
火爆的VLA,华为为何不用?






智能驾驶发展路径如今已走到分歧路口。
从去年起,VLA成为智驾行业频繁提及的词汇。理想、小鹏、元戎启行等车企或供应商纷纷押注VLA技术路线,还相继推出了量产和Demo产品。

而另一边,蔚来基于“世界模型”量产了最新的NOP+,华为则发布了基于WEWA架构的ADS 4,更强调WA(World Model Action)模型。
华为智能驾驶解决方案产品线总裁李文广和华为车BU CEO靳玉志甚至公开表示华为不会采用VLA的技术路线,还对L(Language Model)在智驾技术上的应用提出了质疑。
于是我们看到,VLA、NWM、WEWA等技术词汇众多,它们之间有何区别?哪种方案才是正确的呢?
大热的VLA究竟是什么
最近大家可能看到很多基于VLA打造的智驾产品评测,其中一个容易感知的功能是“语音控车”,比如你可以直接告诉车你的意图,像左转、右转或者靠边停车等。
例如理想智驾将其包装成专属司机,你能用语音控制车辆行驶,屏幕上反馈的文字也直观展示了车辆的行为,增强了交互性。
但这并非VLA最核心的能力,VLA也不是语音控车的必要条件。
早在2021年,小鹏就可以通过语音“使唤”辅助驾驶变道超车。
同样,你在桌面HMI上看到的车辆推理过程也不是VLA的核心卖点,这只是厂商把因果推理展示给你看,也算是一种交互。
语音输入和语言输出都不是VLA的核心能力。
元戎启行的周光称:“语音控车只是VLA的基础能力,最难的是思维链(Chain of Thought, CoT)和长时序推理,这才是VLA真正的核心能力。”

同样,识别车外的特殊交通识别指示牌也不是VLA独有的能力。
那么,VLA的具体作用是什么,为何还有这么多研发自动驾驶的人押注这条路线呢?
VLA中的V指感知、A是执行,中间的L是语言模型(Language Model)。V负责感知环境、A负责动作执行,中间的L类似于“中台”,将V感知的内容转译成A执行的规划和决策。
L转译的内容是自然语言,比如它看到前方有路口,能以自然语言表达感知内容,再结合车辆状态,做出行动规划和决策给A。
所以,VLA具有很好的可解释性。
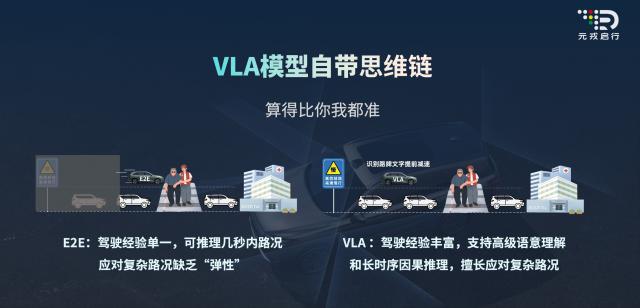
第二,正如周光所说,VLA具有基于思维链(COT)的推理能力。这里引用理想自动驾驶研发负责人郎咸朋博士的话更直观:“(VLA)真正发挥作用的是背后推理的长思维链。如果没有强大的L,再好的V和A都无法发挥出来。这跟人与动物的区别很相似。论视觉能力人比不过鹰,论行动速度比不过猎豹,但人之所以能称霸地球,靠的是强大的认知和理解能力,而这个认知和理解能力就来自于人类特有的语言能力。”
但VLA的弊端也较明显,既然语言模型要将看到的内容转述为语言并为决策服务,就涉及一个挑战——语言表述的模糊性与空间对齐问题。

例如,车辆看到的和我们想让车辆执行的位置是否一致。这就像我们跟着教程学做菜,放盐少许,这里的少许到底是多少?
华为李文广也有类似质疑:“它(VLA)有一个很大的弱点,它对空间的感知能力不行,因为我们的车是要做具体动作的,要在空间里面运动,那它在这块的感知能力不行,就这样就导致你让它来做动作的话,其实我是觉得,这条路挺危险的。”

华为靳玉志也表示:“我们不会走向VLA的路径,我们更看重WA(World Action),省掉language这个环节,通过信息输入直接控车,而不是把各种各样的信息转成语言,通过语言大模型再来控制车。”
华为与蔚来站在了一起
蔚来今年基于世界模型打造了最新的NOP+,几个月前已全量推送给用户。
在智能驾驶上,蔚来采用世界模型(World Model),华为在今年上海车展前也发布了全新一代架构WEWA,其中WE指的是World Engine世界引擎,WA指的就是World Model Action。
蔚来与华为,在智驾战略上倒是走到了一起。

我们先看华为的WEWA,WE世界引擎的核心作用类似于云端的“虚拟驾校”,用AI扩散模型生成难例场景,例如鬼探头、前车急刹等。
华为认为,在现实世界采集这类场景不现实,因为场景出现概率低,整体会很低效。
用AI训练AI,密度是真实世界的1000倍,效果提升会更明显。
第二个作用是云端仿真,解决长尾数据不足的问题。第三个作用则是生成的数据回灌给车端WA模型,做持续训练与蒸馏,形成“数据 - 模型”闭环。
WA更好理解:感知现实世界,不经过语言层,直接输出车控轨迹,也可称之为VA。
蔚来在去年年中就发布了NWM,即NIO World Model蔚来世界模型。它的核心作用就是像人一样,看到现在,脑补未来。

世界模型具备对信息的全景理解力,在想象的维度理解物理规律并重建世界。
它能根据感知输入的信息,在100毫秒内,推演216种可能发生的轨迹、寻找最优路径;还能基于3秒钟视频的Prompt输入,生成120秒想象的视频。
在NWM中,语言只是输入之一,例如你也可以通过语言“使唤”车辆,它也能展现出类司机Agent效果。
目前来看,行业里对VLA技术路线存在争议。
不只是华为、蔚来派,在上个月的2025世界机器人大会上,宇树科技王兴兴也公开谈论了VLA,他称:“ VLA相对还是一个傻瓜式的架构,自己对VLA模型抱有比较怀疑的态度。”
拿体验说话
看到这里,你应该对这些热门词的含义有了大致了解。
谁更先进、更强不需要我们评判,毕竟成千上万名从事AI、自动驾驶的专家都无法形成统一共识,我们作为“外行”岂能轻易下定论。
但这对消费者来说重要吗?其实根本不重要。目前基于世界模型的蔚来NOP+、基于VLA技术的理想AD Max,在体验上都有缺陷。
我们只需要看表现,用实践检验真理。
END

本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com