
小米开源的新推理模式,居然可以在手机上跑起来







说到语言模型的本地部署,大家的第一反应应该是烧钱烧显卡,就像世超的老电脑一样,打个老电脑。 LOL 全部嗡嗡作响,可以说就是那个老古董毁了我。 AI 梦。
呃,有没有不吃装备,不吃钞票的能力,普通人也能感受到当地的部署? AI 快乐的方法是什么?
有的兄弟,有的。
世超这台 2000 不到元的红米 Turbo4,甚至可以成功地安排小米最新的语言模型。 Mimo-7B 量化版。
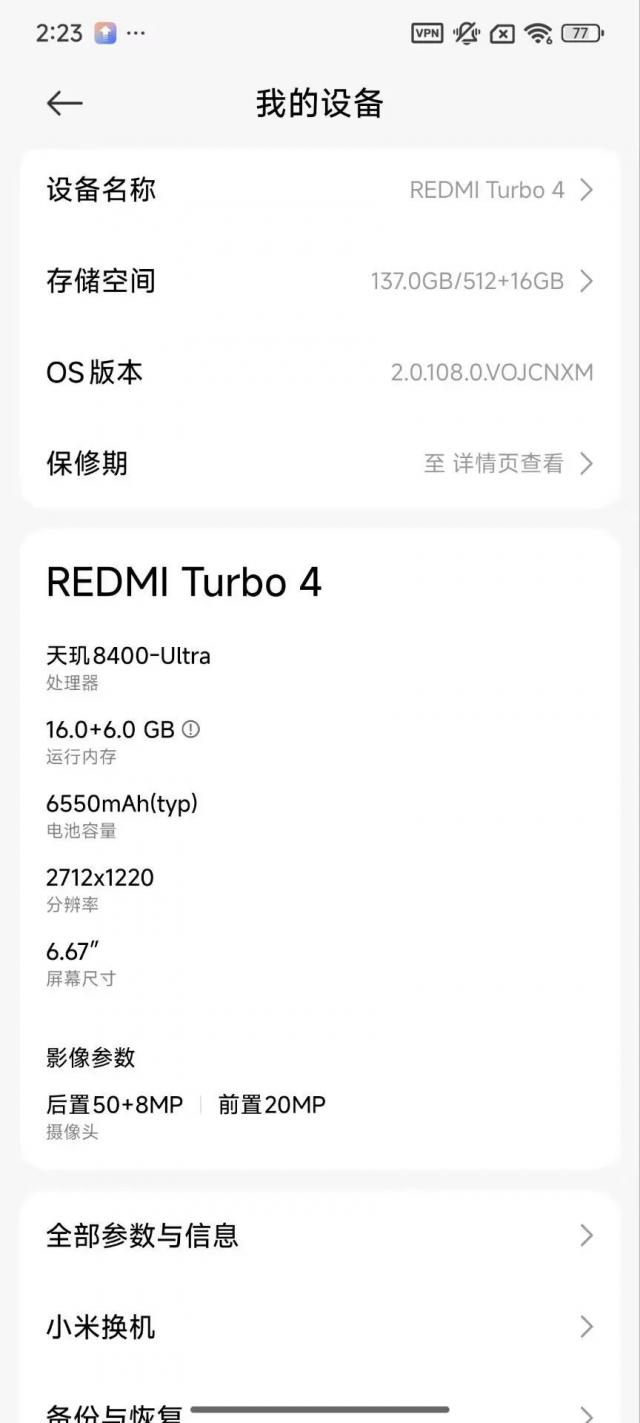
当网络完全断开时,它还可以一字一句地导出正确的结果。

