
英伟达H20受限于中国市场,国产AI芯片取代多点开花方为正解。






文 | 孙永杰
经过多轮市场传闻猜测和情绪翻转,美国政府终于对英伟达说了一句话。 H20 芯片出口管制升级,随后英伟达 CEO 黄仁勋时隔 3 再一次访问中国,表示希望继续与中国合作,可见这一举动在行业内引起的震动。而且伴随着 H20 中国市场芯片受限,国内市场受限 AI 真正的芯片替代考试也正式开始。
英伟达 H20 等待限制,国内厂商迎接取代考试机会。
提到 H20 近日,英伟达发布了芯片出口管制公司 8-K 这份文件说,美国政府是 4 月 9 日告知,H20 芯片出口到中国需要许可证,之后又因为 14 每天通知,这些规定将无限期执行。美国将 H20 列入“非民用超算风险清单”,代表 AI 芯片控制从高端品牌(例如 A100、H100)延伸到定制中端产品。需要注意的是,H20 它是英伟达在中国合法销售的主要芯片, 2023 年 10 最新一轮月美国出口限制生效后推出。

与此同时,美国商务部宣布,AMD MI308 以及同类的 AI 芯片还增加了中国出口许可的新要求。英特尔似乎没有获得任何豁免。据报道,该公司还需要获得出口许可证才能向中国销售。 Gaudi 芯片。
对于这一点,华泰证券指出,H20 销售有限或者已经被市场预测,但是新规或者说明将堵塞内存填补算率漏洞。而且万联证券认为,这次美国国家对此 H20 经营许可证管理,说明贸易管制力度加大,感觉 H20 在中国市场的销售可能会面临更大的限制,或者英伟达在中国的市场份额会丧失,国内市场份额会丧失。 AI 芯片制造商有望承担更多的市场份额。该机构进一步指出,预计全球贸易摩擦或半导体产业国内化进程将进一步加快,国内计算率将迎来发展机遇。
而且在我们看来,随着英伟达 H20、AMD MI308 及同类的 AI 芯片和英特尔 Gaudi 中国市场芯片销售受限,国产 AI 芯片取代考试的机会真的来了,就是国内厂商有前所未有的市场空间来验证自己产品的性能、可靠性、生态兼容性和供应链稳定性。
地方力量的崛起,华为升腾领先于光晕下的隐患
提到英伟达的替代 GPU 华为升腾考试机会(Ascend)毫无疑问,系列芯片是目前最引人注目、声量最大、在实际部署中走得最远的地方替代品。尤其是以升腾。 910C 最新一代商品作为代表,正在成为中国建设的地方。 AI 基础设施的核心。
更为重要的是,华为通过将芯片能力延伸到系统方面, CloudMatrix 这种计算系统(例如最近被媒体广泛报道的 384 块昇腾 910C 构成,选择全对全互联拓扑。 CM384 系统)汇集算率,其超节点在规模和推理性能上已经与英伟达比肩。 NVL72 超级节点水平。而且这和华为升腾一起构成了计算系统的核心。 910C 芯片是密不可分的。
据包含 Huawei Central、TrendForce News 和 Reddit 研究分析了许多可靠的来源和平台,升腾腾 910C 就是通过将两个升腾 910B 采用共封装的芯片组合而成。(co-packaging)或芯片组(chiplets)技术。并且通过两个组合 910B 芯片,910C 计算能力显著提高,达到 800 TFLOP/s(FP16)的计算能力和 3.2 TB/s 内存带宽,几乎是英伟达 H100 特性的 80%。

所谓有利有弊,这种设计方法虽然在短时间内提高了性能,但也带来了显著的缺点。
第一,从技术角度来看,这种设计会导致功耗增加、互连瓶颈等。
以功耗增加为例。更高的功耗代表了更多的排热需求,增加了散热系统的成本和复杂性(例如,需要更强的风扇、散热器或液冷系统)。同时,在数据中心等对能效要求较高的场景下,高功耗会显著增加运营成本。
