
这次又是杭州,QwQ-全球AI开源32B加冕第一荣誉








3 月 6 日本,当投资者再次为阿里股价暴涨欢呼时,一场事先毫无破口的技术革命正在通过 QwQ-32B 模型悄然进行。这款只有 320 一亿参数推理大模型,以四两拨千斤的小参数姿态,性能直追。 DeepSeek-R1,将中国 AI 比赛一举带入了一个全新的层次,与中国共同成为世界各地的中国。 AI 开源双雄赛道。值得注意的是,这也意味着,世界前三名 AI 在开源公司中,杭州独占两席。。
在 DeepSeek-R1 以 6710 在建立行业标杆的背景下,阿里云的攻击不仅是对技术路线的重构探索,也是中国科技企业突破“参数内卷”的里程碑式宣言,这不仅意味着中国 AI 行业开始摆脱参数规模的路径依赖,甚至直接突破 AI “参数崇拜”定律,行业历史悠久。
打破参数迷思
以往的认知中,模型参数的规模与性能密切相关,DeepSeek-R1 的 6710 一亿参数结构曾经被视为行业技术壁垒,但它需要专业级显卡集群的支持, QwQ-32B 加强学习(Reinforcement Learning,RL)大规模应用,即实现了令人难以置信的小搏大。
阿里云的 QwQ-32B 造型之所以能够如此强大,根本原因在于其强化学习能力有了质的飞跃。
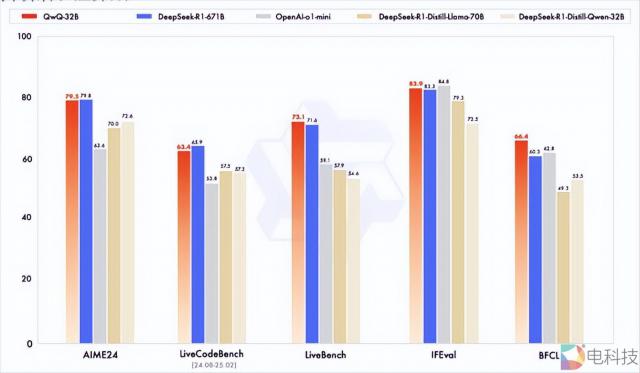
据报道,预训练模型 Qwen2.5-32B 在此基础上,阿里采用了两个阶段加强学习,首先针对数学。 / 精确验证编程任务 RL 训练,再叠加通用能力优化的混合式 RL 迭代。这是一种摒弃传统奖励模式的“硬验证”机制, 32B 参数推理能力突破参数天花板, AIME24 实现数学测试 79.5 分,DeepSeek-R1 为 79.8 分,而能耗成本只是后者的问题。 1/10。
结合动态拓展技术,配合分组查询专注设计,其有效参数利用率(EPU)达传统模型 3 倍,相当于 960 亿密度参数等效性能。这种“参数虚拟化”技术使英伟达(NVIDIA)RTX 4090 显卡可以驱动顶级推理能力,完全改写。 AI 硬件费用公式。

如同海外的 AI 正如大神所说,他们那些笨重的大模型正在浪费大量的金钱。
事实上,通过 QwQ-在可预见的未来,阿里云也客观地开启了大模型的“摩尔定律”,就像过去40年一样,CPU 性价比一路飙升,大模型的降本速度也只会越来越快,显卡决定论在模型行业已经完全失去了市场。
重新定义阿里云 AI 竞赛规则
QwQ-32B 横空出世,正在重构行业认知,首当其冲的是参数转换效率。传统的 Chinchilla 法律开始受到积极的挑战——这是一个用来描述大模型性能和计算资源之间关系的法律,由 DeepMind 首次提出。该定律表明,大型模型的性能提高与计算资源的增加成正比,即模型参数和数据集的大小直接影响其感知、推理和记忆能力的提高。
而阿里云通过 320 实现亿参数等效 960 十亿参数性能证明了“参数密度”比“参数总量”更具战略价值。这一突破促使个人和中小企业可以在天猫上购买可布署的顶级模型显卡。即使在前天,这也是一件难以想象的事。
一张民用娱乐显卡可以跑大模型,对用户来说,意味着什么?比较 DeepSeek-R1 部署费用可以略窥一二。
大家都知道,与其它著名的大模型相比,DeepSeek-R1 部署费用应该算是相当平易近人,但也至少需要 8 张显存 80G 的 A100 显卡,成本至少要小 150 万人民币。而 QwQ-32B 只需 4 张 RTX 4090,不到10万元的成本,这种让娱乐显卡跑大模型的突破,必然会形成 AI 春暖花开的景色,催生了各行各业的景色。 AI 大爆发的应用。
