
清华团队“密度法则”登Nature子刊,大模型每百天性能翻倍
2025-11-21





2020年以来,OpenAI提出的Scaling Law推动着大模型快速发展,其理念是模型参数和训练数据规模越大,智能能力越强。但到了2025年,这种不断扩增训练开销的发展路径面临可持续发展难题。OpenAI前首席科学家Ilya Sutskever指出,随着互联网公开语料接近枯竭,大模型预训练将难以为继。于是,众多研究者开始探寻大模型新的发展方向。
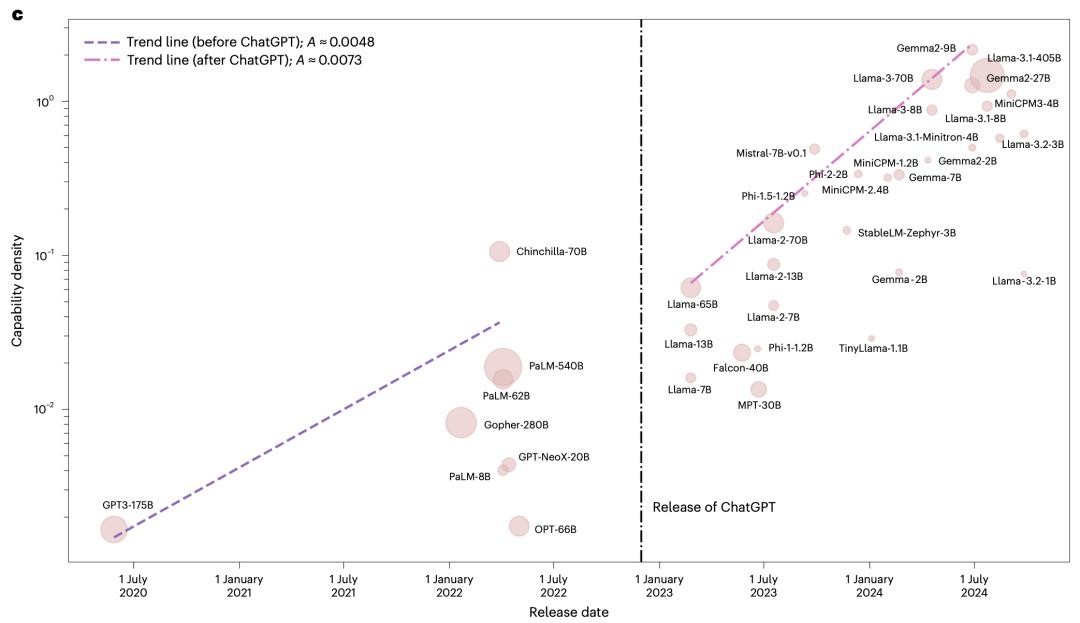
清华大学研究成果大模型“密度法则”(Densing Law)带来了新视角。近日,该成果发表于Nature子刊《自然·机器智能》(Nature Machine Intelligence),为理解大模型发展规律提供了新维度。密度法则显示,大语言模型的最大能力密度随时间呈指数级增长,在2023年2月至2025年4月期间,约每3.5个月翻一倍,这意味着每隔3.5个月,就能用参数量减半的模型实现当前最优性能。
论文链接:https://www.nature.com/articles/s42256-025-01137-0
回顾计算机发展历程,在摩尔定律的指引下,半导体行业不断改进制造工艺、提高芯片电路密度,使计算设备从重达27吨的ENIAC发展到仅数百克的智能手机,实现了算力普惠和信息革命。如今,全球有13亿台个人电脑、70亿部智能手机、180亿台IoT设备和2000亿颗运行中的CPU。摩尔定律的关键不是增大芯片尺寸,而是提升电路密度,即单位面积容纳更多计算单元。
