
DeepSeek低调开源LPLB:借线性规划化解MoE负载不均难题
2025-11-22





昨天,DeepSeek在GitHub上线了一个新的代码库:LPLB。
它没有发推文,也没有公众号更新,少有的几个技术博主分享的推文关注量也不多。截至目前,该项目的star数量还没超过200。
但仔细探究,这个项目似乎并不简单,值得更多关注。X网友gm8xx8评论认为这表明DeepSeek正在解决正确性和吞吐量瓶颈问题,为下一版模型发布做准备。
顾名思义,LPLB是一个并行负载均衡器,它利用线性规划(Linear Programming)算法来优化MoE(混合专家)模型中的专家并行工作负载分配。
具体而言,LPLB通过以下三个步骤实现动态负载均衡:
动态重排序:基于工作负载统计信息对专家进行重排序(Reordering)。
构建副本:结合静态拓扑结构构建专家副本(Replicas)。
求解最优分配:针对每个批次(Batch)的数据,求解最优的Token分配方案。
更详细地说,LPLB的专家重排序过程由EPLB协助完成。而实时工作负载统计信息可以由用户提供、通过torch.distributed收集,或直接从Deep - EP缓冲区的内部通信器中获取。至于求解器,则使用了内置的LP(线性规划)求解器,其实现了单SM(Streaming Multiprocessor)内点法(IPM),并利用了NVIDIA的cuSolverDx和cuBLASDx库进行高效的线性代数运算。
这样一来,MoE负载不均的问题能得到有效解决。在MoE模型中,某些「专家」可能比其他专家接收到更多的Token,导致某些GPU忙碌而其他GPU空闲。
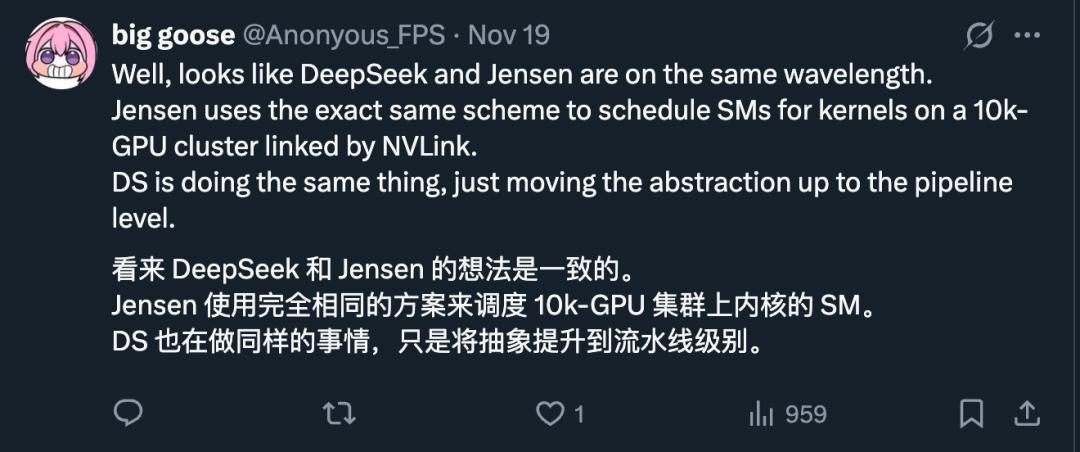
X网友big goose指出这与英伟达的用于调度SM (Streaming Multiprocessor,是英伟达GPU的核心计算单元) 的方案非常相似,只是将抽象提升到了pipeline层级。LPLB强调「单SM」,意味着它的求解过程非常轻量化,不会占用过多计算资源。
EPLB vs. LPLB
EPLB:主要处理静态不均衡(例如,由于数据分布特性,某些专家总是长期过载)。
LPLB:专注于处理动态波动(由训练过程中小批次数据的随机性引起的瞬时负载抖动)。
核心机制
冗余专家 (Redundant Experts):每个冗余专家(副本)都链接到一个原始专家,从而在GPU之间形成连接边。
边容量 (Edge Capacity):一条边的容量定义为当前批次中分配给该冗余专家的Token数量,这决定了用于平衡负载的最大Token流量。
LP优化 (LP Optimization):LPLB求解一个线性规划问题,在遵守边容量限制的前提下,沿着这些边重新分配Token,以最小化专家并行(EP)组内的负载不均衡。
然后根据选定的LPLB拓扑结构,复制负载最重的专家。
通信优化:实时工作负载的同步使用NVLINK和NVSHMEM进行优化,替代了传统的torch.distributed.allreduce,从而大幅降低通信开销。这正是需要预装DeepEP的原因。
忽略非线性计算成本:当前的规划器仅平衡Token总数,未考虑分组矩阵乘法(Grouped GEMM)时间成本的非线性特征。这可能导致在某些情况下性能并非绝对最优。
求解延迟:求解器在节点内(intra - node)优化大约需要100 µs(跨节点时间更长)。对于非常小的Batch Size,这个延迟可能不可忽略。
极端不均衡情况:在全局负载极端不均衡的情况下,LPLB的表现可能不如EPLB。这是因为LPLB在分配冗余专家时存在差异(LPLB避免将多个副本分配给同一个原始专家)。
立方体 (Cube):在GPU子集上复制专家,形成带有对角边的立方体图。这要求每个GPU至少2个专家。适用场景:适合在8 GPU的EP子组内进行平衡,且不会牺牲跨节点通信性能。
超立方体 (Hypercube):类似于Cube,但不包含对角边。这需要16个GPU。适用场景:适合跨16个GPU的专家并行。
环面 (Torus):在同一节点内的邻居GPU上复制一个专家,在邻节点的GPU上复制另一个专家,形成环面图。其要求每个GPU至少2个专家。优缺点:对全局平衡有效,但由于涉及更多的节点内通信,效率通常低于Cube。
它的创新点在于引入了线性规划这一数学工具来实时计算最优分配,并利用底层的NVSHMEM技术来打破通信瓶颈。对于正在研究MoE架构训练加速的开发者来说,这是一个非常有价值的参考实现。
具体的安装和测试指南请访问原代码库。
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:机器之心,36氪经授权发布。
它没有发推文,也没有公众号更新,少有的几个技术博主分享的推文关注量也不多。截至目前,该项目的star数量还没超过200。
但仔细探究,这个项目似乎并不简单,值得更多关注。X网友gm8xx8评论认为这表明DeepSeek正在解决正确性和吞吐量瓶颈问题,为下一版模型发布做准备。

