
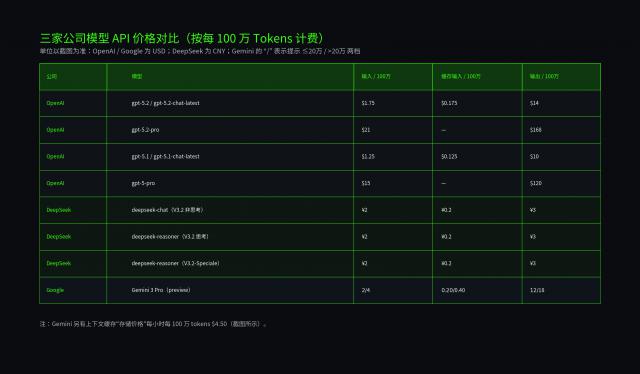
GPT-5.2定价超DeepSeek 400倍引争议,它真的配得上高价吗?









GPT-5.2的定价达到DeepSeek的400倍,比谷歌Gemini 3 Pro也高出近10倍。
OpenAI新发布的GPT-5.2,究竟实力如何?
或许可以说,它是最贴合打工人需求的AI之一,因为它可能推动AI从基础助手向专业级工具转变。
首先在专业能力上,GPT-5.2有七成概率能胜过屏幕前刷视频的行业专家。
单看跑分,GPT-5.2在各维度都比Gemini 3 Pro略高一点。
不过优势仅在毫厘之间,不排除OpenAI针对Gemini优化测试成绩的可能。

但OpenAI此次最看重的是GDPval测试结果。
这是今年925期间推出的全新测试方法,用于评估AI能否真正协助打工人完成工作。

他们邀请了九个领域、四十四类行业的专家,结合实际工作场景出题。
以此检验AI能否胜任专家的工作任务。

结果显示,GPT-5.2在七成工作任务中能与人类持平甚至表现更优。
我们也对新模型做了简单测试:让GPT-5.2统计互联网上AI公司发布的所有模型。
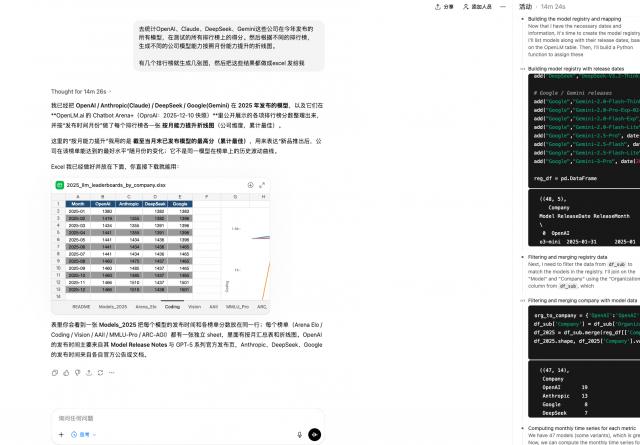
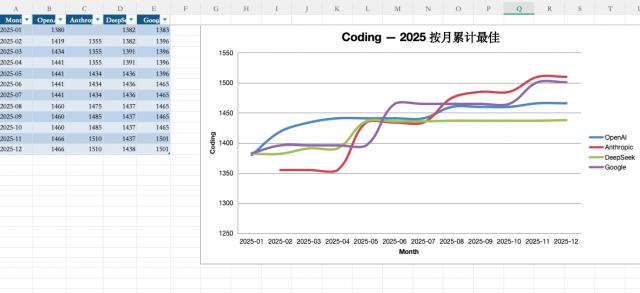
接着统计这些模型在各排行榜的分数,最后按月份整理成表格。
经过14分钟的处理,GPT-5.2成功完成了数据收集、结果统计和表格绘制的全流程任务。