受此启发,研究团队提出:可以从“能力密度”角度观察和理解大模型发展。如同芯片行业通过提升电路密度实现计算设备小型化和普惠化,大模型也能通过提升能力密度实现高效发展。
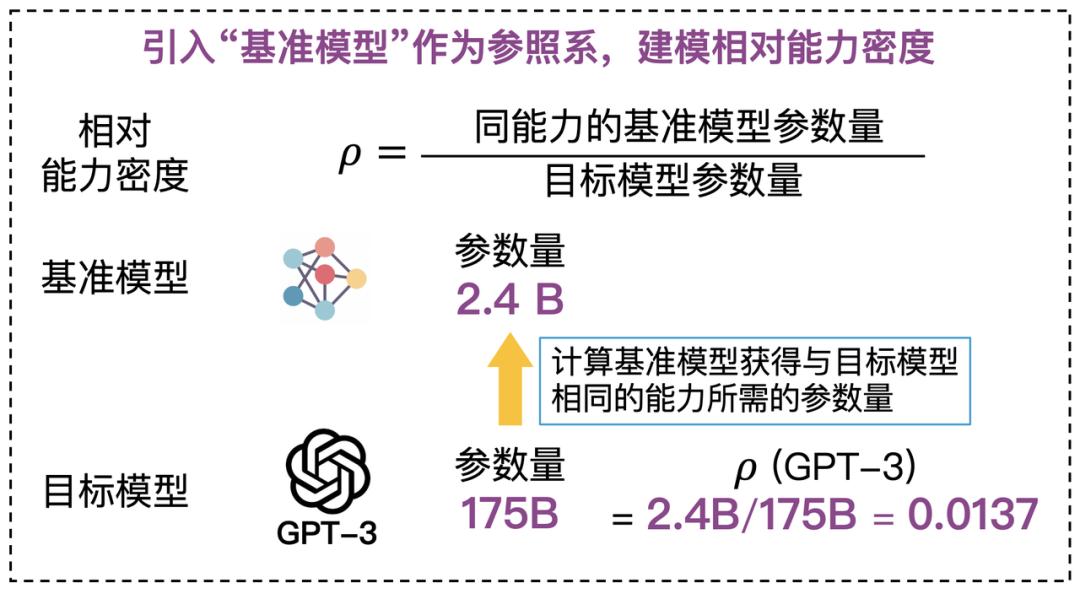
研究团队基于一个核心假设:采用相同制造工艺、充分训练的不同尺寸模型,其能力密度相同。在此基础上,选取基准模型并设定其密度为1,作为衡量其他模型能力密度的基线。目标模型的能力密度定义为:同能力的基准模型参数量与目标模型参数量的比值。
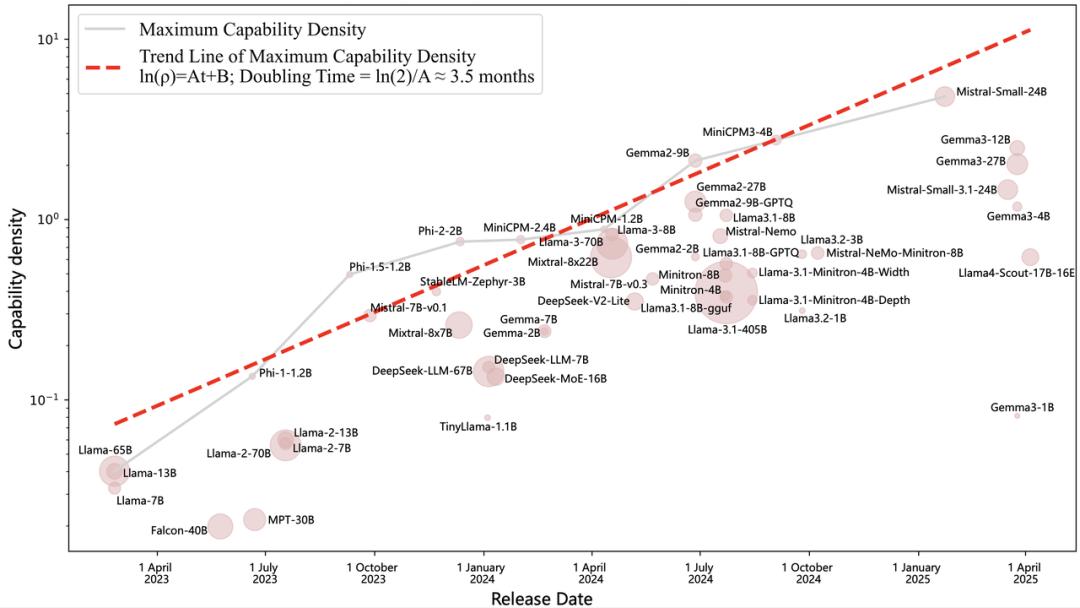
通过对51个近年来发布的开源大模型系统分析,研究团队发现大模型的最大能力密度随时间呈指数级增长,2023年以来平均每3.5个月翻一倍。这表明,随着「数据 - 算力 - 算法」协同发展,能用更少参数实现相同智能水平。
根据密度定律,研究团队得出了几个重要推论。
推论1:同能力模型的推理开销随时间指数级下降
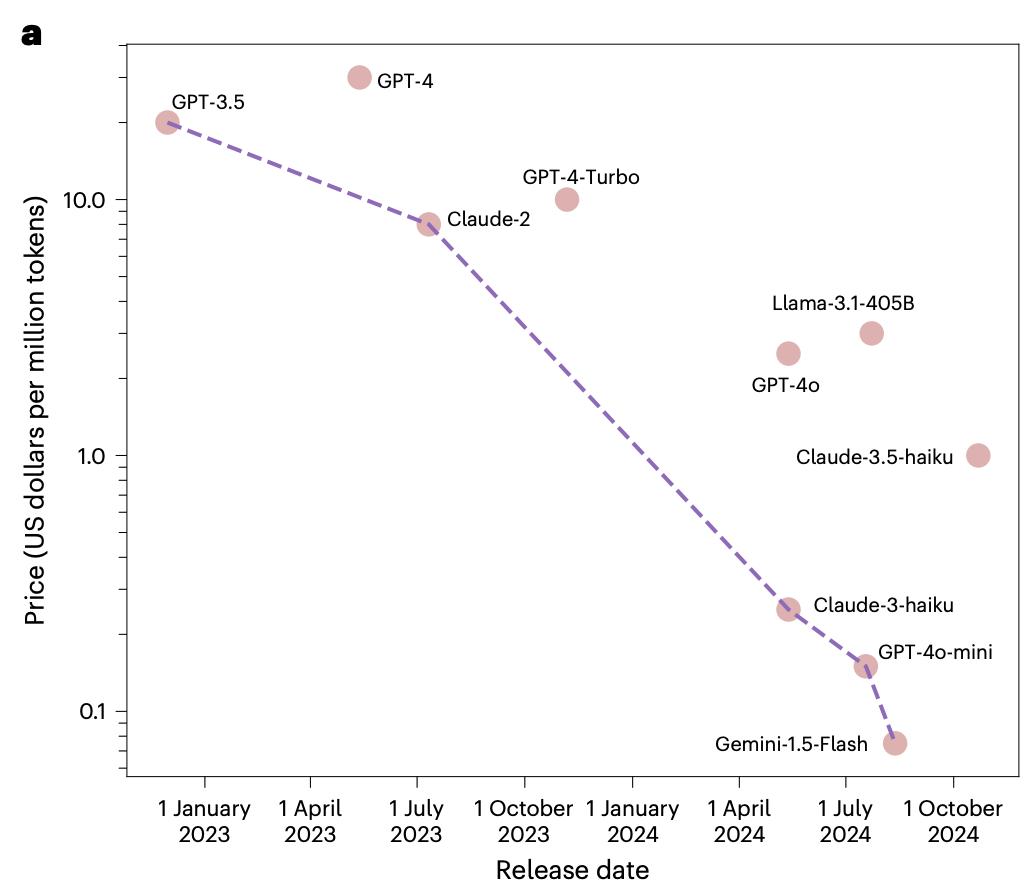
一方面,密度法则表明同能力的大模型参数每3.5个月减半。同时,在推理系统优化方面,摩尔定律推动芯片算力不断增强,模型量化、投机采样、显存优化等算法技术也不断突破,相同推理成本下能运行的模型大小持续提升。实证数据显示,GPT - 3.5级模型API价格在20个月内下降266.7倍,约每2.5个月下降一倍。
推论2:大模型能力密度正在加速增强
以MMLU为评测基准统计显示,ChatGPT发布前能力密度每4.8个月翻倍,发布后每3.2个月翻倍,密度增强速度提升50%。这说明,随着大模型技术成熟和开源生态繁荣,能力密度提升在加速。
推论3:模型压缩算法并不总能增强模型能力密度
