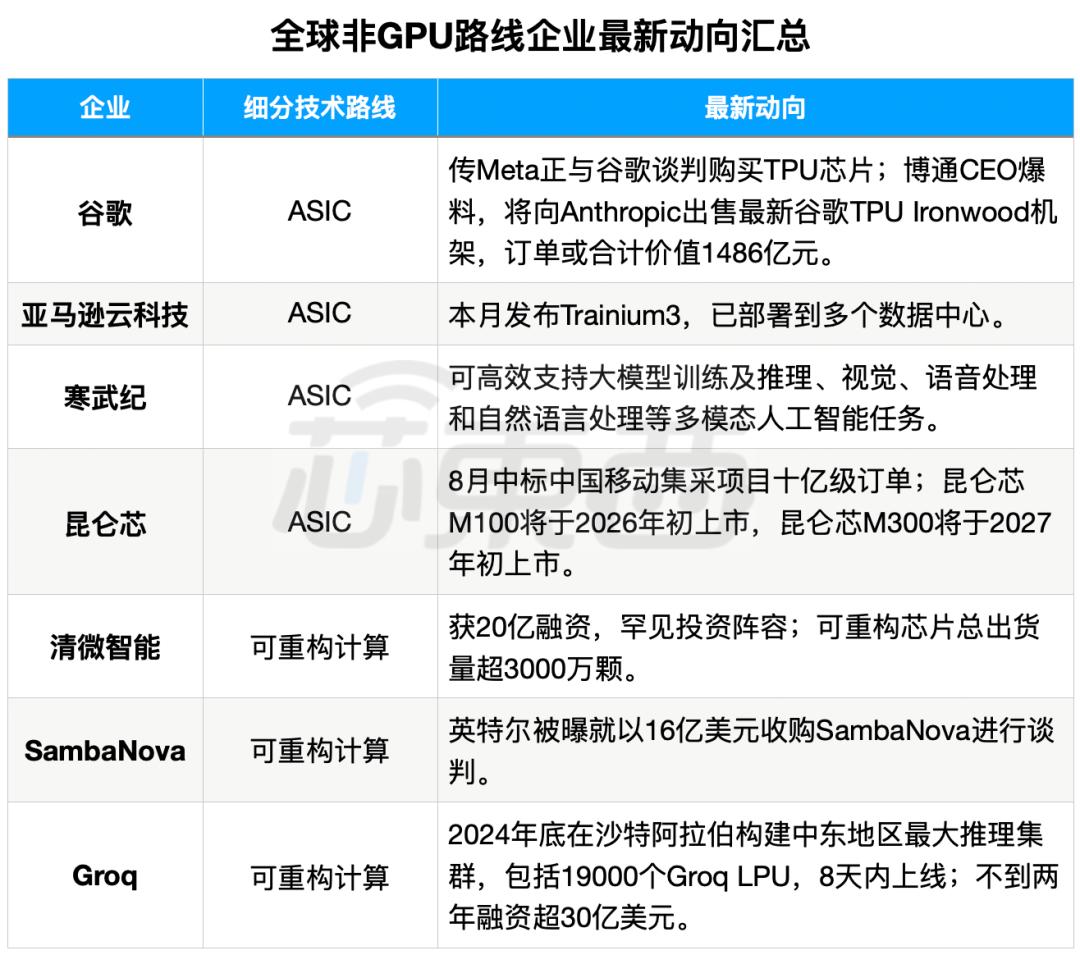
▲海外非GPU路线企业最新动向汇总
可见,非GPU芯片势力崛起已势不可挡。在此背景下,全球算力产业下一步走向何方?非GPU路线市场空间有多大?未来会百花齐放还是一枝独秀?非GPU赛道哪条路线有望率先突围?通过拆解全球算力格局及国内头部企业技术路线,可探寻这些问题的答案。
01 全球算力产业下一程:路径分化成必然
从需求端、底层技术、全球算力生态构建三个核心维度看,全球算力产业格局变革具有必要性与急迫性。
需求端,今年是大模型落地元年,推理场景算力需求增加,单纯堆砌GPU的粗放模式难以适配大模型规模化落地需求,倒逼企业寻找更高效的算力解决方案。同时,AI深入千行百业催生多元细分需求,如AI视频生成、AI医疗诊断、工业数字孪生等场景对算力能效比、适配性要求各异。叠加企业分散供应链风险、规避单一厂商依赖的需求,非GPU算力产品迎来关键市场切入契机。
技术端,传统冯·诺依曼架构的存算分离矛盾凸显,设计逻辑难以突破硬件性能物理边界,需架构革新破局。非GPU路线实现多点突破,如谷歌TPU专用架构、国产可重构芯片的动态适配能力等,在特定场景形成性能与成本优势。
生态层面,打破单一架构生态垄断成为行业共识,国产开源框架通过兼容适配、自主优化,快速构建本土生态协同体系。
因此,全球算力产业正朝着打破单一架构、不同路径百花齐放的方向发展。
近日新华社报道提到:“在AI芯片领域,北京已形成自主可控的‘芯片矩阵’,昆仑芯、寒武纪、摩尔线程、清微智能……一系列国产明星产品性能领先。”其中,摩尔线程属GPU路线,昆仑芯、寒武纪属非GPU中的ASIC路线,清微智能属非GPU中的可重构计算路线。四家企业分属不同技术路线的发展态势,印证了北京在AI芯片赛道多元布局、保障供应链安全的远见。
