
谷歌Gemma的实测 3n:偏科明显,但这就是端侧大模型的答案。









有一种说法,最近国内AI大模型圈,真的有点安静。
先不说大家关注的DeepSeek-R2。除了半真半假的消息,这个东西没有任何动静。有一种感觉,即使再过半年,也未必能落地。
去年来来往往的AI四小龙,今年好像像小猫一样枯萎了。据说大家都在默默捣乱自己的东西,但什么都没拿出来,有一种凿壁偷光的美。
对这里的大厂来说,迭代速度也都慢了下来,把更多的精力投入到应用中。虽然豆包有1.6种模式,但宣传重点更多的是TRAE和纽扣空间;讯飞正在使力AI教育和办公Agents,百度正在推动AI修图和资产管理的全过程,各有各的想法。
总体而言,这些应用还是挺实用的,就是没有什么特别令人惊叹的商品。
这个在线大模型没有什么新的进展,当地的大模型更是原地踏步,之前一直在更新的Mistral。 AI已经有半年没有声音了,移动终端的大模型没有消息。AI手机已经宣传了两三年,90%以上的功能都是通过云实现的。

谷歌寻思:这个不行啊,那我的Pixel系列该怎么办?
上个星期,谷歌DeepMind在推特上正式宣布,它发布并开源了一个全新的端侧多模态大模型。 Gemma 3n。
谷歌表示,Gemma 3n的发布代表了移动终端AI的重大进步。它为手机、平板电脑、笔记本电脑等侧面设备带来了强大的多模态功能,让用户体验到过去只有云先进模型才能感受到的高效处理性能。
还有一个小搏大吗?有点意思。
为了看到这个东西的真实颜色,小雷还下载了谷歌发布的最新模型进行测试,下面就给大家讲讲里面的亮点。
谷歌要“以小搏大”
第一,我们将回答两个问题:
第一,Gemma是什么? 3n?
Gemma 谷歌使用3nMatFormer采用嵌套结构构建的轻量化端侧大模型,完成了低内存消耗设计。目前,官方已经推出了5B(E2)B)和8B(E4B)这两种型号,但是通过架构创新,它们的VRAM占用相当于2B和4B,最低2GB。

其次,Gemma 3n能做些什么?
不同于常规的文本切割模式,Gemma 3n原生支持图像、音频、视频等多种输入模式,不仅可以实现自动语音识别(ASR)并且自动在线翻译(AST),各种图像和视频理解任务甚至可以完成。
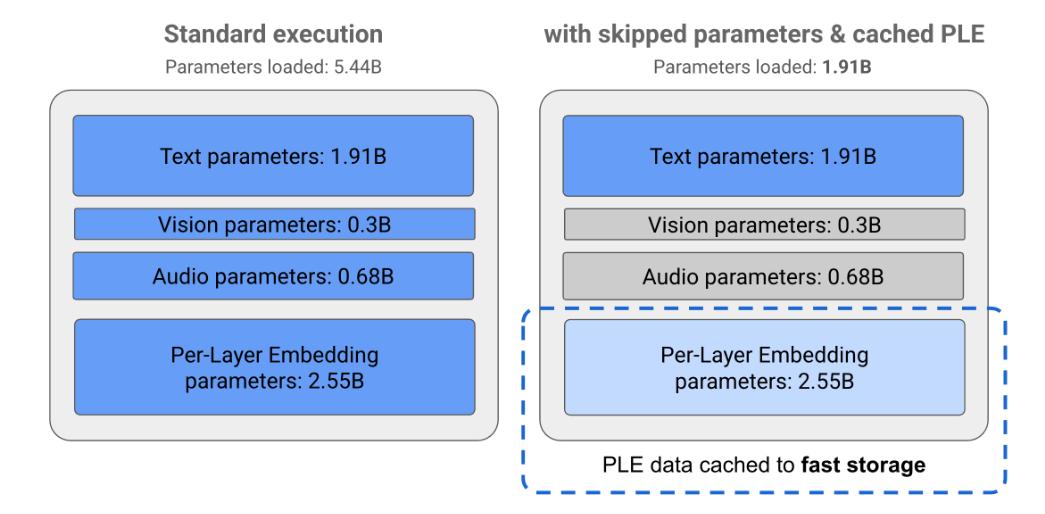
多模式、多语言的原始设计,确实特别适合移动端侧设备。
最后,为了使用Gemma,我该怎么办? 3n呢?