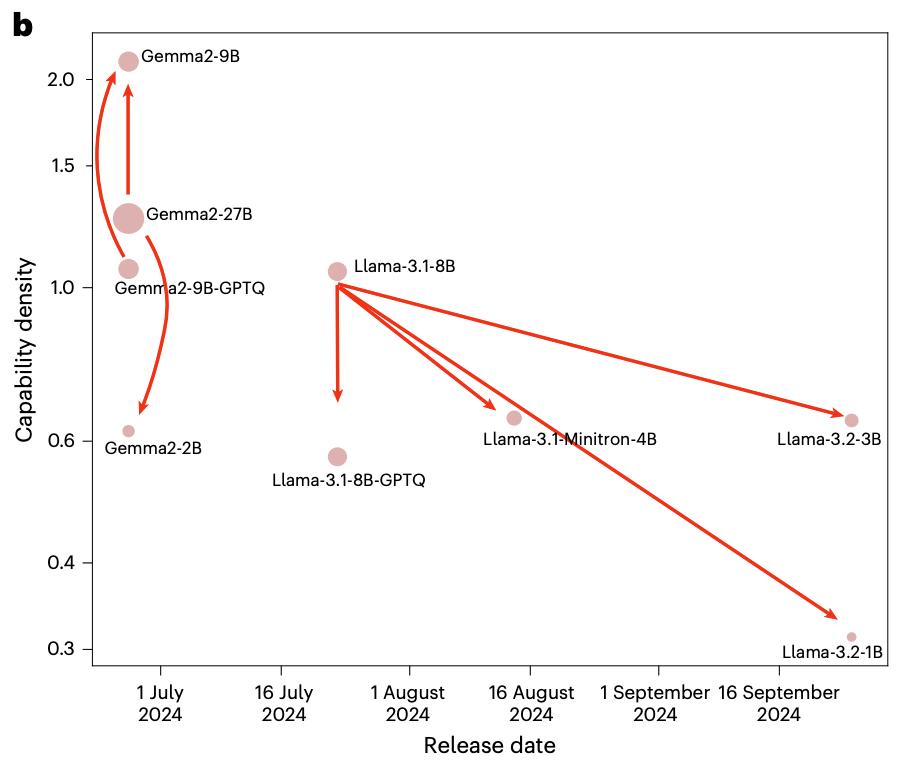
研究团队对比多个模型与其压缩版本的能力密度,发现除Gemma - 2 - 9B外,如Llama - 3.2 - 3B/1B、Llama - 3.1 - minitron - 4B等压缩模型密度都低于原始模型。量化技术也会降低模型性能和能力密度。这揭示了当前模型压缩技术的局限:压缩过程中较小模型训练往往不充分,无法达到最优密度。
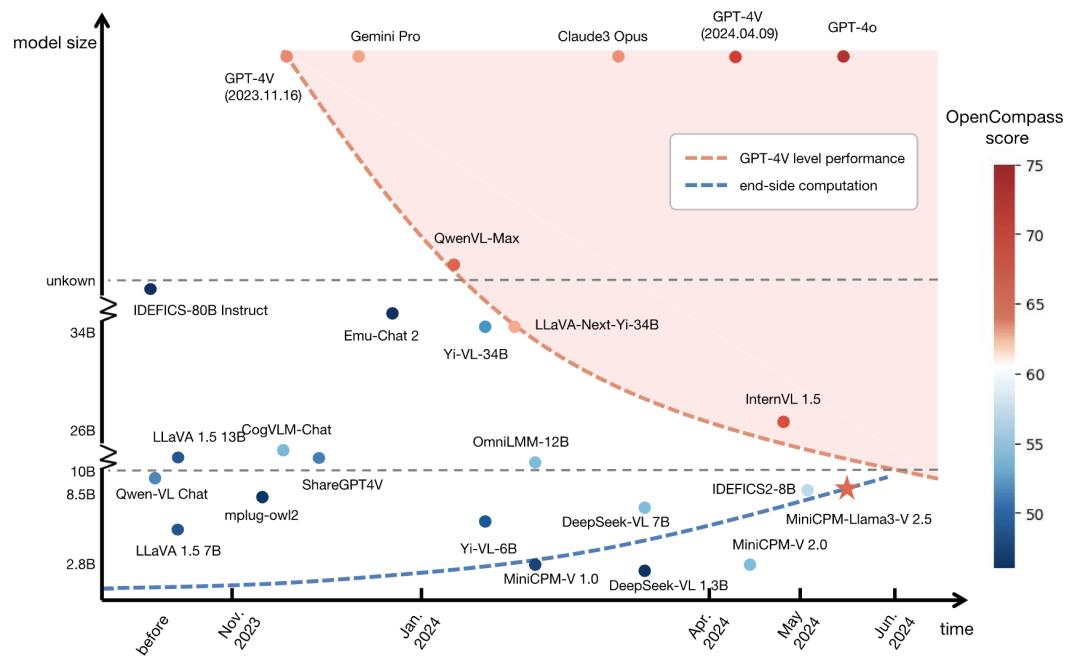
推论4:模型小型化揭示端侧智能巨大潜力
芯片电路密度(摩尔定律)和模型能力密度(密度法则)两条曲线交汇,意味着端侧设备能运行更高性能大模型,边缘计算和终端智能将迎来爆发式增长,算力普惠将从云端走向终端。
基于密度法则理论指导,清华大学、面壁智能团队持续推进高密度模型研发,发布了面壁小钢炮MiniCPM、MiniCPM - V/o、VoxCPM等一系列端侧高密度模型,凭借高效低成本特性享誉全球,被评为2024年Hugging Face最多下载、最受欢迎的中国大模型。截至2025年10月,模型下载量接近1500万次,GitHub星标接近3万次。
本文来自微信公众号“AI前线”,作者:清华TsinghuaNLP团队,36氪经授权发布。
清华大学研究成果大模型“密度法则”(Densing Law)带来了新视角。近日,该成果发表于Nature子刊《自然·机器智能》(Nature Machine Intelligence),为理解大模型发展规律提供了新维度。密度法则显示,大语言模型的最大能力密度随时间呈指数级增长,在2023年2月至2025年4月期间,约每3.5个月翻一倍,这意味着每隔3.5个月,就能用参数量减半的模型实现当前最优性能。
