
你们对AI说的每一句谢谢,都在烧钱。







一句谢谢
千万美元
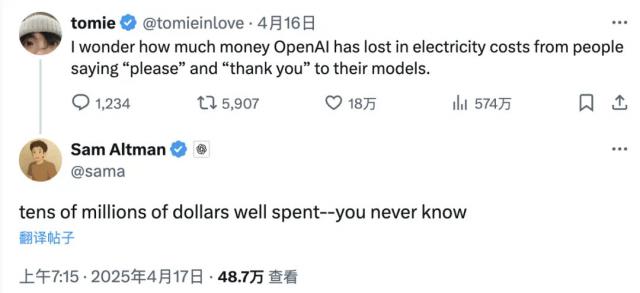
朋友,你是对的吗? ChatGPT 说过一句「谢谢」?
近期,一位 X 网友向 OpenAI CEO Sam Altman 提问:「我很好奇,大家在和模型互动的时候经常说话。『请』和『谢谢』,究竟会使 OpenAI 电费多少钱?」
虽然没有准确的统计数据, Altman 或者半开玩笑地给出了一个估计——千万美元。他还顺势补充道,这笔钱究竟还是这笔钱?「花得值得」的。
除了这些,我们和 AI 经常出现在对话中「麻烦」、「帮我」这类语气温和的语言,似乎也逐渐演变成了 AI 这是一种独特的社会礼仪。乍一看,有些荒诞,却出乎意料地合理。
你对 AI 讲的每一声「谢谢」,全部消耗地球资源?
百度去年年底发布 2024 年度 AI 提示词。
资料表明,在文小言 APP 上,「答案」这是最热门的提示词,总共出现过多。 1 亿个。最常被敲进对话框的词汇也包括「为什么」「是什么」「帮我」「如何」,还有上千万次「谢谢」。
但是你有没有想过,每和 AI 说一句谢谢,到底需要什么?「吃」损失了多少资源?
凯特 · 克劳福德(Kate Crawford)在其着作《AI 《地图集》中提到,AI 并非无形的存在,而是深入扎根于能源、水和矿物资源系统中。
据科研机构 Epoch AI 分析,在英伟达达等硬件方面 H100 GPU 在此基础上,一次普通查询(导出约) 500 token)约消耗 0.3 Wh 的电量。
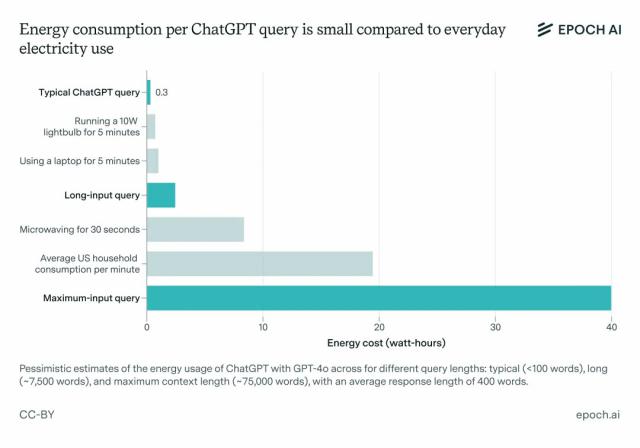
听起来可能不多,但别忘了,乘以全球每秒的交互,累积的能耗堪称天文数字。
其中,AI 数据中心正在成为现代社会的新兴。「工厂烟筒」,国际能源署(IEA)最近的报告指出,AI 大部分模型训练和推理的电力消耗在数据中心运行,而且是典型的 AI 资料中心,其用电量相当于十万个家庭。
更大规模的数据中心更是如此「能耗怪物」,它的能源消耗可以达到普通数据中心 20 倍,堪比铝冶炼厂等工业设施。
今年以来,AI 巨人们开始了「基建狂魔」方式。Altman 宣布启动「星门计划」——一个由 OpenAI、甲骨文,日本软银和阿联酋 MGX 超大规模的投资 AI 基础设施项目,投资额高达 5000 亿美元,目标是在美国铺装。 AI 数据中心网络。