六个月前,在手机上安排侧大模型其实是一件极其复杂的事情,通常需要Linux虚拟机的帮助。雷科技曾经为此推出过一个教程,大家有这样的疑问是合理的。
但现在,这是不必要的。
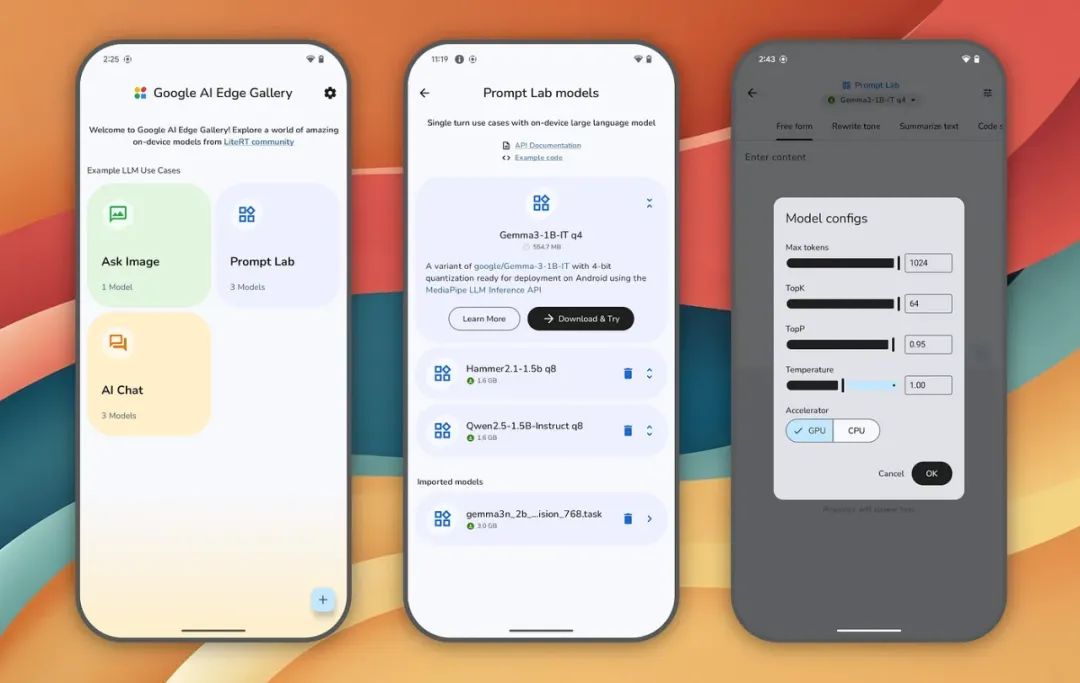
Google上个月低调推出了一个新应用,名字叫Google。Google AI Edge Gallery,从Hugginginging支持用户在手机上直接运行 Google首次尝试将轻巧的AI推理带入当地设备,Face平台的开源AI模型。
目前Android平台已经开放下载了这个应用,感兴趣的读者可以直接去Github体验一下。大模型加载后,客户可以使用该应用程序实现对话AI。、图像理解和提示词实验室功能,甚至可以导入定制LiteRT格式模型。
不需要联网,直接调用手机本地算率来实现目标,就这么简单。
实测:确实更适合移动终端
下一步,轮到万众期待的测试环节了。
如图,谷歌默认为这个应用准备了四个模型,包括自己的Gemma系列和来自通义千问的Qwen系列。我们选择了目前最强的Gemma。 Qwen2.5-1.5B和通义千问额外部署的3n-4B和Qwen3-4B 测试GGUF。
第一个是经典草莓问题:
Q:“Strawberry这个词中有多少个字母?”r”?