论文链接:https://www.nature.com/articles/s42256-025-01137-0
受“摩尔定律”启发的“密度法则”
回顾计算机发展历程,在摩尔定律的指引下,半导体行业不断改进制造工艺、提高芯片电路密度,使计算设备从重达27吨的ENIAC发展到仅数百克的智能手机,实现了算力普惠和信息革命。如今,全球有13亿台个人电脑、70亿部智能手机、180亿台IoT设备和2000亿颗运行中的CPU。摩尔定律的关键不是增大芯片尺寸,而是提升电路密度,即单位面积容纳更多计算单元。
受此启发,研究团队提出:可以从“能力密度”角度观察和理解大模型发展。如同芯片行业通过提升电路密度实现计算设备小型化和普惠化,大模型也能通过提升能力密度实现高效发展。
大模型密度法则:大模型能力密度随时间呈指数上升趋势
研究团队基于一个核心假设:采用相同制造工艺、充分训练的不同尺寸模型,其能力密度相同。在此基础上,选取基准模型并设定其密度为1,作为衡量其他模型能力密度的基线。目标模型的能力密度定义为:同能力的基准模型参数量与目标模型参数量的比值。
通过对51个近年来发布的开源大模型系统分析,研究团队发现大模型的最大能力密度随时间呈指数级增长,2023年以来平均每3.5个月翻一倍。这表明,随着「数据 - 算力 - 算法」协同发展,能用更少参数实现相同智能水平。
根据密度定律,研究团队得出了几个重要推论。
推论1:同能力模型的推理开销随时间指数级下降
一方面,密度法则表明同能力的大模型参数每3.5个月减半。同时,在推理系统优化方面,摩尔定律推动芯片算力不断增强,模型量化、投机采样、显存优化等算法技术也不断突破,相同推理成本下能运行的模型大小持续提升。实证数据显示,GPT - 3.5级模型API价格在20个月内下降266.7倍,约每2.5个月下降一倍。