行业趋势背后,驱动发展的核心趋势有三:一是GPU与非GPU两大技术路线并行发展,GPU凭借成熟生态兼容性和通用计算能力,在兼顾图形渲染、科学计算与AI训练的场景持续发挥优势;非GPU路线在AI推理领域率先展现强劲增长潜力,其中可重构架构凭借通用计算能力,在AI主流场景占据重要地位。二是全球算力产业重心从唯硬件性能论转向软件、模型、场景适配等全栈布局,通过协同创新释放算力资源,针对不同硬件架构对模型进行压缩、量化、适配,实现算力效能最大化。三是中国厂商话语权提升,在算力领域长期由欧美厂商主导的格局下,中国企业在非GPU赛道展现出不容小觑的竞争力。综上,全球算力产业下一程必然走向路径分化。
02 非GPU路线市场稳步上升,国内渗透率领先全球
全球知名市研机构Gartner预计,到2027年,针对AI推理应用的算力需求将使AI加速器(通常指非GPU的AI专用芯片)出货量超越GPU。同时,非GPU路线正快速成长为与GPU分庭抗礼的核心力量,算力市场双轨并行格局雏形初现。
IDC报告显示,今年上半年中国非GPU芯片市场在加速计算领域增长显著。2025年上半年,中国非GPU服务器市场占比约30%,预计2028年将接近50%。
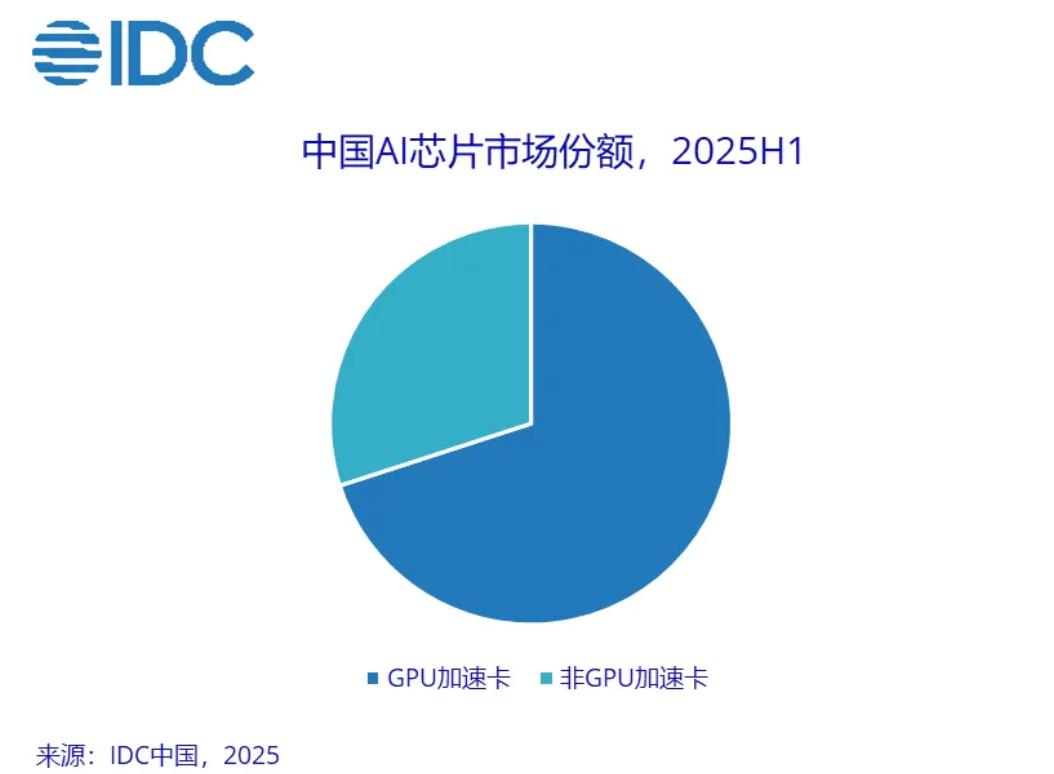
AI在千行百业的加速渗透极大推动了这一趋势。英伟达创始人、CEO黄仁勋曾透露,中国AI应用发展速度极快,社会接纳新技术节奏快,这场工业革命的胜负取决于AI应用普及程度。
相比于GPU,非GPU技术路线在成本、能效比、场景适配性上更契合当下AI主流应用场景。其硬件采购与运维成本更低,适配中小企业及大规模分布式部署需求;通过定制化架构实现低功耗与高精度平衡,能效比更优;适配自动驾驶、工业物联网等边缘端场景算力需求;具备更强实时性、稳定性与灵活性,适配差异化AI任务。
尤其在智算中心、大模型部署、云计算、泛机器人、智能驾驶等主流AI应用场景中,非GPU路线有适配特定负载的高能效比、更低全生命周期成本、更强国产供应链自主可控性,能通过定制化架构实现大模型推理高吞吐与低延迟,兼容多业务负载。对于千亿乃至万亿级规模的AI市场,非GPU方案必然占据一席之地。
不过,非GPU发展尚不成熟,大部分非GPU芯片生态成熟度不足,缺乏完善的软件工具链和丰富的开源框架支持。且发展处于早期,对企业早期研发投入能力考验较大。这也印证了GPU与非GPU两条技术路径各有优劣,并非简单替代关系。