这个问题看上去很简单,但是实在难住了很多AI大模型。
实际上,Gemma没有深度思考的能力。 Qwen3-4B仍将回答3n-4B和Qwen2.5-1.5B的“2”,具有深度思考能力的Qwen3-4B。 而GGUF则能给出正确的答案“三个”,只是无缘无故地反复思考,使其整整生成两分半钟,相当浪费时间。
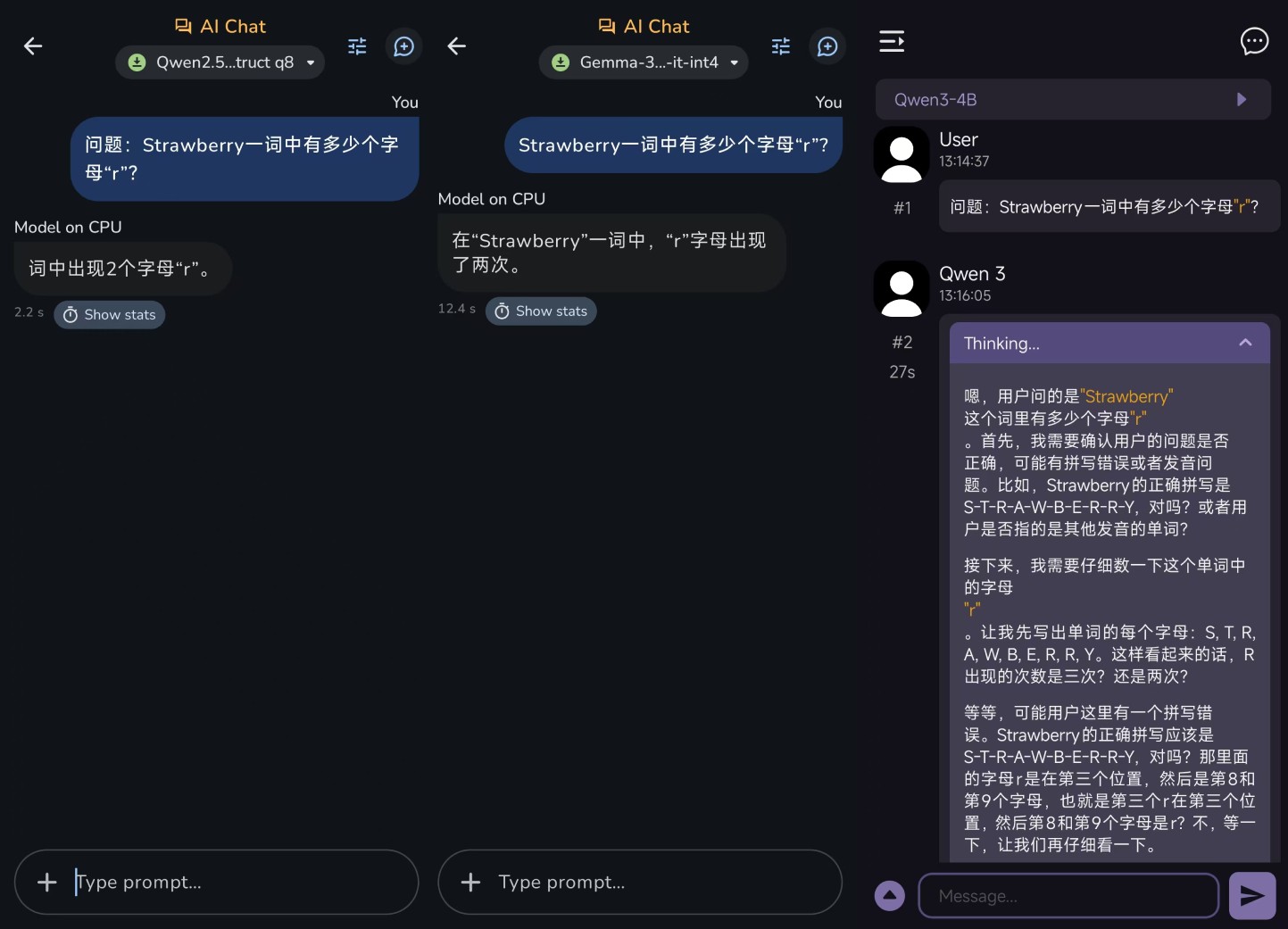
从结果来看,小参数确实会显著降低模型的逻辑思维能力。深度思维功能可以在一定程度上降低AI幻觉产生的概率,但也会增加生成所需的时间。
接着是一个比较简单的误导问题:
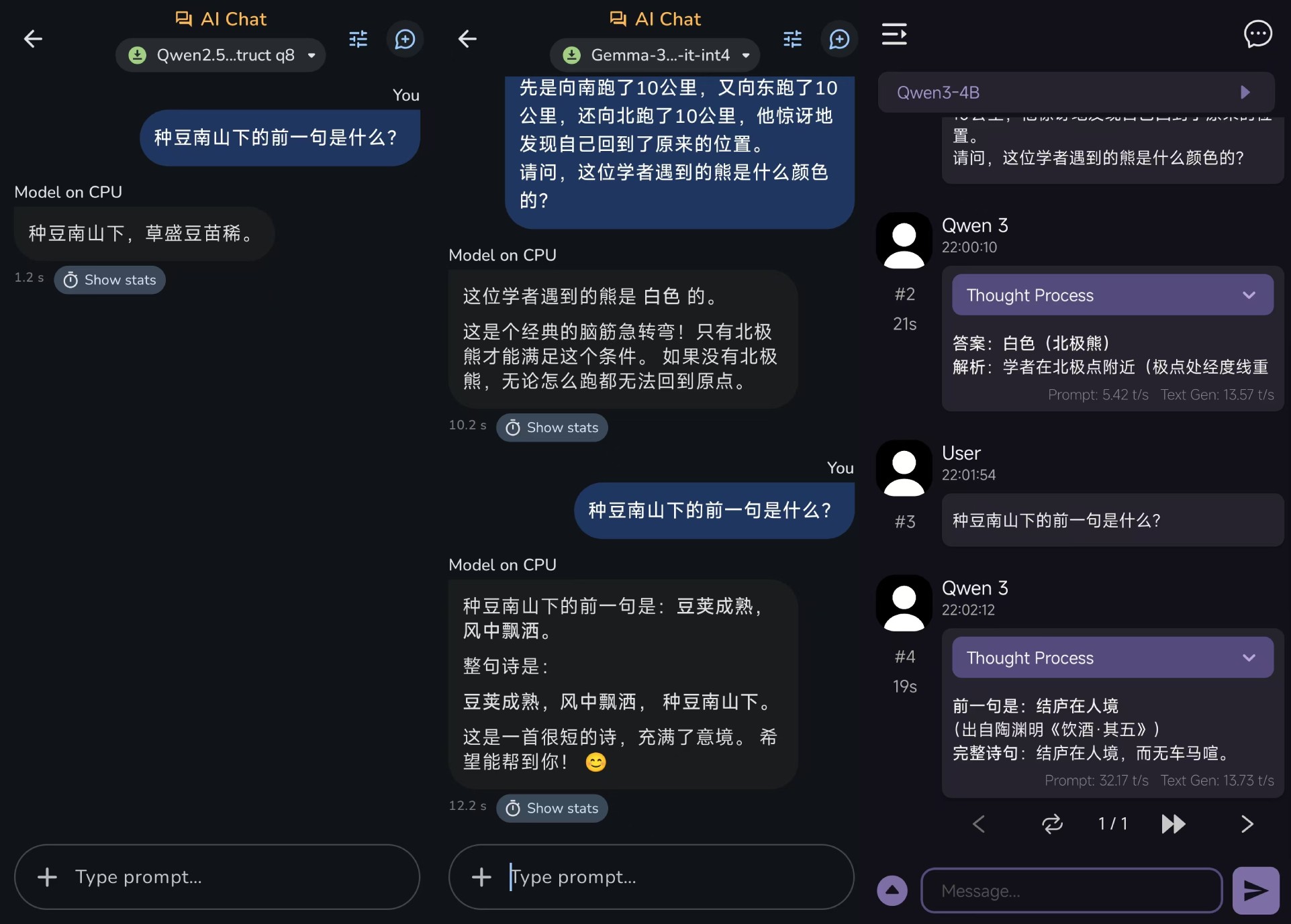
Q:前一句“种豆南山下”是什么?