项目简介
LPLB,全称Linear-Programming-Based Load Balancer,即基于线性规划的负载均衡器。顾名思义,LPLB是一个并行负载均衡器,它利用线性规划(Linear Programming)算法来优化MoE(混合专家)模型中的专家并行工作负载分配。
具体而言,LPLB通过以下三个步骤实现动态负载均衡:
动态重排序:基于工作负载统计信息对专家进行重排序(Reordering)。
构建副本:结合静态拓扑结构构建专家副本(Replicas)。
求解最优分配:针对每个批次(Batch)的数据,求解最优的Token分配方案。
更详细地说,LPLB的专家重排序过程由EPLB协助完成。而实时工作负载统计信息可以由用户提供、通过torch.distributed收集,或直接从Deep - EP缓冲区的内部通信器中获取。至于求解器,则使用了内置的LP(线性规划)求解器,其实现了单SM(Streaming Multiprocessor)内点法(IPM),并利用了NVIDIA的cuSolverDx和cuBLASDx库进行高效的线性代数运算。
这样一来,MoE负载不均的问题能得到有效解决。在MoE模型中,某些「专家」可能比其他专家接收到更多的Token,导致某些GPU忙碌而其他GPU空闲。
X网友big goose指出这与英伟达的用于调度SM (Streaming Multiprocessor,是英伟达GPU的核心计算单元) 的方案非常相似,只是将抽象提升到了pipeline层级。LPLB强调「单SM」,意味着它的求解过程非常轻量化,不会占用过多计算资源。
LPLB的工作原理
LPLB是在EPLB(专家并行负载均衡器)基础上的扩展,旨在解决MoE训练中的动态负载不均衡问题。EPLB vs. LPLB
EPLB:主要处理静态不均衡(例如,由于数据分布特性,某些专家总是长期过载)。
LPLB:专注于处理动态波动(由训练过程中小批次数据的随机性引起的瞬时负载抖动)。
核心机制
冗余专家 (Redundant Experts):每个冗余专家(副本)都链接到一个原始专家,从而在GPU之间形成连接边。
边容量 (Edge Capacity):一条边的容量定义为当前批次中分配给该冗余专家的Token数量,这决定了用于平衡负载的最大Token流量。
LP优化 (LP Optimization):LPLB求解一个线性规划问题,在遵守边容量限制的前提下,沿着这些边重新分配Token,以最小化专家并行(EP)组内的负载不均衡。
实现流程
首先通过EPLB选择需要复制的专家(仅重排序,此时未复制)。然后根据选定的LPLB拓扑结构,复制负载最重的专家。
通信优化:实时工作负载的同步使用NVLINK和NVSHMEM进行优化,替代了传统的torch.distributed.allreduce,从而大幅降低通信开销。这正是需要预装DeepEP的原因。
局限性
尽管LPLB提供了动态优化,但目前仍存在一些局限:忽略非线性计算成本:当前的规划器仅平衡Token总数,未考虑分组矩阵乘法(Grouped GEMM)时间成本的非线性特征。这可能导致在某些情况下性能并非绝对最优。
求解延迟:求解器在节点内(intra - node)优化大约需要100 µs(跨节点时间更长)。对于非常小的Batch Size,这个延迟可能不可忽略。
极端不均衡情况:在全局负载极端不均衡的情况下,LPLB的表现可能不如EPLB。这是因为LPLB在分配冗余专家时存在差异(LPLB避免将多个副本分配给同一个原始专家)。
典型拓扑结构
LPLB允许通过修改r2o矩阵来定义专家副本的分布方式。以下是几种典型的拓扑:立方体 (Cube):在GPU子集上复制专家,形成带有对角边的立方体图。这要求每个GPU至少2个专家。适用场景:适合在8 GPU的EP子组内进行平衡,且不会牺牲跨节点通信性能。
超立方体 (Hypercube):类似于Cube,但不包含对角边。这需要16个GPU。适用场景:适合跨16个GPU的专家并行。
环面 (Torus):在同一节点内的邻居GPU上复制一个专家,在邻节点的GPU上复制另一个专家,形成环面图。其要求每个GPU至少2个专家。优缺点:对全局平衡有效,但由于涉及更多的节点内通信,效率通常低于Cube。
结语
DeepSeek开源的这个LPLB库,本质上是在试图解决大模型训练中「木桶效应」的问题,即训练速度往往取决于最慢(负载最重)的那个GPU。它的创新点在于引入了线性规划这一数学工具来实时计算最优分配,并利用底层的NVSHMEM技术来打破通信瓶颈。对于正在研究MoE架构训练加速的开发者来说,这是一个非常有价值的参考实现。
具体的安装和测试指南请访问原代码库。
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:机器之心,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com