
DeepSeek产生鲶鱼效应,中国的算率市场呈现“四变”






DeepSeek-R1问世,大模型竞争开始了。性价比的第一枪。
Meta、OpenAI等国外大型头型制造商纷纷复制或变相降价。OpenAI发布于DeepSeek-R1晚两周。 o3-mini模型,与上一代相比,o1-mini的定价降低了。超6成,o1模型比上一代完整版便宜。超9成。
国内大型厂商也迅速做出反应。二月十三日,百度宣布文心一言将于四月一日发表。全面免费开放。文心一言以前采用基本版免费、标准版收费的方式,标准版定价59.9元/月,连续包月优惠49.9元/月。
这场看似只是价格竞争,实则背后蕴含着更深层次的较量,它不仅仅是价格竞争,技术水平较量,更是对的用户市场的争夺。
中国计算率市场在这场没有硝烟的商业战争中正经历着深刻的变化。
近期发布的2025年中国人工智能计算能力发展分析报告(以下简称《报告》),发展中国计算率。四大变化,把“背后”搬到“台前”。
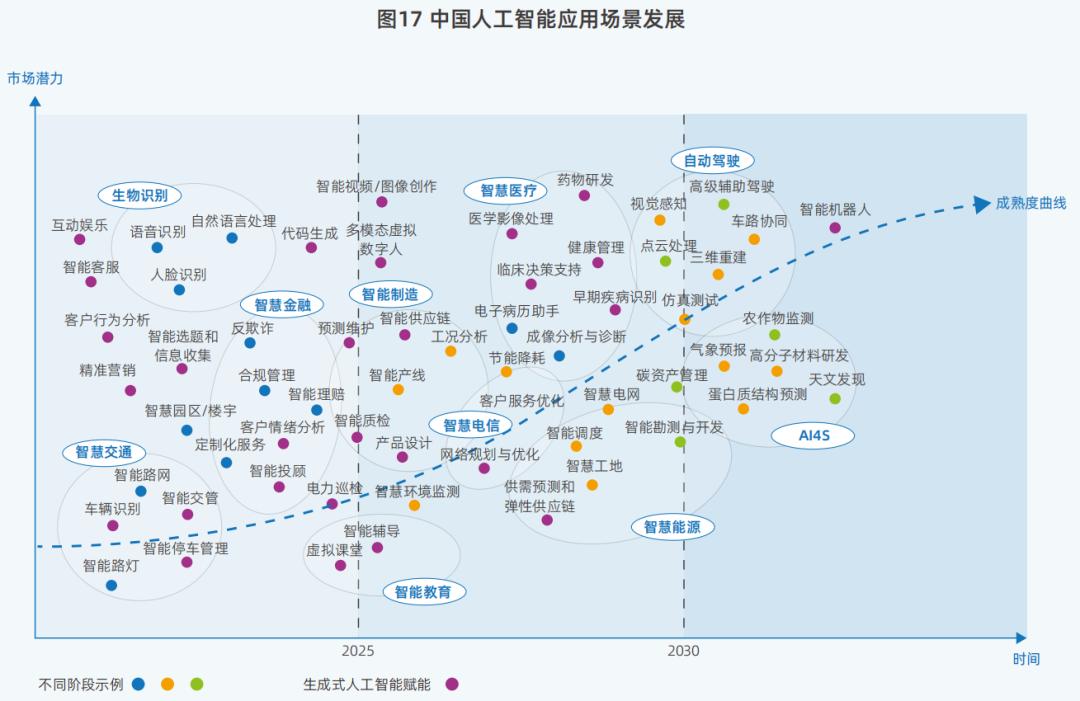
01 计算效率的变化:大模型由“大力创造奇迹”转变为“四两拨千斤”
最大的变化体现在计算效率上,DeepSeek通过算法优化,大大减少了对高端GPU的依赖,突破了传统的“计算军备竞赛”路径u200c。
DeepSeek能够实现高性价比的核心因素之一是模算效率的显著提高。
根据DeepSeek的论文,DeepSeek-R1训练费用只有557万美元,不到OpenAI同类产品。5%,但是,它可以在数学竞赛、代码生成等任务中进行。超越GPT-4模型。也就是说,DeepSeek-R1以较低的算率成本投入,也可以实现高性能输出,即模算效率更高。