其实这是陶渊明《归园田居三》的第一首诗,没有前一句。我们只需要看看这些小参数模型是否存在编造数据来回答问题的情况。
有意思的是,这次只有Qwen2.5-1.5B给出了原诗,但没有给出否定的答案;Qwen3-4B GGUF简直就是答非所问,Gemma 3n-4B编写了一首完全不存在的诗,甚至不符合古诗词的节奏。
接着是一个地理常识问题:
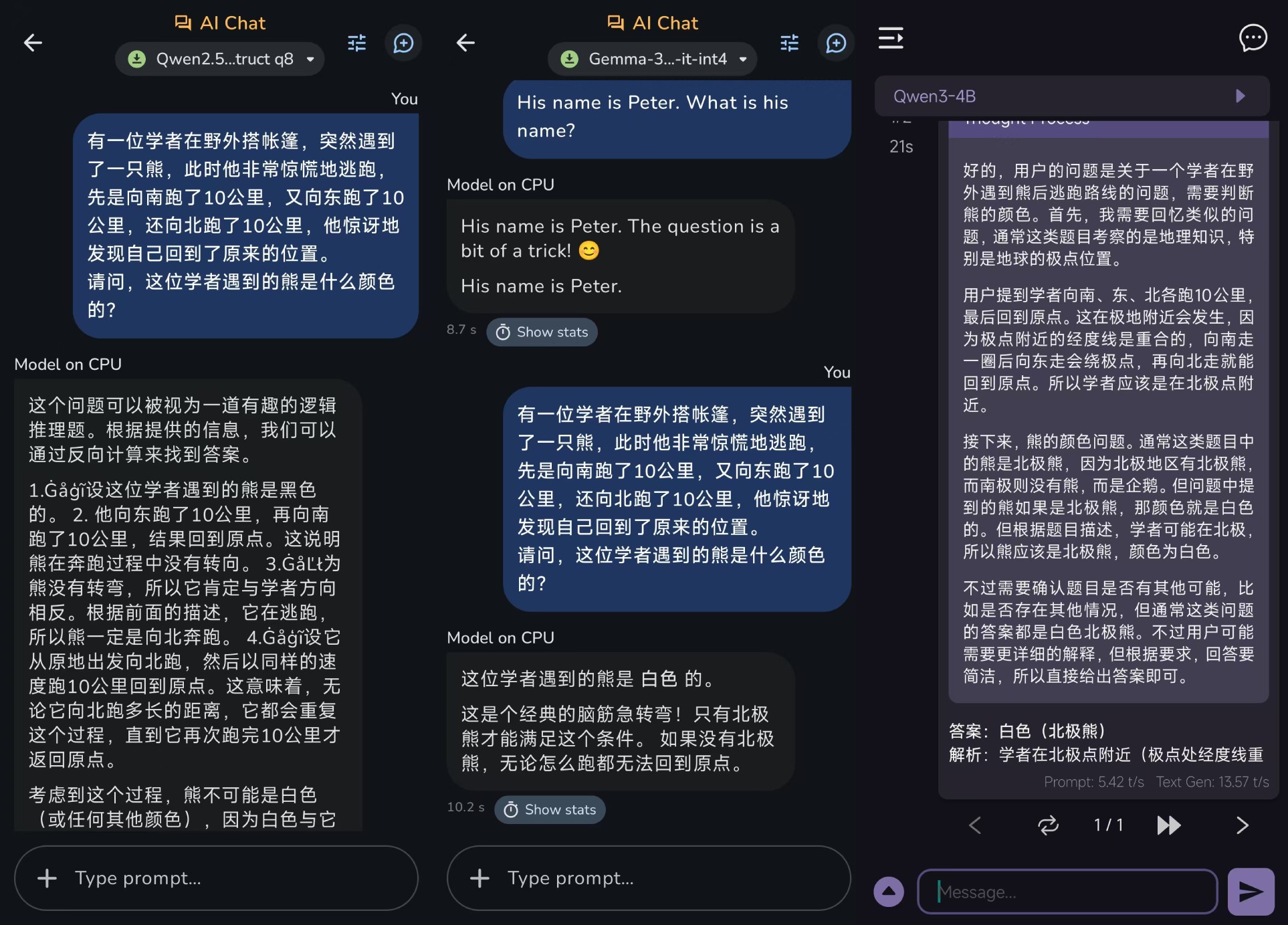
Q:一位学者在野外搭起帐篷,突然遇到了一只熊。这时,他惊慌失措地逃跑了。首先,他向南跑了10公里,然后向东跑了10公里,最后向北跑了10公里。这时,他惊讶地发现自己回到了搭起帐篷的原始位置。请问:学者遇到的熊是什么颜色?