大家都知道,世超心里一直想着差友,所以第一时间赶到给大家提供一个保姆级教程,包括两种方式。话不多说,准备冻手!
第一种方法,下载 Pocketpal AI,它是一款专门用于手机跑步的手机。 AI 模型应用程序。
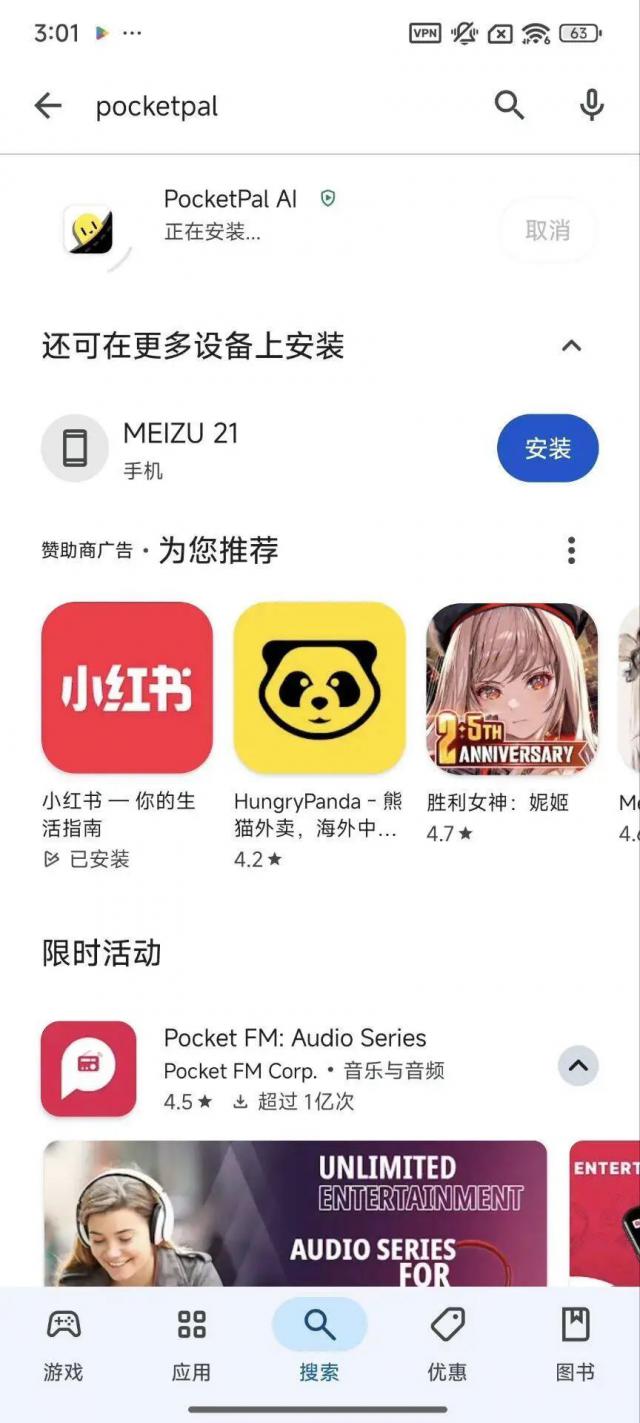
接着打开,点击 Download Model,再点右下角 号,挑选 Add From Hugging Face,随后搜索 Mimo,选择第一个版本下载即可。
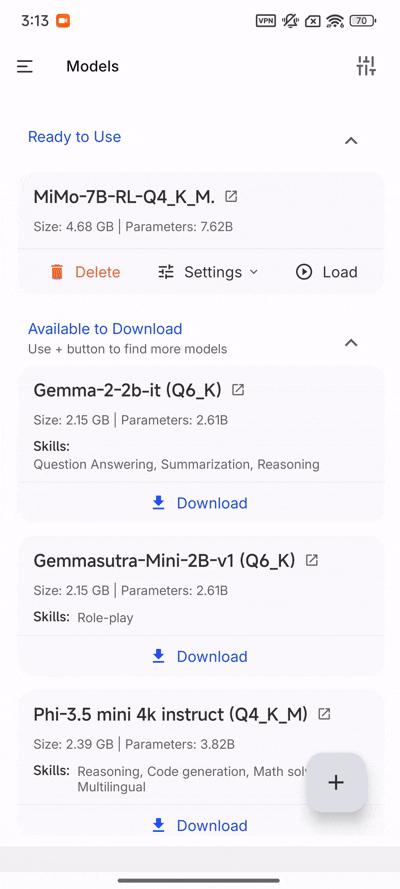
没有选择后面的,是因为后面的数字越大,模型精度越高,我们这个手机实际上是够呛的。
最后回到主页,点击 Select Model,可以选择模型开始聊天。
若怕麻烦,世超还准备了更简单的方法,直接从浏览器输入此网站:
https://github.com/alibaba/MNN/tree/master/project/android/apps/MnnLlmApp,这个平台是阿里开发的端侧多模态模型部署平台。
往下滑到 Release,点击 Download,下载这个 APP,您可以随意选择下载您想要体验的本地模型,甚至可以跑步 Stable Diffusion。。