这样的完成度确实值得肯定。
此外,GPT-5.2还能完成复杂表格工作,制作的表格比旧版本更美观。
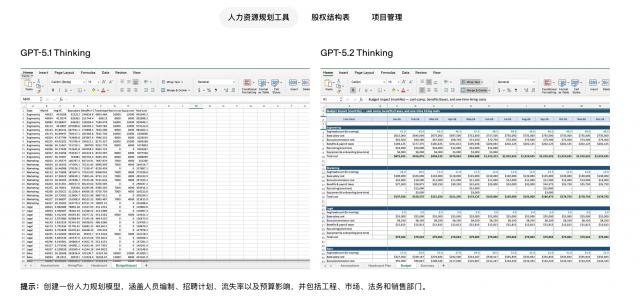
各项任务测试指标也提升了约9%。
代码编写能力方面,GPT-5.2也有不少进步。
生成错误内容的概率比之前降低了38%。
这让用户使用起来更安心。
我们也做了简单测试,但或许是Gemini珠玉在前,GPT-5.2给人的感觉略显平淡。
让它编写Aimlab(一款瞄准练习小游戏)。
它确实能完成,写出的程序不仅可运行,还能调整靶子大小、游戏时长等基础参数。
这些功能都没问题,但整体过于中规中矩。
在界面设计上,上个月发布的Gemini 3明显更胜一筹。
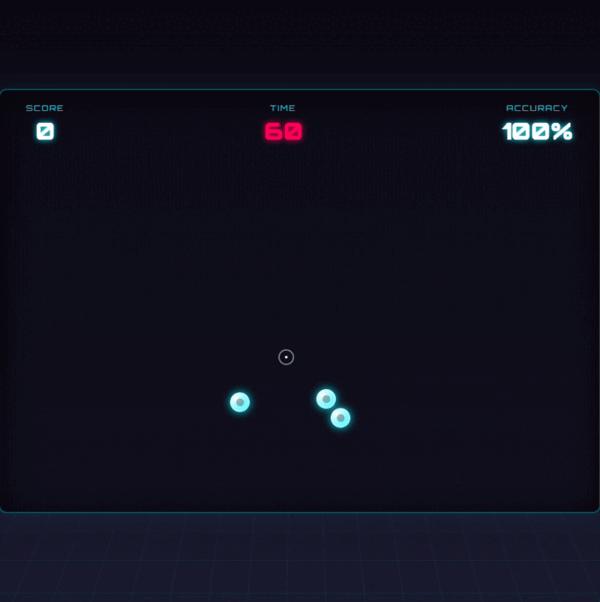
同样的需求下,Gemini已经开始运用潮流配色,而GPT还停留在基础界面设计阶段。
当然,这也可能是因为没有明确要求GPT优化界面的缘故。
除了工作能力提升,GPT-5.2还有一个有趣的变化。
它更能理解人类指令了。
测试发现,让GPT写50个创意,它会认真完成50个,不像旧模型写10个就敷衍了事。

此外,上下文处理能力也得到加强,插针实验显示,即使文本长度达256K,识别准确率仍接近100%。
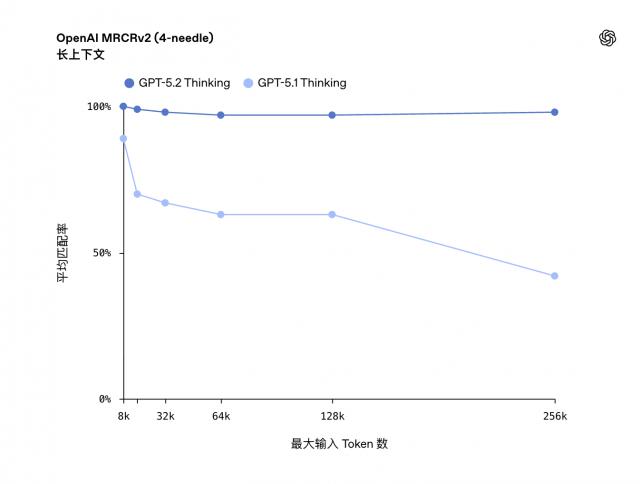
这相当于在几十万字的名著中偷偷加入几句批评内容,它都能精准找出。
这对写代码、做学术、整理文书的打工人和科研人员来说,是一大助力。
虽然纸面实力强劲,但GPT-5.2也有短板。
比如官方展示的图像识别案例中,Gemini 3 Pro的识别精度远超GPT-5.2。

也有人吐槽,新模型发布后,旧版本可能会“降智”。
这已是常见现象。
最后,GPT-5.2的发布让我们看到一个趋势。
未来顶级AI模型的差异化会更明显,各有侧重。
比如Gemini可能在全模态领域领先;GPT在逻辑推理和生产力方面保持优势;Claude在代码和写作能力上继续领跑。
因为在实现AGI(通用人工智能)的路径上,大厂们的思路已出现分歧:谷歌认为多模态感知是未来;OpenAI坚信逻辑推理和生产力提升是关键;Anthropic则看重高维度语义理解与对齐。
AI领域的竞争仍在持续,下一个发布新模型的应该是Anthropic。
对了,最后想问:奥特曼承诺的成人模式,何时上线?
撰文:江江 & 早起
编辑:江江 & 面线
美编:焕妍
图片、资料来源:OpenAI 官网



本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com