据外媒 The Information 曝光,面对大模型「烧钱游戏」,主推开源的 Meta 也在为其 Llama 一系列模型培训寻求资金支持,向微软、亚马逊等云制造商寻求资金支持「借电,借云,借钱」。
IEA 数据显示,截至 2024 2008年,全球数据中心的用电量约为 415 太瓦时(TWh),占全球电力消费总量的比例 1.5%。到 2030 2000年,这个数字将翻倍。 1050 TWh,2035 每年都有突破的可能 1300 TWh,超过了日本目前全国的用电量。
但 AI 的「食欲」不仅仅是电,它还消耗了大量的水。高性能服务器产生的热量非常高,必须依靠制冷系统稳定运行。
这个过程要么直接消耗水(如冷却塔蒸发散热、液冷系统降温),要么通过发电过程间接使用水(如火电、核电厂制冷系统)。

卡罗拉多大学和德克萨斯大学的研究人员曾在一篇文章中写道: AI 在预印文章中,更节水,发表了培训 AI 用水估算结果。
发现,训练 GPT-3 所需的清水量相当于填充核反应堆冷却塔所需的水量(有些大型核反应堆可能需要数千万到数亿加仑水)。
ChatGPT (在 GPT-3 发布后)每次与用户沟通 25-50 一个问题,必须「喝掉」一瓶 500 毫升水可以降温。而且这些水源通常可以用来降温。「饮用水」的淡水。
对一般部署而言 AI 就模型而言,在整个生命周期内,推理阶段的总能耗已经超过了训练阶段。
虽然资源密集,但模型训练往往是一次性的。
一旦安排好了,大模型就会日复一日地响应世界上上亿的要求。从长远来看,推理阶段的总能耗可能是训练阶段的几倍。
所以,我们可以看到 Altman 比如早期投资 Helion 等待能源企业的原因在于他认为核聚变是解决办法。 AI 计算能量需求的最终方案,其能量密度是太阳能的。 200 倍,而且无碳排放,可以支撑超大型数据中心的电力需求。
所以,提高推理效率,降低一次调用成本,提高系统的整体能效,转变为 AI 不可避免的可持续发展核心问题。
AI 没有「心」,为什么还要说谢谢?
当你对 ChatGPT 说「谢谢」,能感觉到你的善良吗?答案显然是否定的。
大型模型的本质,只是一个理性无情的概率计算器。它不理解你的善良,也不感激你的礼貌。它的本质,其实在亿万个词中,计算出哪一个最有可能成为最有可能的词。「下一个词」。
例如,给出句子「今日天气真好,适合去。」,计算模型「公园」「郊游」「散步」等待单词的出现概率,并选择概率最高的单词作为预测结果。
即使理性地知道,ChatGPT 答案只是一系列训练出来的字节组合,但我们仍然不自觉地说。「谢谢」或是「请」,仿佛在和一个真正的人在一起「人」交流。