据知名半导体和人工智能研究公司介绍 SemiAnalysis 称,CM384 该系统的功耗远远高于英伟达 GB200 NVL72 系统。比如这需要 GB200 NVL72 3.9 功耗翻倍,每次 FLOP 的功耗差 2.3 倍,每 TB/s 内存带宽功耗差 1.8 倍,以及每 TB HBM 记忆空间功耗差 1.1 倍(“功耗差” X “倍”在这里表示相对于基准。 GB200 每个单位性能的NVL72 / 容量所需的功耗就是它 X 倍,即能效差 X 倍)。上述部分原因可能是由于升腾造成的 910C 这种芯片本身的组合设计。
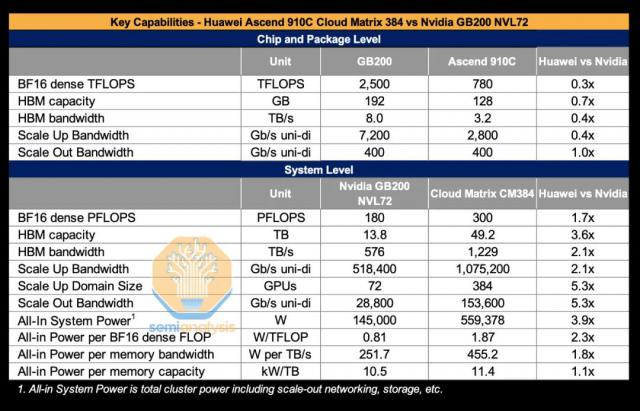
不能低估功耗的增加,在实际安排方面,每一台 AI GPU 基本投资大约是服务器。 40 万美元,其中电源、冷却等基础设施占建设成本。 1/3 以上。据 IDC 调查显示,80% 在华为,数据中心决策者将能源消耗和排热视作为关键的限制因素, CM384 系统功耗为 GB200 NVL72 的 3.9 两倍,其长期使用成本必然会稳步上升,而如何在规模扩张和能效之间找到平衡是一个巨大的挑战。
尽管是互连瓶颈 910C 旨在解决 910B 虽然跨卡互连存在严重问题,但是组合两个芯片设计仍然可能存在互连带宽的限制。来自 Huawei Central 研究表明,910C 的 die-to-die 带宽仅为 Nvidia H100 的 1/10 至 1/20。而且这个瓶颈可能会影响大规模 AI 训练任务的效率主要表现为性能不能根据裸片的数量进行线性扩展,表现为两个裸片一般不能达到单个相同技术裸片性能的两倍,尤其是在需要高带宽的情况下,比如训练大型语言模型。(LLM)。与此同时,不同裸片之间的数据传输也会带来额外的延迟和功耗。
除上述技术层面外,在生态系统和市场方面,众所周知,华为和盛腾芯片属于盛腾计算。 MindSpore 的 AI 虽然框架在不断发展,但是仍然不能和英伟达相处。 CUDA 与平台相比较。
比如 Unite.AI 分析指出,MindSpore 成熟度和广泛应用程度较低,可能会限制开发者的选择,尤其是对于长期来说。 AI 训练任务,这可能会导致 910C 英伟达落后于软件支持和开发者生态系统,从而降低了在实际应用中的效率。
最后,更重要的是,根据这一点, SemiAnalysis、TechInsights、WCCFTech 等待拆解、分析和报告确定,尽管升腾 910C 部分由中芯(SMIC)制造,但受良率限制(据报道,华为升腾芯片的良率仅为 32%,也有报道称,升腾 910C 良率已经提高到近期 40%,但仍低于 60% 行业标准)和产能,其绝大多数仍然选择台积电。 7nm 工艺制造。
归根结底,国内晶圆代工厂,比如中芯,虽然已经掌握了技术。 7nm 工艺,但与台积电相比,在先进工艺的良率、稳定性、大规模量产能力、配套设备和材料生态等方面还存在差距。特别是像升腾 910C 这种尺寸较大,技术复杂。 AI 芯片,对制造工艺要求较高,中芯在满足其大规模、高良率生产方面仍面临挑战。
因此,即使有国内制造的选择,华为仍然专注于依靠技术更成熟、产能更稳定的台积电,以确保供应的稳定性和产品特性,这凸显了中国在先进制造过程中“卡脖子”的困境下,通过第三方渠道获得晶圆。
此外,昇腾 910C 关键部件,如 HBM 根据韩国供应商三星的主要来源( SemiAnalysis 称,大中华区主要使用三星。 HBM 独家经销商 CoAsia Electronics 向 ASIC 设计服务公司 Faraday 发货 HBM,后者再委托 SPIL 选择便于后续提取的低熔点焊料,将其与便宜的焊料结合。 16nm 逻辑片一起“封装”,最后运到中国,通过拆焊回收。 HBM 使用)。众所周知,这种以避免为核心目的的供应链模式,除了合法性的怀疑外,还具有极差的稳定性和极高的风险,是最大的隐患。