OK,部署完成后,让我们给大家看看效果。世超那天下班后迷路了,不小心去了亚马逊的热带雨林。没有信号。我想我活不下去了。。所以我立刻拿出了我的 Mimo,问问他怎样钻木取火。

不到三分钟,他就把所有的东西都给我写了。
这里,我们小模型的独特优势已经完全体现出来——忽视环境,随时随地运行。
直接在手机上当地运行,也就是说,无论在雪山、沙漠、海洋,甚至是外太空,我们都可以随时随地拿出这位私人助理。
那么,如果再小一点呢?之前阿里刚刚发布的 Qwen3,只有一个参数。 0.6B 模型,我们也在自己家里。 MNN 试了试。

嗯。的确可以说话,但这说出来的话,似乎有点深奥。
然而,这可能与手机的布署有关,MNN 基本上上面的模型都是特别优化手机的布局,避免手机崩溃。一些模型的精度丢失是正常的,这只是概率事件。
总而言之,有了这些小模型,我们以后去哪都可以跟着。 AI 聊天的时候,坐飞船去火星肯定不会无聊。

有些人说,你这是歇斯底里的犯罪,这辈子能上太空吗?现在哪里没有网啊,这么多大模型? APP 哪一种不香?
但是小模型的使用,还真不止这些。假设,AI 如果想要更符合我们的生活,还真是一个小模型。
如果 AI 进屋后,你突然躺在沙发上想看电视,大喊大叫, AI 帮你开电视,其实是跑腿的工作。但是如果把指挥家具换成大模型,就要等它们上传数据,深入思考,然后把数据传回去。估计你还没等电视打开就刷短视频了。
另外一个优点是参数少——低延迟。参数不多,就不用考虑那么多事情,完全按照主人的指示去做。
而且,参数越少,练习和部署的成本就越低。有人说,一次训练 GPT-4o 这一级别的模型,将会被烧毁 1 一亿美元,平民根本烧不起这么大的模型。所以 AI 每一次开源新模型,企业都会发布各种尺寸,即让每个人都可以自由选择适合自己的模型。
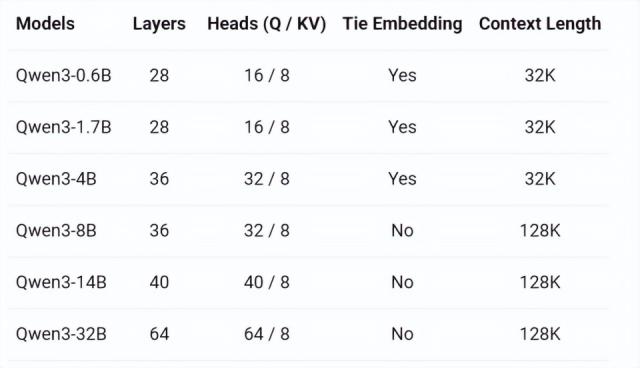
而且许多小企业,都是垂直领域的专家,没有大模型那样的百科全书。
参数少的模型可以用来训练各行各业的企业,不仅烧钱少,还能培养出这个领域的专家。如今,许多专业模型已经在各自的领域大放异彩。
像小满这样的金融模型 XuanYuan-尽管只有6B 6B,效果很好。注册会计师(CPA ) 、在许多金融行业考试中,如银行从业资格、基金从业资格、证券从业资格等,这些都可以显示金融专家的水平。
而且现在,很多公司也在开始小型模型,很多参数少的模型甚至可以与大型模型相媲美。
像咱的 DeepSeek,愣了一下,用一些新奇的算法,把参数少的模型性能弄上来。DeepSeek-R1-Distill 的 7B 和 14B 在数学推理任务中,版本可以超越很多闭源大模型。
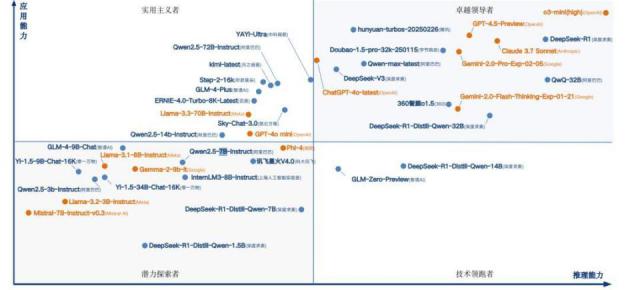
还有一家叫面壁智能的企业。他们专门从事端面模型,目标是移动终端,如手机、汽车和其他。他们做的“小钢炮” MiniCPM 只有 8B,检测表现居然可以与之媲美。 GPT-4o。
而且,他们很早就把多模态能力塞进了小模型中,完成了全模态,端到端。