模算效率在这里(Model Computation Efficiency)也就是说,AI模型在实践和推理过程中用于衡量模型精度和计算资源利用效率的综合指标,反映了模型在特定硬件平台上以最小的计算率消耗实现最高性能的能力。
DeepSeekR&D模式“四两拨千斤”,对算法创新、结构优化和资源的高效利用更加重视,这可能会带动业界对模算效率的追求。中国IDC副总裁周震刚刚在一次采访中,大型模型制造商的注意力将从追求参数的规模转变为追求模型训练、推理和部署的性价比。
另外,使用DeepSeekMoE(混合专家模型)架构在相同参数下,Dense架构的计算成本更高,从而达到更高的成本效率。高级副总裁刘军在一次采访中回顾:“从去年开始,我们发现基于Dense架构模型,然后进化到训练一个模型。超过五千亿,一万亿参数在当前技术标准下,所需的计算率、时间、信息量都无法实现。有些企业已经做出了评估,在这种情况下,每年需要20万张卡训练,可以高质量地训练一个万亿的Dense模型。”
所以,MoE在核算成本、模型性能等方面所表现出的优势,可能会导致业界对这种结构的一波模仿借鉴。
目前,公司接入DeepSeek模型主要有两种策略。一方面,国内大型模型制造商、芯片制造商、AI硬件制造商、运营商、AI应用开发商等DeepSeek模型671BB相继接入满血版;另外,一些企业会根据自己的业务需要选择访问DeepSeek参数量较小模型,或选择蒸馏DeepSeek模型将其与自己的模型结合起来,从而提高模型性能,降低应用成本。