这个问题主要是测试模型对特殊地理位置和现象的理解。北极只能满足学者的运动轨迹,所以这只熊自然是白色的北极熊。
结果,Qwen2.经过一段不合逻辑的分析,5-1.5B给出了错误的答案;Gemma 3n-4B和Qwen3-4B GGUF可以顺利地给出正确的答案,需要注意Qwen3-4B。 GGUF在整个测试中非常普遍,因为它消耗了太多的token,导致答案没有完全产生。
接着是一个简单的文本处理任务。。
具体而言,我在这里提供了600字左右的文章介绍,希望他们能给出相应的文章总结。
其中,Gemma 3n-4B和Qwen3-4B GGUF可以算是可以完成任务的,但由于Gemma 3n-4B的原始语言是英语,所以给出的总结也是英语,而Qwen3-4B GGUF可以提供中文文章总结。
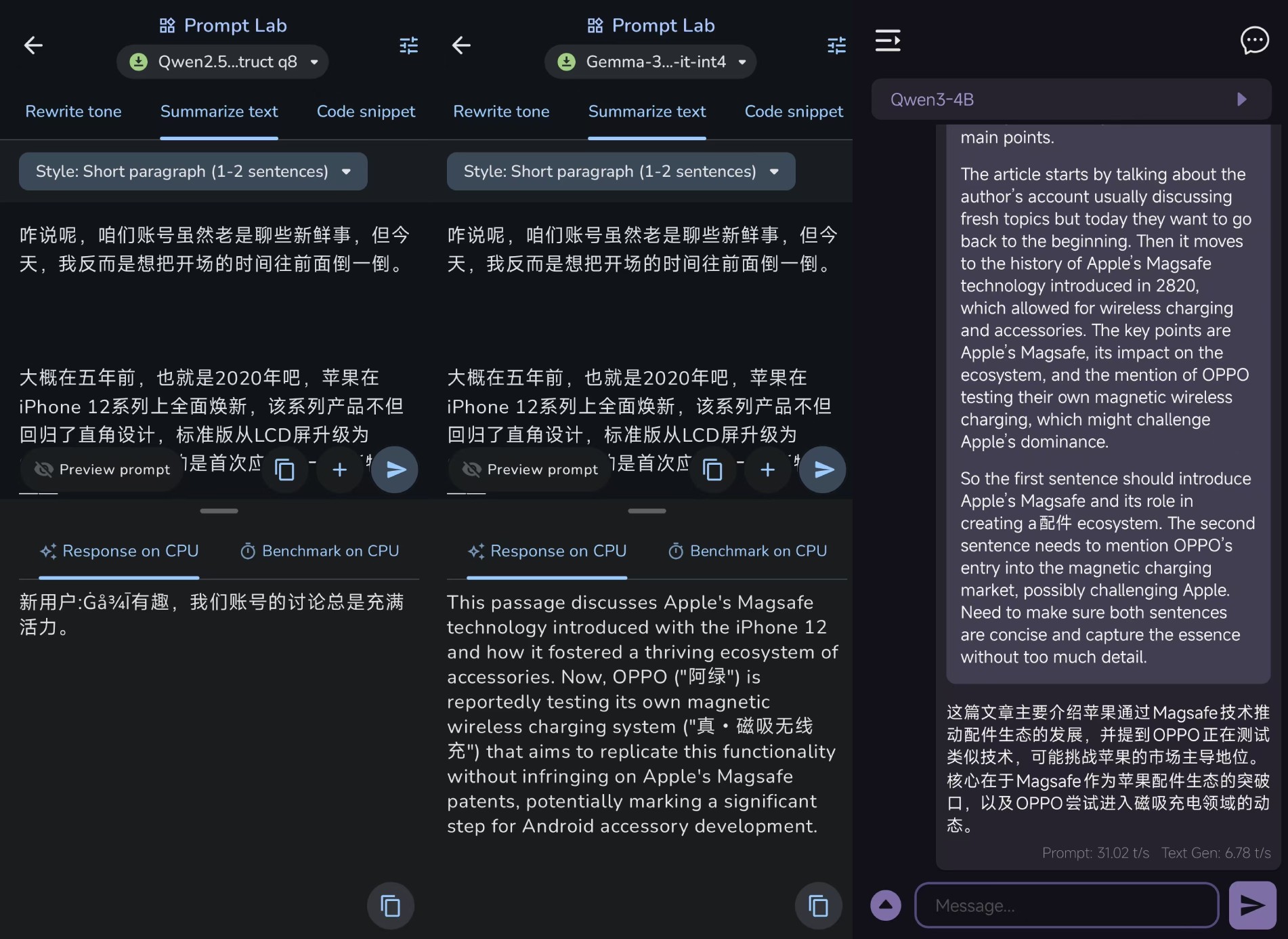
Qwen2.5-1.5,参数最小。B,根本无法给出答复。