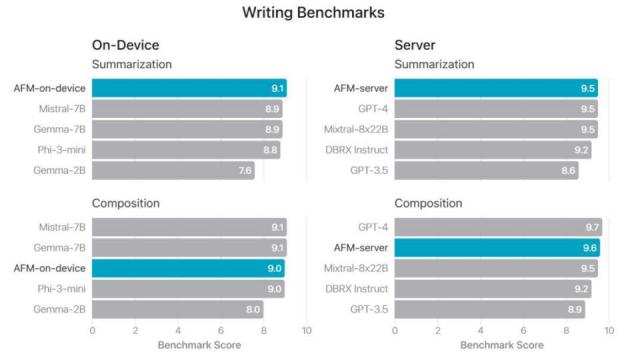
甚至苹果也开始自我研究 3B 他们的参数模型 AFM-on-device,当文本总结任务时,其效果可以优于文本总结任务 Gemma、Phi-3 mini 等待更大的参数模型。
那个问题又来了,这几个模型参数那么少,又能赶上大模型,这又是为什么呢?
这些小东西真的有独特的秘密。比如知识蒸馏的方法就像让老师给学生开个小火炉,让大模型把学到的知识和经验传授给小模型。
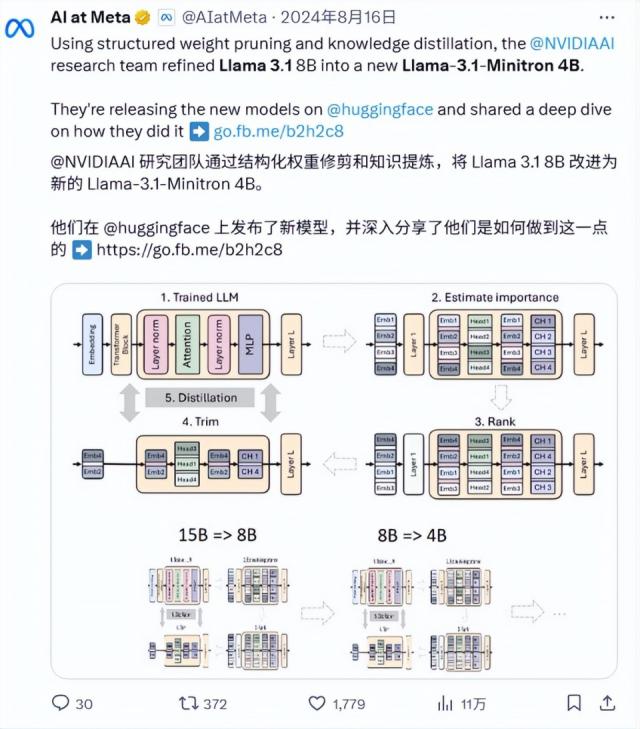
还有修枝量化的方法,简单来说就是把模型中的高精度计算变成低精度计算,不需要很高的性能,这样模型才能跑得更快。去年,英伟达联合 Meta 发布的 Llama-3.1-Minitron 4B AI 模型,就是从原来开始的 8B 模型修枝而来,使模型速度更快,资源更省。
最终还有一个招数,叫做混合专家模型(MoE)。传统的大模型就像一个齐心协力的专家团体,不管出了什么问题,都要全组抄家伙上阵。和 MoE 结构的作用,就是把这群专家拆分成 n 一个专业小组:有的专门从事数学推导,有的专门从事语义分析,有的负责图像识别。。这样,遇到小问题就不需要“全员加班”了。
所以,不要看这些模型个头小,也许就是迈向了。 AI 世上又一大步。正如科技创新从来都不是一蹴而就的,我们普通人,只是等待开花结果。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com