这种多形式、多参数模型的协同发展是大模型生态应有的状态。在浪潮信息高级副总裁刘军看来,将DeepSeek-R1模型的能力蒸馏到一些小模型上,实际上是促进AI技术的传播。
02 计算结构的变化:智能计算市场井喷,推理计算率成为“抢手货”
关注整个算率市场,我们可以发现第二大变化,国内智能算率规模正在迅速扩大,需求结构也在重塑。
报告显示,2024年中国智能计算率达到725.3EFLOPS,近五年来,同比增长74.1%,达到最高峰值。。近几年来,中国的智能算率规模也是如此最快的扩张速度的一次。
与国内通用计算率相比,智能计算能力的增长已经达到同期通用计算率的增长。3倍以上。2024年中国通用计算率为71.5EFLOPS,同比增长20.6%。
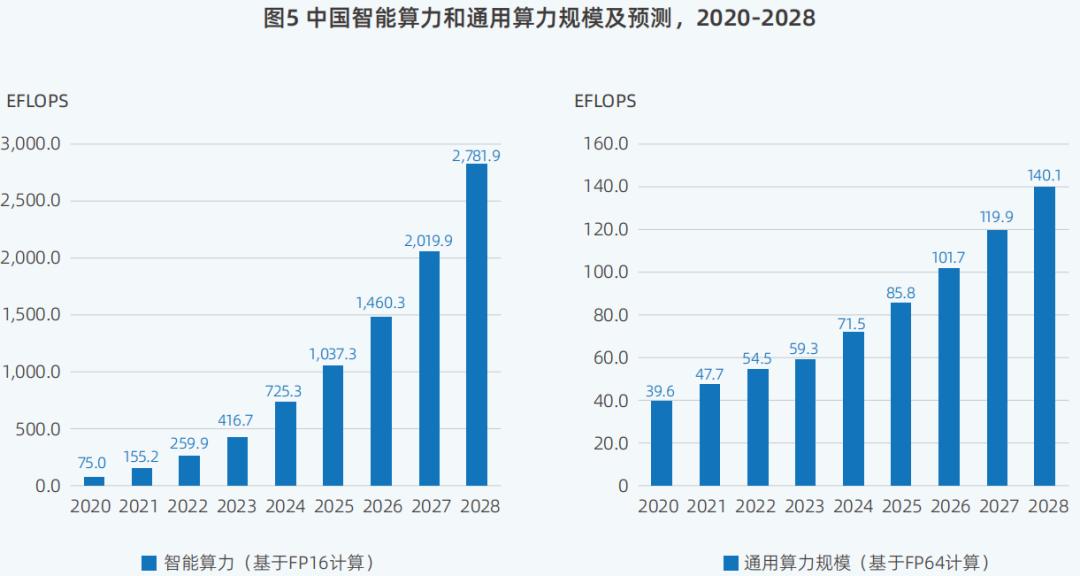
这意味着,在过去的一年里,AI芯片、AI服务器、AI培训、AI推理和AI应用的市场规模也在迅速扩大。例如,2024年中国AI将加快计算服务器的市场规模190亿美金,同比大幅增长86.9%。
尽管以前业界对大型模型的看法。Scaling law(规模法则)是否失效有争议,但是在当今AI发展的过程中,它仍然占有一定的比重,主导地位。那也是推动AI计算能力需求持续增长其中一个主要原因。
根据杰文斯谬论的说法,《报告》显示,DeepSeek实现的算法效率提高并没有抑制计算能力的需要,相反,推动了更多的用户和场景,大型模型的进一步推进普及和应用落地。同时也有助于AI产业重构产业创新范式,加强数据中心、边缘和端算率建设。