推论2:大模型能力密度正在加速增强
以MMLU为评测基准统计显示,ChatGPT发布前能力密度每4.8个月翻倍,发布后每3.2个月翻倍,密度增强速度提升50%。这说明,随着大模型技术成熟和开源生态繁荣,能力密度提升在加速。
推论3:模型压缩算法并不总能增强模型能力密度
研究团队对比多个模型与其压缩版本的能力密度,发现除Gemma - 2 - 9B外,如Llama - 3.2 - 3B/1B、Llama - 3.1 - minitron - 4B等压缩模型密度都低于原始模型。量化技术也会降低模型性能和能力密度。这揭示了当前模型压缩技术的局限:压缩过程中较小模型训练往往不充分,无法达到最优密度。
推论4:模型小型化揭示端侧智能巨大潜力
芯片电路密度(摩尔定律)和模型能力密度(密度法则)两条曲线交汇,意味着端侧设备能运行更高性能大模型,边缘计算和终端智能将迎来爆发式增长,算力普惠将从云端走向终端。
基于密度法则理论指导,清华大学、面壁智能团队持续推进高密度模型研发,发布了面壁小钢炮MiniCPM、MiniCPM - V/o、VoxCPM等一系列端侧高密度模型,凭借高效低成本特性享誉全球,被评为2024年Hugging Face最多下载、最受欢迎的中国大模型。截至2025年10月,模型下载量接近1500万次,GitHub星标接近3万次。
本文来自微信公众号“AI前线”,作者:清华TsinghuaNLP团队,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com