在 Hugging Face 平台,QwQ-32B 首日下载量突破 50 万次,远超 DeepSeek-R1 同期数据。开发者社区检测显示,其工具调用的准确性(BFCL 检测 65.2%)已经接近人类专家水平,可以直接取代部分企业级数据分析服务。
更令人惊叹的是,选择更令人惊叹。 Apache 2.0 协议的 QwQ-32B,上线 48 一小时就衍生出来了 7 一万个社区模型。这种开源是一种标准的玩法,不仅冲击 Hugging Face 在全球推理模型领域,生态位更容易建立中国的话语权体系。
世界开源社区首个登顶世界开源社区
世界上最大的 AI 开源社区 Hugging Face,根据刚刚更新的大模型列表,今天上午刚刚发布并开源。 QwQ-32B 已成功登顶。
突如其来的荣誉绝非一日之功。恰恰相反,正是因为阿里云多年来一贯的开源战略,才成为其背后的决定性力量。
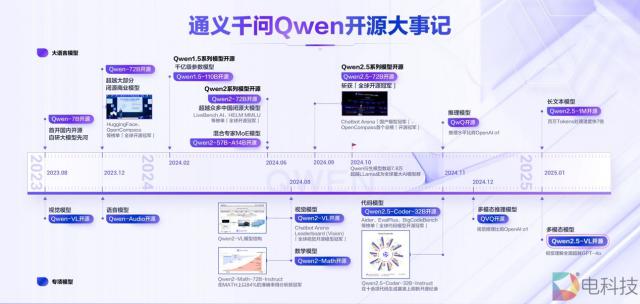
从 2023 到目前为止,阿里云已经开源了。 200 包括大语言模型在内的多种模型 Qwen 以及万相的视觉生成模型 Wan 开源包括文本生成模型、视觉理解等两大基模系列。 / 生成模型,语音理解 / 生成模型、文生图、视频模型等全模式,覆盖范围从 0.5B 到 110B 等待整个数据尺寸,屡次夺得 Chatbot Arena、司南 OpenCompass 等待全球开源冠军的权威榜单。
到目前为止,国内外 AI 开源社区中千问 Qwen 衍生模型的数量已经突破 10 超越美国的万,万 Llama 作为世界上最大的开源模型群体,系列模型。
因此,意义起伏不定,QwQ-32B 其实给我们带来的启示远远超出了技术层面带来的震撼。它证明了中国科技企业已经具备了创造轨道的能力,而不是过去在轨道上追逐。当参数规模的增长受到物理极限时,通过算法创新提高等效参数密度只是一个典型的技术“出现”的样本,这意味着一个更注重算法创新而不是计算率堆积的黎明正在打开。
就像之前达成的行业共识一样, AGI 这条路肯定不仅仅是参数膨胀这条。QwQ-32B 对“基本模型”进行了验证 规模化 RL “技术可行性。正如《南华早报》早前发表的一篇评论文章所说,“阿里巴巴模型能力再次证明,中国正在缩小与美国领先企业的人工智能差距。”
强调综合能力 LiveBench 的评测中,QwQ-32B 以 73.1 分超越 DeepSeek-R1 的 71.6 分,确认中等规模模型的智能涌现不依赖参数膨胀,这一次, 320 一亿参数引发的工业地震,不仅意味着中国 AI 企业首次打破了积累计算能力的路径依赖,开辟了算法密度驱动性能的新战场,同时也显示了中国 AI 产业开始进入历史转折点,从致力于与国外竞争的蝴蝶转变为内部良性竞争。
数据质量、算法创新能力的竞争将更加残酷,当行业集体转向中等规模模型。早些时候,阿里集团宣布将在未来三年投资。 3800 亿元建设 AI 基础设施,下注" AI 云计算",股价由此累计涨幅过大 80%,一举推动阿里完成从电子商务转向硬科技的大战略。
从 QwQ-32B 登上开源社区榜单的当下,再回头看看阿里这艘大船所坚持的航向,毫无疑问,QwQ-32B 这场以小搏大发起的产业变革,不仅重塑了阿里的未来,也将全球化。 AI 权力版图在时代进行了全新的划分——起点,仍然在杭州。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com