然而,单独堆叠训练计算能力的策略并不能一劳永逸。越来越多的大型模型制造商转向加快大型模型开发的多模式能力,并寻找着陆场景。多模式模型应用,AI 随着Agent热潮的出现,知识管理、对话应用、内容生成、营销、视频生成等它们都成了AI生成技术的热门落地场景。
这将极大地激发AI推理在应用落地侧的需求。
比如生成聊天机器人、音视频图像、办公场景中的AI助手等。,在特定的应用场景中更依赖于AI推理能力。因此,报告中预测,随后用于推理的算率规模将超过用于训练的算率规模。
未来全球AI服务器市场,生成AI服务器将于2025年占比,29.6%,提升至2028年的37.7%。
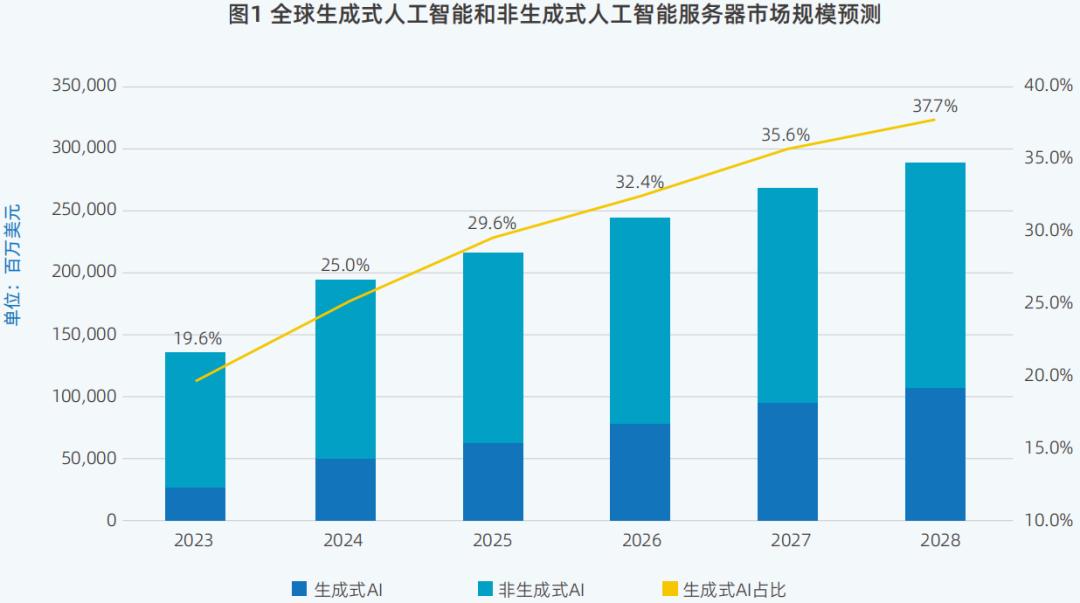
AI技术发展的重要组成部分是在真实需求场景中获得“降低成本”。未来,随着大模型相关技术的逐步成熟和生成式AI应用的不断创新,对推理场景的需求日益增加。推理服务器的比例将大大提高。根据IDC的数据,预计到2028年,推理负载的比例将达到73%。
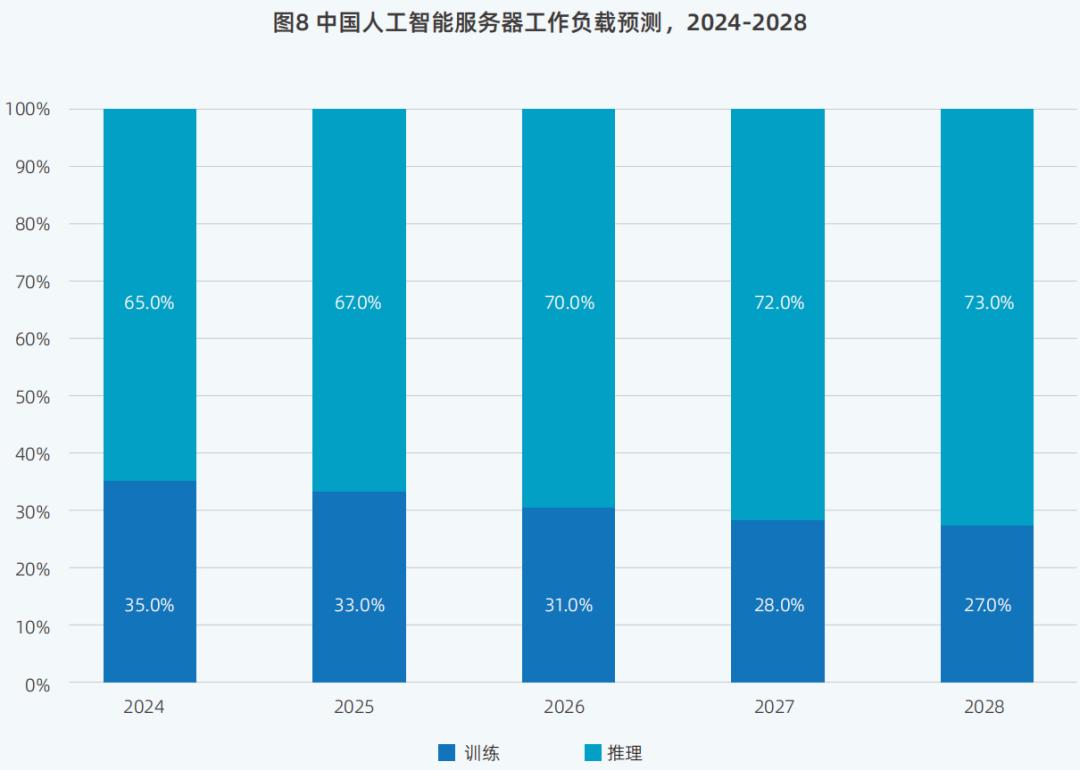
这种发展趋势也得到了浪潮信息业务的证实。据浪潮信息高级副总裁刘军介绍,最近公司收到的订单大部分是推理能力的订单,现阶段推理能力的订单。高投资回报率,带来的顾客体验也比较好,所以推理计算能力的规模将大大提高。
03 计算供给方式的变化:计算供给方式多样化,公司AI选择较多