03 国内头部芯片企业布局拆解:可重构赛道势头强劲
探究国内非GPU赛道发展格局,可聚焦几家核心企业。北京AI产业具有代表性,2024年其AI核心产业规模近3500亿元,占全国近一半,底层芯片玩家是关键。新华社报道提到的昆仑芯、寒武纪、摩尔线程、清微智能四家北京芯片代表企业,是国内AI产业蓬勃发展的缩影,透过其发展轨迹可窥见国内AI芯片产业格局的深刻变革。
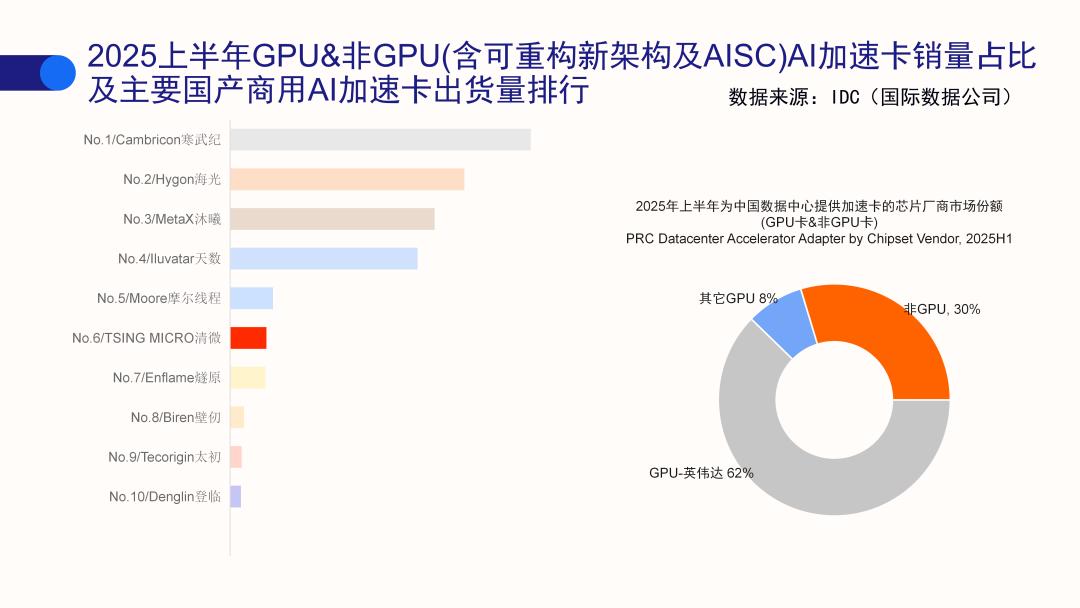
▲北京四家芯片代表企业2025年上半年出货量位居国内前列
四家企业中,摩尔线程属GPU阵营,其余三家为非GPU阵营,寒武纪、昆仑芯主攻ASIC路线,清微智能以可重构架构实现通用计算为核心发力方向。这几家受北京市认可的企业极具代表性,展现了国产非GPU的布局脉络,也凸显了政府层面的有力支持。
ASIC架构是为特定用途定制设计的集成电路,谷歌TPU就是ASIC芯片。ASIC最核心的优势是性能、功耗,加上支持深度定制的特性,使其在AI应用浪潮中大展拳脚。
寒武纪的ASIC芯片采用自研架构,构建了覆盖云端、边缘端和终端的完整产品线。其首款采用Chiplet技术的芯片思元370,最大算力高达256TOPS(INT8),是第二代产品思元270算力的2倍。
昆仑芯基于自研XPU架构,昆仑芯R200可提供高达256 TOPS(INT8)和128 TFLOPS FP16的算力,性能可达主流GPU的1.5倍。实际部署中,单机4卡R200方案可实现4800 tokens/s的推理吞吐量,满足千亿参数大模型的实时交互需求。
这些实例印证了AI领域中非GPU架构对GPU的规模化替代进程已全面开启。不过,ASIC也有不足,因需定制化,从需求定义到量产交付的每个环节都需投入大量时间与资源;且架构一旦固化便难以调整,面对算法快速迭代的场景,往往需要重新流片,进一步拉高研发风险与周期成本。
相比之下,兼容GPU、ASIC路线优势的可重构计算路线发展势头更猛,核心在于它踩中了AI产业从算力集中到场景细分转型的行业趋势,解决了GPU通用但低效、ASIC高效但硬件固化的痛点,通过底层架构创新实现了性能与性价比的平衡,相比行业同类型产品成本整体降低50%、能效比提升3倍。截至今年12月,清微智能的可重构芯片累计出货量已超3000万颗,2025年其算力卡订单累计超3万张,在全国十余座千卡规模智算中心实现规模化落地。

