
ROCm正式发布ROCMD 7开发平台:AI训练,推理性能暴涨3.8倍






快科技 6 月 13 日美圣何塞现场报道——
AMD 新一代今日正式发布 AI 加速卡 Instinct MI350 该系列,硬件能力再次突飞猛进,进一步加强了面对面 NVIDIA 的竞争力。
但我们知道,如果硬件性能和技术想要完全释放潜力,尤其是在 AI 强大的软件开发平台在加速系统中是不可或缺的。NVIDIA 能在 AI 这个行业有现在的地位,最大的功臣和环城河就是 CUDA。

AMD 还有自己的一套 ROCm 开发平台,一直和谐 NVIDIA CUDA 大家都有一定的差距,好在最近的进步幅度也很喜人,包括对诸多人来说。 AI 实时支持大模型,框架,全方位开源。
现在,我们又迎来了一个全新的 ROCm 7 版本,支持最新模型和算法,高级模型, AI 特性、新硬件支持、集群管理、企业级特性等各个方面,都再一次取得了长足的进步。

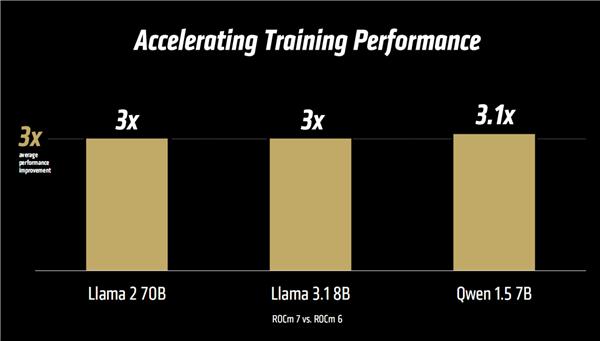
训练方面,ROCm 7 支持一系列新的特性,包括多个特性 AMD 开源模型,强化模型 AI 框架,增强内核和算法,新的数据类型 ( BF16/FP8 ) 等等。
官方声称比较 ROCm 6,实测在 Llama 2/3.1、千问 1.5 在多种模型中,性能提升普遍达到。 3 倍数甚至更高。

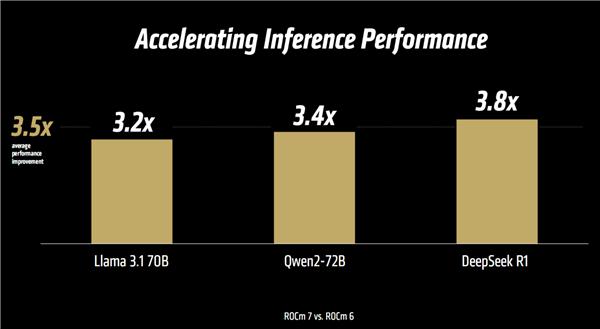
在推理方面,也有许多新的变化,包括增强框架,Serving 推广,核心和算法改进,高级数据类型 ( FP8/FP6/FP4/FP4/ 混和 ) 等。
性能提升同样可喜,Llama 3.1、千问 2、DeepSeek R1 等待模型实测平均值达到 3.5 倍,最高更可达 3.8 倍。
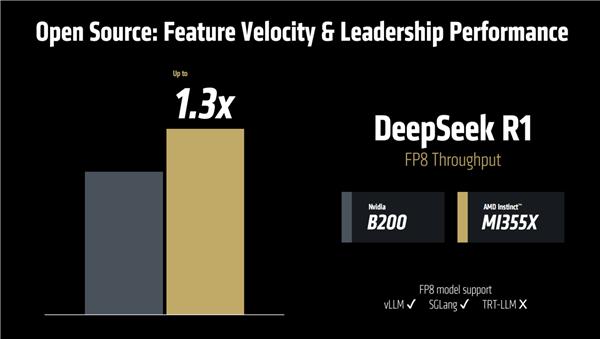
有了 ROCm 7 MI355X支持 面对 NVIDIA B200 也是一点也不弱,比如 DeepSeek R1 FP8 吞吐量可以领先到达 30%。
当然,这只是一个例子,AMD 对自己的新产品和同行竞争产品没有更多的比较。

除数据中心、企业端外,ROCm 7 消费端也有全面改善,增加了原生支持 Red Hat EPEL、Ubuntu、OpenSUSE 等更多的 Linux 在下半年,系统发行版实现了前两者。
Windows 同时,平台也增加了新的支持 PyTorch、ONNX-EP 两个框架,各自在第三季度和第三季度 7 每月开放浏览。

AMD 还顺便介绍了下面全线的消费级别。 AI 解决方案,比如移动端的锐龙 AI 300 该系列最高可在当地端侧运行 240 一亿参数模型,锐龙 AI Max 300 这个系列更可以跑到 700 数亿参数,而Cpu是新一代线程撕裂者。、Radeon AI 最高显卡组合可以搞定最高可以搞定 1280 亿参数。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com