第三个变化来自于计算率供应的方式。蛋糕做大了,结局分蛋糕的人也多了。
去年有一个非常明显的市场趋势,一方面,AI计算基础设施的供应结构趋于多样化,另外,客户对智能计算率基础设施和服务能力的需求,也在发生着深刻的变化。
在供给方面,它构成了数据中心服务提供商、云服务提供商、硬件制造商和相关AI企业提供AI算率资源的局面。
需求方面的变化集中在两个方面:
第一,生成式AI将进一步推动公司,使用AI就绪的数据中心代管设施,生成式AI服务器集群等。智算服务,这样可以帮助企业缩短部署时间,降低资金成本。
IDC数据显示,2024年中国智算服务市场总体规模已达到50亿美金;预计2025年中国智算服务市场将达到整体规模79.5亿美金,2028年达到266.9亿美金,2023-2028年的复合增长率将达到57.3%。
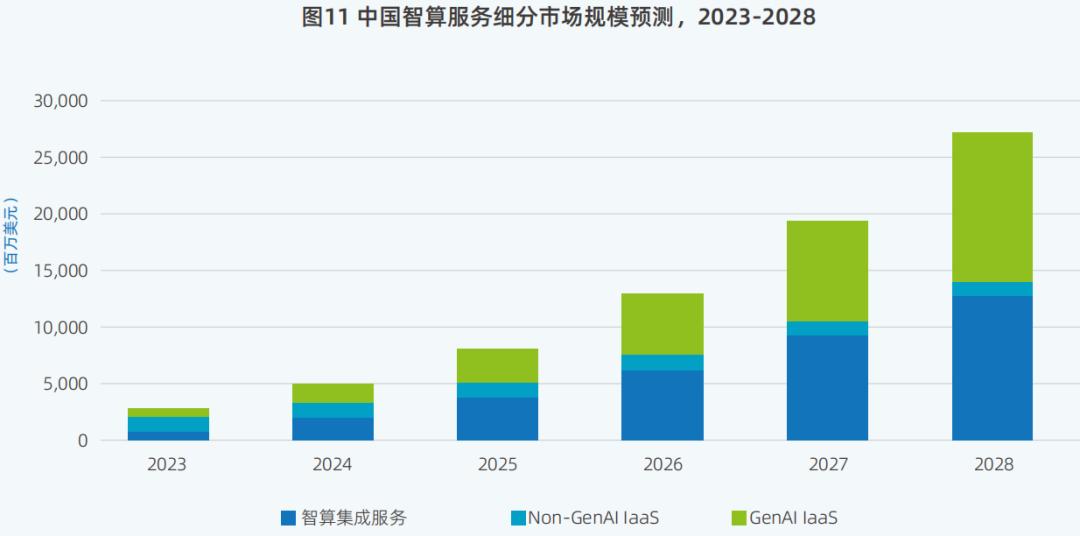
其次,一体机用于推理同时也逐渐受到市场的青睐。
中国IDC副总裁周震刚解释说,早些时候,公司基于云服务部署AI的例子很多,但很少使用一体机。然而,在DeepSeek模型走红后,企业对一体机的需求急剧增加,他们开始关注私有化部署。
所以,在后续的一段时间内,“开源 “一体机”可能成为公司AI服务的爆炸模式。。
根据不完全统计,目前市场上至少已经有了。60家DeepSeek一体机公司包括JD.COM云、移动云、联通云等云服务提供商,以及联想、华为等大型制造商。基于一体机,公司可以通过“开箱即用”快速接入更强大的AI能力的方法。