▲清微智能AI算力芯片TX81
此外,可重构数据流技术路线与AI计算需求天然适配。在芯片高效互联核心环节,可重构数据流派自研的TSM-LINK算力网格技术支持多芯片点对点直连,实现数据高效传输,从根源上规避传统交换机架构的带宽瓶颈与通信延迟问题;而GPU架构在适配晶圆级芯片集成时,只能依赖外部交换机完成互联,性能损耗与延迟问题难以避免。
在芯片设计层面,可重构数据流架构从底层设计阶段就具备三维扩展的天然优势,能与晶圆级芯片技术、3.5D堆叠等先进立体封装技术深度结合,形成清晰且可持续的升级迭代路径。据悉,清微智能明年推出的下一代芯片性能将大幅跃升,有望实现对国际主流前沿AI芯片的弯道超车。

▲GPU与非GPU技术路线基本性能对比
本质上,可重构计算路线不是对GPU、ASIC的替代,而是通过找到两者的平衡,取所长,契合了AI规模化落地的核心需求。
04 结语:算力产业进入多元共生新时代
当前AI算力领域格局已较为清晰:GPU凭借成熟生态与极致并行计算能力,在通用大模型训练、图形渲染等核心场景仍占据不可撼动的地位,但面临功耗攀升、成本高的结构性挑战;非GPU路线凭借更高能效比、更低全生命周期成本及自主可控优势,在AI推理、专用算力需求等主流AI应用领域快速崛起,共同推动算力体系向多元化、异构融合方向演进。
以大模型、生成式AI为代表的新一轮AI浪潮催生出前所未有的AI算力需求,国产大模型企业强势突围,带动国内AI算力需求持续增长,中国AI算力产业迎来新机遇与挑战。
当下,国产非GPU企业异军突起,正与国内大模型厂商形成合力,为国内AI算力产业注入新活力。尽管非GPU技术路线相比GPU尚不成熟,但因其天然优势与AI应用落地相契合,正迸发出强大生命力。
本文来自微信公众号“芯东西”,作者:程茜,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com