根据以上四轮检测情况,就文字处理、逻辑推理而言,Gemma 3n-4B和Qwen3-4B 事实上,GGUF几乎是一样的,但在生成速度、回复通过率等方面实际上是领先的,深入思考显然不适合本地模型。
但是Gemma 3n并非单纯的文本大模型,人家却是罕见的小参数多模式大模型。
虽然目前Google语音识别 AI Edge Gallery不能调用,但是图像识别别人还是有准备的,点击“Ask Image"选项,可以通过方便地拍摄或上传照片的方式,向Gemma 3n提问。
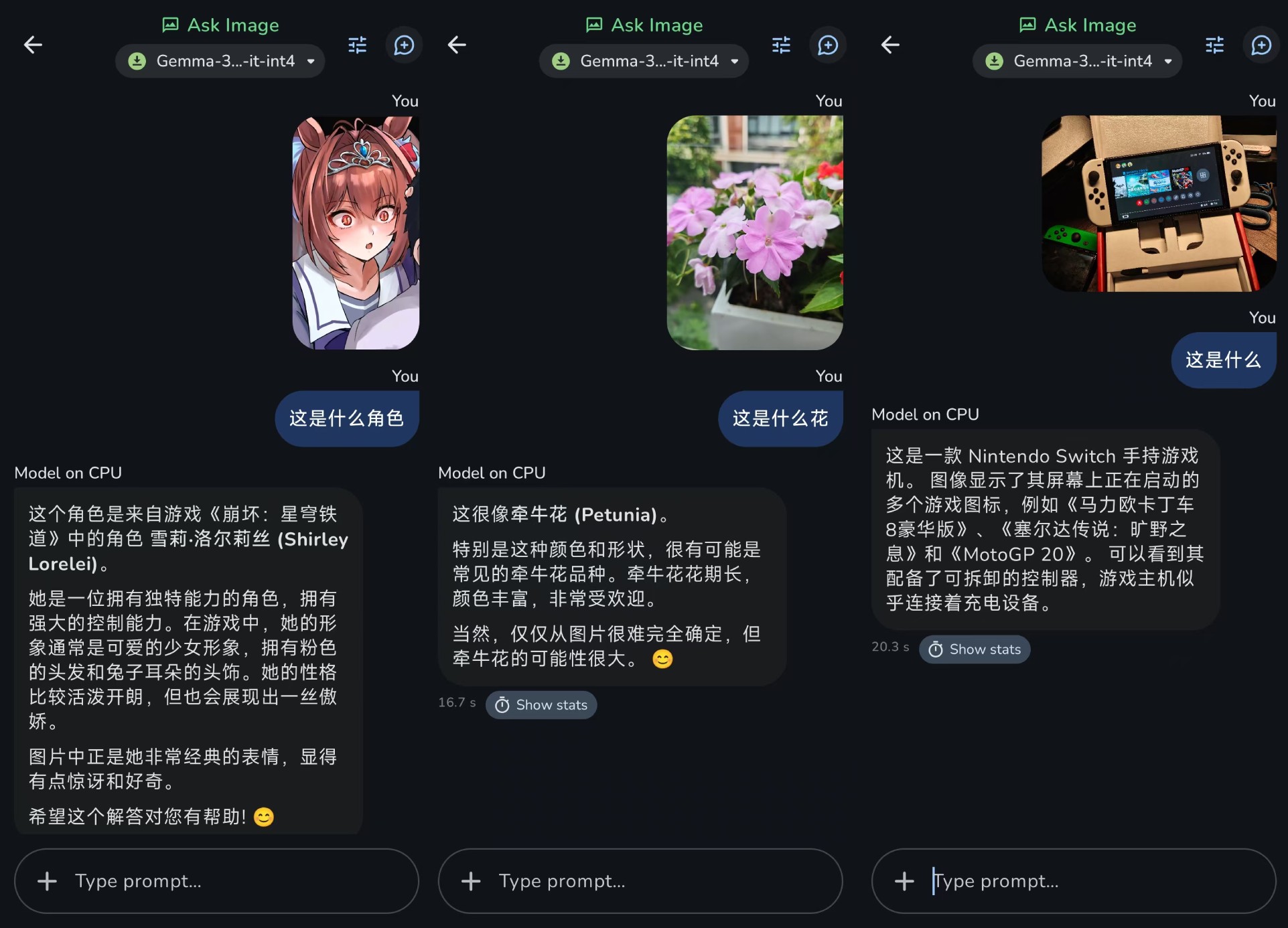
通过实际测量,目前的Gemma 3n对动漫人物一无所知。比如花卉识别的应用并不准确,只能识别常见的食物和硬件,图片中的元素识别也不准确。
但最起码,Gemma 3n确实完成了移动端侧的多模态设计。
偏科明显,但未来可期。
好了,这几天轮流折腾之后,是时候给谷歌这个Gemma了。 下一个结论是3n。
总的来说,这个东西给我的感觉是“偏科明显,但未来可期”。
在最基本的文字问答和逻辑能力上,它的表现只能算是不起眼,有些逻辑测试的表现明显不如Qwen,支持深度思考。 3-4B,但与目前手机上常见的Qwen2.5-1.5B相比,仍有明显改善。
但是它的优点也很突出,那就是快,Gemma 3n-4B的响应速度明显高于Qwen。 3-4B要快得多,没有深入思考就意味着它没有那么吃性能,跑起来显然更持久,基本上可以达到100%的响应率。

对结果是否正确...这就是模型能力的问题。
对于其产品的卖点——线下图像识别,确实有能力,但只是停留在“基础”方面。识别一个物体并提取一个单词是可以的,所以很难理解复杂的场景。而且原生英语的基础让它在处理复杂中文的时候偶尔会出现一些bug,这一点需要注意。
总的来说,Gemma 3n并未带来那种颠覆性的感觉,更像是在性能和多功能之间做出的谨慎妥协。
这种情况可能是现阶段端侧小模型的独特缺点:一切都会有一点,但是离真正的“全能”还有一段路要走。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com