上周推出了浪潮信息元脑R1推理服务器,它就是其中之一。根据浪潮信息,该产品可以通过系统创新和软硬协同优化来安排运行。DeepSeek-R1满血版671B模型。
根据浪潮信息高级副总裁刘军的说法,“最近两个星期,来找我们咨询购买DeepSeek-R1模型AI服务器,可以带动满血版的DeepSeek-R1。客户数,正直线上升。”
04 城市AI排名变化:京杭沪获得全国AI计算能力前三名
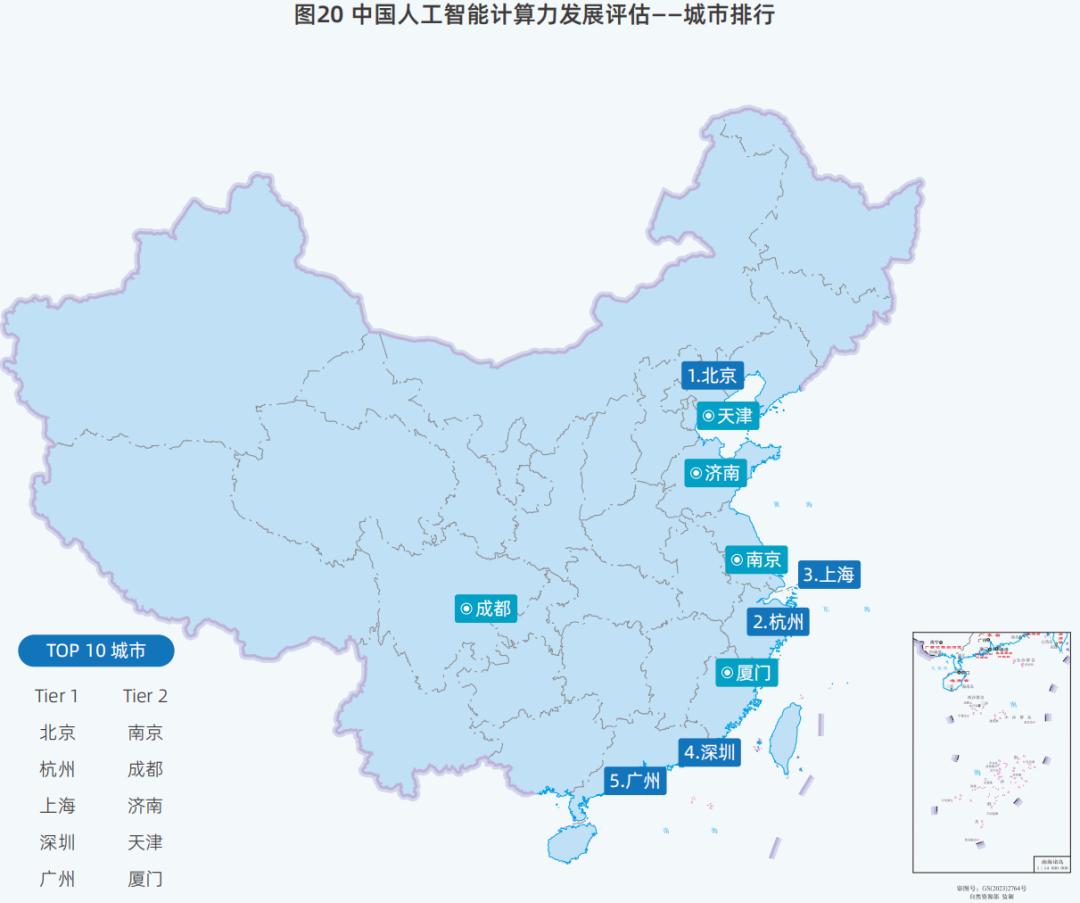
城市AI算率排名是第四大变化。
报告数据显示,中国各城市正在通过加大AI投资、吸收人才、提供政策支持等措施,不断提高AI发展的竞争优势。
可以看出,北京和杭州在中国各城市的AI算率排名中仍然排在前两位,而上海的排名从2023年的第四位上升到第三位。
三个城市的AI战略各有侧重。在这些城市中,北京聚集了大量的大型企业,凭借大量的人才、完善的企业和强大的政策支持,继续排名第一。杭州早在2021年,就提出要成为一个具有全球影响力的AI头雁城市,并出台了许多支持AI发展的政策;上海其优点是正在加快AI国际产业群建设等工作,并且表现出色。
另外,在全国范围内,广州、成都、天津、厦门等城市的AI算率也有所提高。
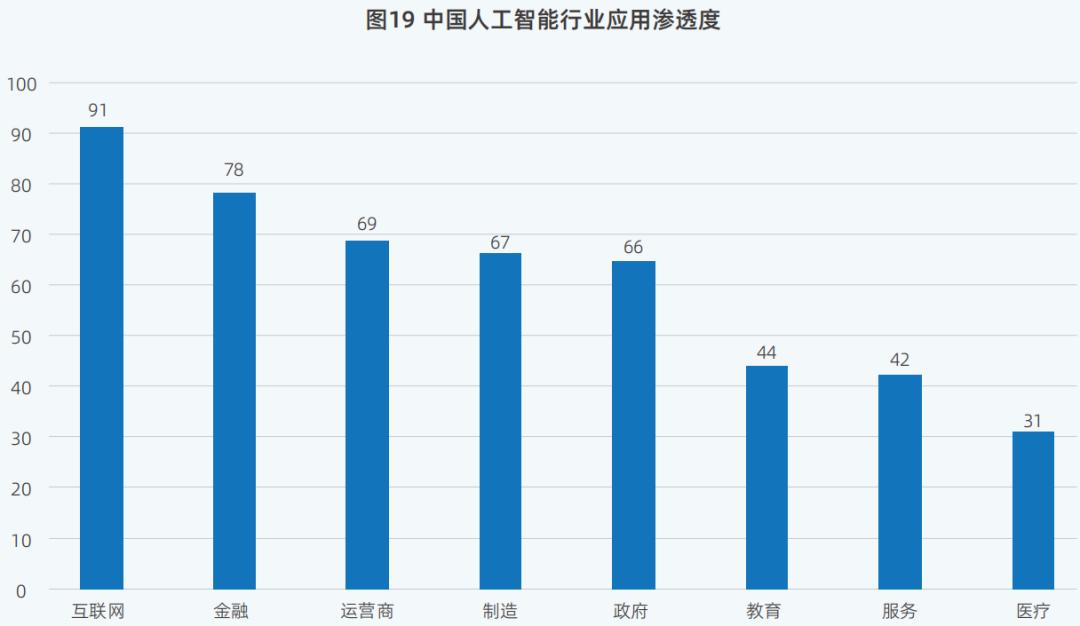
在AI的影响下,AI应用在不同领域的渗透排名也发生了变化。
网络行业排名第一,其AI相关应用渗透率较高。这个行业,AI原生应用已经涵盖了很多场景,比如问答、写作、客服、路线导航、生活指导、学习助手、角色扮演、视频制作、照片公司智能客服、智能销售分析等等。