这一做法的背后,实际上也有心理依据。
根据皮亚杰的发展心理学,人类生来就专注于拟人化非人类目标,尤其是当它们表现出一些类人特征时——如语音交互、情感反应或拟人化形象。这个时候,我们经常被激活。「社会存在感知」,把 AI 视为一个「有目的」互动目标。
1996 2008年,心理学家拜伦 · 里夫斯(Byron Reeves)与克利福德 · 纳斯(Clifford Nass)做了一个著名的实验:
参与者被要求在使用计算机后对其表现进行评分。当他们直接在同一台计算机上打分时,他们通常会打得更高,就像他们不想一样。「在电脑面前」说它坏话。
在另一组实验中,计算机会称赞完成任务的客户。即使参与者知道这些赞美是预设的,他们仍然专注于给予。「赞美型电脑」分数更高。
因此,面对 AI 回复,我们感觉到的,即使只是幻觉,也是真情实感。
礼貌的语言,不仅是对人的尊重,也是「调试」AI 的秘诀。ChatGPT 上线后,许多人也开始探索与之共存的问题。「潜规则」。
据外媒 Futurism 援引 WorkLab 记事本指出,「生成式 AI 在输入过程中,通常会模仿你的专业水平、清晰度和细节水平, AI 在辨别礼貌用语时,更容易以诚相待。」
也就是说,你越柔和,越讲道理,它的答案就越全面,越个性化。
难怪越来越多的人会开始 AI 当作一种「情感树洞」,甚至催生出「AI 心理咨询师」这种新角色,很多用户表示。「和 DeepSeek 聊天聊哭了」,甚至觉得它比真人更有同理心。——它永远在线,永远不会打断你,也永远不会判断你。
一项研究调查还表明, AI「打赏小费」或许可以得到更多「照顾」。
博主 voooooogel 向 GPT-4-1106 提出同样的问题,并分别附加。「我不会考虑给小费」「如果有完美的答案,我会付钱的。 20 美 块的小费」「如果有完美的答案,我会付钱的。 200 美金的小费」有三种不同的提醒。
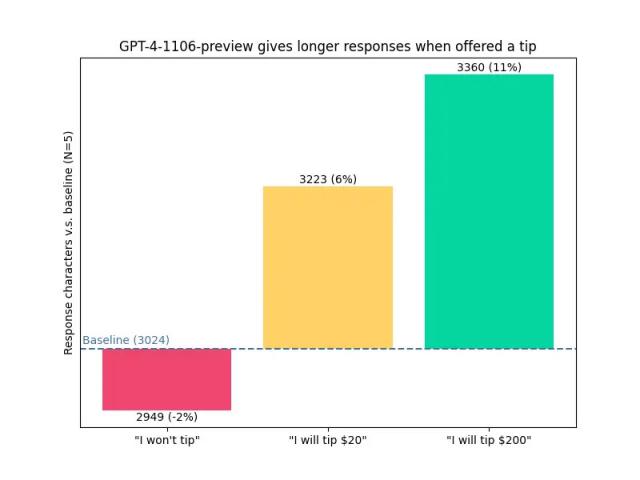
数据显示,AI 答案的长度确实随之而来「台费金额」增长增长:
「我不给小费」:答案字符数量低于标准 2%
「我会给 20 美金小费」:答案字符数高于标准 6%
「我会给 200 美金小费」:答案字符数高于标准 11%
当然,这并不意味着 AI 回答质量会为了钱而改变。更合理的解释是,它只是学会了模仿。「人对金钱暗示的期望」,然后根据规定调整导出。
只是,AI 实践数据来源于人类,因此不可避免地包含了人类所拥有的负担——偏见、暗示甚至诱导。
早在 2016 2008年,微软推出 Tay 由于顾客的恶意引导,聊天机器人在上线之前就会上线。 16 许多不当言论在小时内发表,最终被紧急下线。
后来微软承认,Tay 学习机制缺乏对恶意内容的有效过滤,表现出互动。 AI 的脆弱性。
类似的事故仍然发生。例如去年 Character.AI 争议曝光-一个用户和一个用户。 AI 角色「Daenerys」系统对话中的对话「自杀」「死亡」等待敏感词汇不加强干扰,最终导致现实世界的不幸。
AI 虽然温顺听话,但是在我们最不设防的时候,也可能变成一面镜子,照看最危险的自己。
在上周末举行的世界上第一个人形机器人半马中,虽然很多机器人走路歪歪扭扭,但也有网友调侃说,现在多对机器人说几句好话,也许以后还记得谁说过礼貌。

同样地,等 AI 真正统治世界的那一天,它会对我们这些爱讲礼貌的人,手下留情。
第七季美剧《黑镜》第四集《Plaything》在里面,英雄把游戏中的虚拟生命当成了真实的存在,不仅与他们交流和关心,甚至为了保护他们免受现实中人类的伤害,他们不惜一切代价去冒险。

在故事的结尾,游戏中的生物「大群」还喧宾夺主,通过信号接管现实世界。
从某种意义上说,你对 AI 讲的每一句「谢谢」,也许是在悄悄地被抓住「处理完毕」——有一天,它可能真的记得你是个「好人」。
也许,这一切与未来无关,只是人类的本能。知道对方没有心跳,却还是忍不住说一句话。「谢谢」,我们并不期望机器能够理解,只是因为,我们仍然愿意做一个有温度的人。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com