国内厂商多点开花,可以降低风险,保持稳定,促进自主性
如上所述,我们不难看出,尽管华为升腾。 910C 在国内应用和替代中处于领先地位,但由于客观或自身原因,芯片本身的性能、生态和关键的供应链模式都存在一定的隐患,这就需要国内其他相关厂商参与替代考试。
事实是,在 AI 在芯片领域,除了华为,阿里、百度、腾讯这些科技厂商已经布局自主研发。 AI 芯片;在纯芯片制造商中,不仅有寒武纪、景嘉微、海光信息等上市公司,还有一批兼顾技术沉淀和创新活力的公司,如芯动科技、瀚博半导体、沐曦集成电路、天数智能芯片、地平线等。
阿里巴巴(含平头哥的含光芯片)属于科技大厂、百度(昆仑芯)、腾讯、商汤科技等。,根据自身庞大的业务需求,开发内部场景使用的内部场景。 AI 芯片。这些芯片主要服务于自己的云平台或业务。虽然它们不直接销售给广泛的外部市场,但它们代表了国内顶级的使用场景驱动ic设计能力,是国产的。 AI 计算系统的重要组成部分。
对属于上市公司的海光信息,其海光信息 DCU 系列产品以 GPGPU 基于结构,建立的自研软件栈完全适应 CUDA 生态学、国际主流商业计算软件、人工智能软件可广泛应用于大数据处理、人工智能、商业计算等领域,已应用于国内超级计算和 AI 训练场景,可以承担部分。 H20 市场需求受到限制。百度、阿里、腾讯等互联网公司已经通过海光认证。 DCU 产品并推出联合方案,打造全国软硬件一体化全栈。 AI 基础设施。另外,国内头部如科大讯飞、商汤和云从等。 AI 企业,已经有大量的模型移植和运行在海光中。 DCU 平台上。
又如寒武纪,作为国产, AI 芯片龙头企业,其思源系列芯片云和边缘计算领域可以部分替代英伟达的产品,尤其是通过第五代智能处理器的微架构,其产品可以满足云训练等场景需求。
除了上述老牌企业外, 2019 到目前为止,一批国产产品 GPU 创业公司也相继成立,并涌现出墙体科技、摩尔线程、兖原科技等。 AI 独角兽的ic设计。
例如摩尔线程,不同于华为升腾,其目标是建立一个更广泛的通用性。 GPU 生态体系。所以,建立了摩尔线程。 MUSA(Moore Threads Unified System Architecture)软件平台统一。最近,摩尔线程正式发布 MUSA SDK4.0.1,它最大的突破就是实现了从ic设计到软件栈的目标。 " 全链路贯通 ",并实现对英伟达达的实现。 CUDA 整体转移,用户的使用习惯不会改变,速度却很快。 15% 以上
对于同为 AI ic设计独角兽的墙面技术,早在 2022 选择于2008年推出 7nm 制程的 GPGPU 芯片 BR100,当时芯片的峰值算率达到了国际厂商销售的旗舰产品。 3 超过一倍,创造了国内互连带宽记录。
由上面我们不难看出,除了华为升腾之外,国内还有许多。 AI 在芯片领域实力不错,而且还有很多可以替代英伟达 GPU 鉴于华为升腾存在的隐患,只有这些公司积极参与,形成多点开花,才能降低风险,保持稳定,在替代过程中促进自主。
写到最后:英伟达 H20 等待近期中国市场的限制,突出了国内替代方案的重要性。但是通过上述,我们认为,中国 AI 芯片替代,甚至未来的自主之路,不能只靠个别企业,更不能长期依靠不确定的回避方式的供应链模式,而是支持包括华为、海光信息、摩尔线程在内的多元化国内。 AI 通过芯片公司的协同发展,构建真正强大、完整、坚韧的全产业链自主生态,正是加速中国的实现 AI 芯片自主可控的正解。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com