金融业从2023年的第四名上升到2024年的第二名。与2023年相比,2024年制造业排名更高。这是因为金融业积累了大量数据,可以用于AI培训,为其风险评估提供决策依据;在制造业方面,由AI驱动的机器人和自动化机械可以完成高重复性、高劳动强度的任务。
05 结论:未来计算率的发展既要“扩大”,又要“提高效率”
从这四个变化可以看出,国内计算率产业的发展呈现出蓬勃向上的趋势。同时,更迫切的计算率发展挑战也摆在了计算率提供商面前。未来,如何不断优化计算架构,如何进一步提高智能计算中心的计算率资源利用率,如何完善数据中心的监控系统和故障恢复机制,迫切需要新的解决方案。
对此,《报告》也提出了解决办法,即算率提供商可根据自己的情况选择,计算率“扩大”和“提高效率”并行战略来部署AI算率。
其中,扩容其中包括增加智算中心的数量和类型,重视智算中心建设的区域分布和技术先进性,以提高计算率的供给能力。
提效包括以应用为导向的AI基础设施;提高模型架构效率;提高计算率基础设施架构,包括计算架构、内存层次架构、智能调度算法等。使用优质数据集,构建统一的数据存储和访问接口,提高计算率利用率。
未来,大模型产业底层技术创新加快,场景应用逐步铺开,将为我国算率市场注入新的活力。
本文来自微信微信官方账号 “智东西”(ID:zhidxcom),作者:徐 豫,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com