
苹果展示M5芯片AI性能:文本生成较M4最高提速27%





IT之家11月21日消息,苹果机器学习研究博客于11月19日发布文章,公布了M5芯片的最新性能数据,着重展示了其在运行本地大语言模型(LLM)方面的突出优势。
此次性能评估的核心平台是苹果之前推出的MLX,它是专为Apple Silicon设计的开源机器学习框架,借助统一内存架构,使模型能在CPU和GPU之间高效运行。
在关键的文本生成测试中,苹果运用MLX LM工具包对多款开源大模型进行了基准测试,涵盖不同参数规模的Qwen模型和GPT OSS模型。
测试结果表明,M5芯片在生成后续文本token时的速度比M4提高了19%至27%。苹果表示,这一性能提升主要得益于内存带宽的增加,M5的内存带宽高达153GB/s,相较于M4的120GB/s提升了28%,这对内存密集型的token生成任务十分关键。
报告进一步说明了LLM推理过程中的两种不同负载。IT之家援引文章介绍,生成第一个token主要受计算能力限制,而生成后续token则更依赖于内存速度。
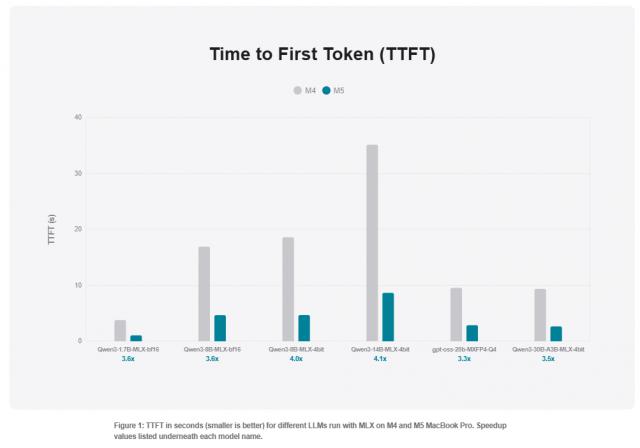
所以,M5凭借更高的内存带宽,在持续生成文本的场景中优势明显。苹果还强调,配备24GB内存的MacBook Pro能够轻松运行参数量达300亿的4 - bit量化混合专家模型(MoE),并将推理负载控制在18GB以内。
第一个tokens生成速度 后续tokens生成速度 内存 (GB) Qwen3 - 1.7B - MLX - bf16 3.57 1.27 4.40
Qwen3 - 8B - MLX - bf16
3.62 1.24 17.46
Qwen3 - 8B - MLX - 4bit
3.97 1.24 5.61
Qwen3 - 14B - MLX - 4bit
4.06 1.19 9.16
gpt - oss - 20b - MXFP4 - Q4
3.33 1.24 12.08
Qwen3 - 30B - A3B - MLX - 4bit
3.52 1.25 17.31
除了文本处理能力,M5芯片在图像生成方面的提升更为显著。报告指出,M5芯片中集成了全新的GPU神经加速器,专门用于处理机器学习负载中重要的矩阵乘法运算。
得益于这一硬件升级,M5芯片执行图像生成任务的速度是M4芯片的3.8倍以上。这一巨大提升意味着,未来搭载M5芯片的Mac设备将在创意设计、内容生成等视觉AI应用领域带来远超以往的流畅体验。

本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com