
DeepSeek 开源第三枪:加速推理只需300行代码








DeepSeek开源周迎来第三弹-高性能矩阵计算库DeepGEMMMMMM 正式开源!
该工具被称为“AI数学加速器”,是专门为提高大模型训练和推理速度而设计的,在Hopper架构GPU上实现FP8精度下1350。 恐怖算率TFLOPS ,代码简单却性能爆裂,堪称算率领域的“暴力美学”。

FP8精度,计算率天花板再次突破,选择8位浮点(FP8)格式。与传统的32位浮点计算相比,它就像用“小杯盛水”代替“大桶蓄水”,以微妙的精度代替。 速度提升超过3倍 ,完美适应AI场景对误差的容忍。
Hopper 实测13500GPU TFLOPS (每秒1.35千万亿个浮点运算),远远超出市场主流显卡(例如RTX 4090的400-500 TFLOPS)。
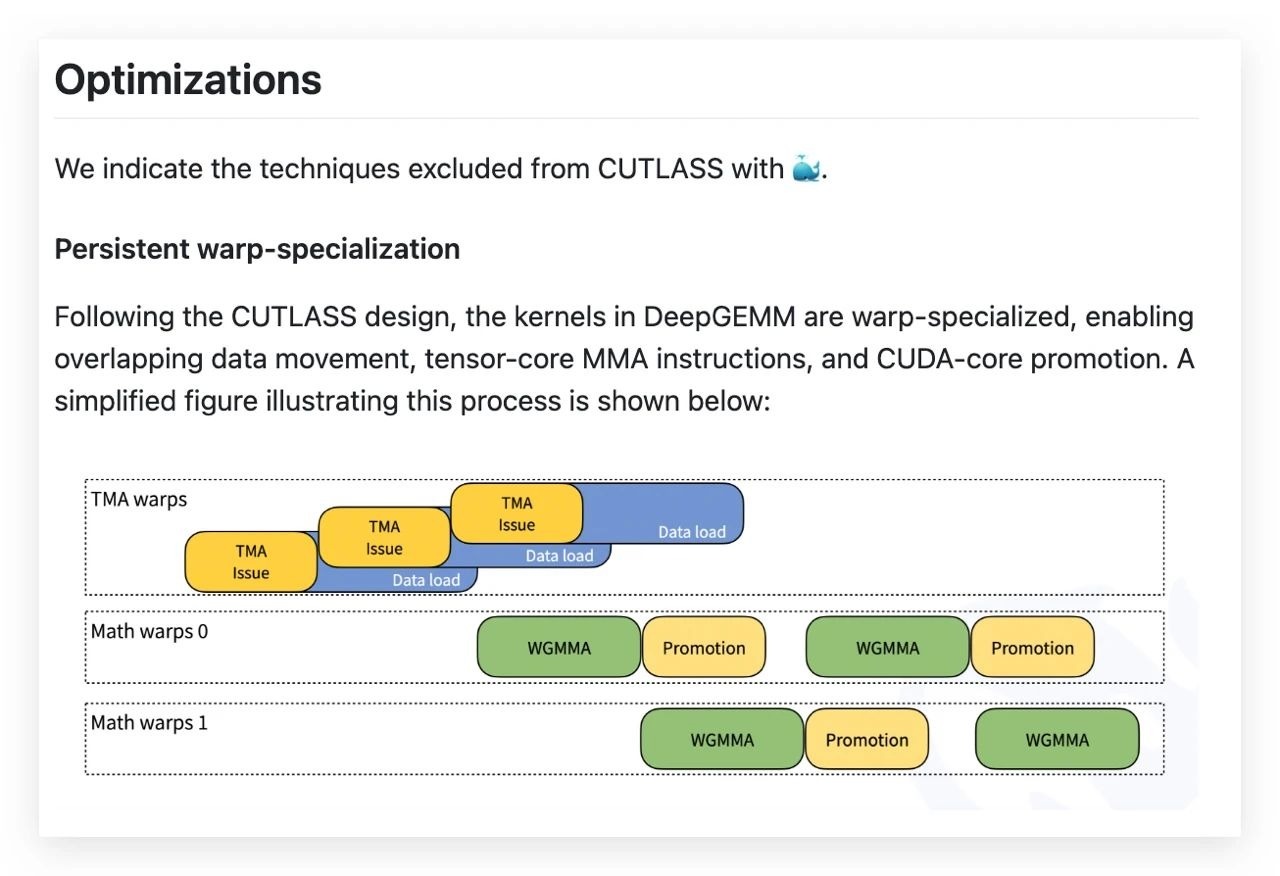
300行代码,只需300行代码就可以手动提升核心逻辑。 ,但是JIT编译通过全流程进行优化 ,比手工调优算法更有效率,真正诠释“少即是多”。没有额外的依赖项,开箱即用,开发者可以快速整合到现在的框架。
双模式支持,适应整个场景计算,支持密集矩阵布局 (统一计算全数据,如全班同一张试卷)和混合MoE布局 (分任务处理,如数学题给专家A、为专家提供语文题B),灵活应对不同模型的需要。
FP8的“省电模式” :低精度计算大大降低了显存的占用和功耗,使万亿参数的大模型也能在24G显存卡上跑出28倍推理。 (参考KTransformers项目)。
增加MoE杀手级别 :双布局连续/掩码 ,处理专家模型计算中的通信瓶颈,让万亿参数MoE推理“快如闪电”。简单的代码哲学 :摒弃冗余设计,专注于底层提升,重新定义高性能计算界限。
伴随着DeepGEMM的开源,DeepSeek R2模型(预计5月份发布)的算率瓶颈将进一步突破。未来,DeepSeek正在构建一套全栈开源Infra系统,从训练到推理,从单卡到分布式。 ,使AI创新不再受到计算成本的限制。
据知情人士透露,DeepSeek 推出速度正在加快 1 月发布的 R1 模型升级版 — DeepSeek R2。两位知情人士表示,DeepSeek 计划在 5 月初发布 R2,具体时间尚未透露。

同时,DeepSeek 今日也重新开放 API 在此之前,由于资源紧张,充值入口一度被关闭。现在 deepseek-chat 模型折扣期结束,调用价格调整为每百万输入。 tokens 2 人民币,每百万导出 tokens 8 元。
本文来自微信公众号“PConline太平洋科技”,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com