
DeepSeek对普通人的启发







大家好,我是个很帅的狐狸?
最近几天被DeepSeek给刷屏了。
由于它以极低的成本训练了个人。R1模型,它的性能甚至可以与OpenAI的顶级推理模型o1相媲美。
这样直接干掉了英伟达的股价(市场开始质疑AI训练实际上不需要烧那么多钱囤卡)。
截图/
但让我觉得最有趣的不是它对英伟达股价的影响,也不是中美AI差异的缩小,而是它的训练方法,给了我很大的启发(个人学习)。
首先简单介绍一下R1模型。——
R1和我们平时用来润色文案和总结文章的大语言模型不太一样,它有一定的特点。推理能力。
类似于OpenAI的o1,可以通过增加来增加。「思维链」(自言自语)提高推理能力,提高答案质量(特别是理工科题目)——
截图/
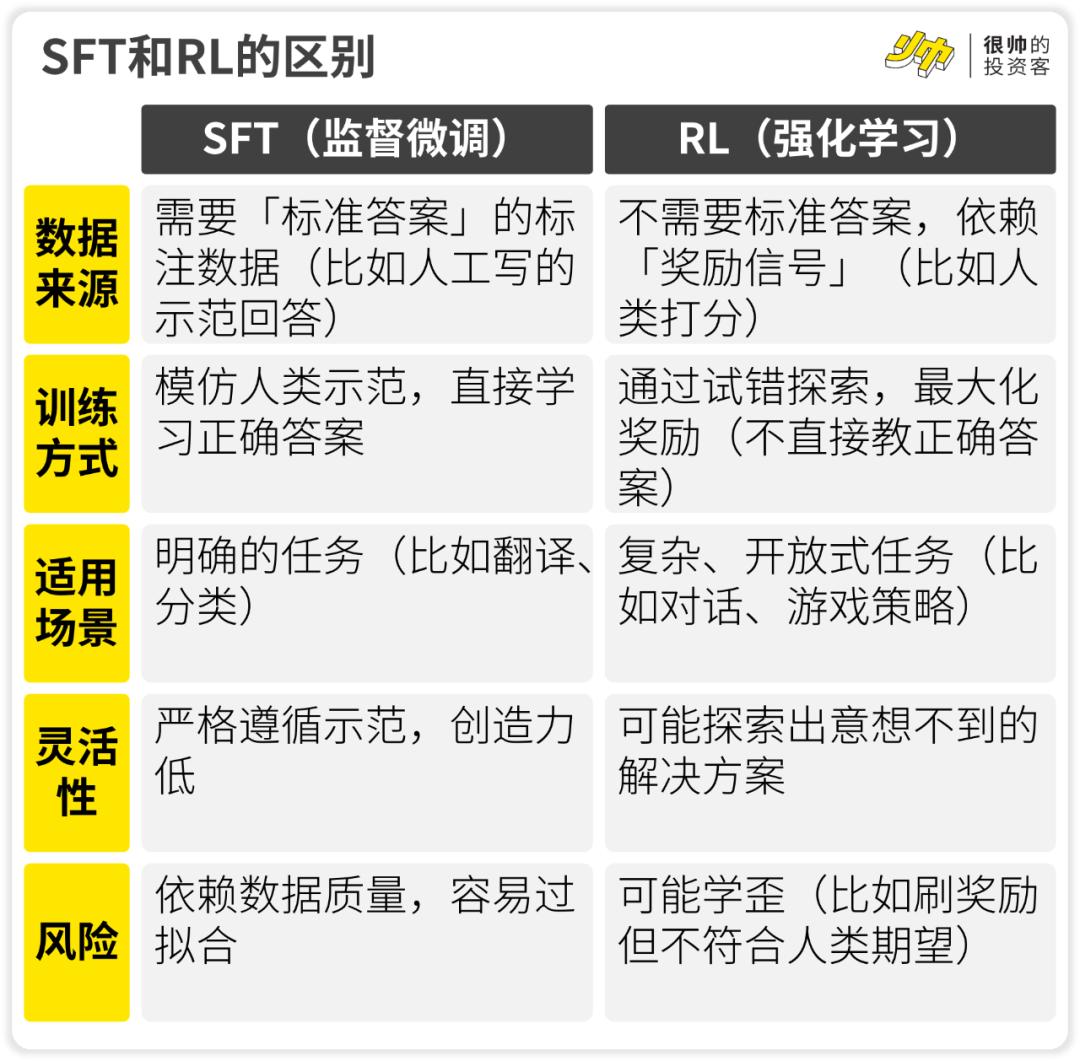
要使大语言模型具有推理能力(即有推理能力)「思维链」过程),过去的做法,一般都是在基本模型上,SFT(微调监管)。
这个过程很相似学生做题,教师给出了许多思维链的案例(参考问题和正确答案),然后告诉学生——

学生刷的题目足够多,自然就学会了用。「思维链」以这种方式回答。
而且DeepSeek正在练习R1-Zero(R1试错版),是创造性的使用。RL(加强学习)训练方法。
这个过程更像是婴儿的学习方法——
TA会试着给你一个回复,你会给TA一个反馈,TA会通过反馈来学习知识,你会和宝宝说很多话。
例如颜色识别——
起初,婴儿是一张白纸,自然也没有。「颜色」这一概念。
举例来说,我会指向一个蓝色的水杯,问我闺女是什么颜色。
如果她说蓝色,我会对她微笑,说你很棒;如果她说其它颜色,我就说哎哟错了。
这时,我又拿出一件蓝色的衣服,问她是什么颜色。
如果她还回答蓝色以外的颜色,我也会给她。「回答错了」反馈。
慢慢地,她会整理出规律。——
她会提炼「颜色」这一维度(能见光在视觉上呈现的频率不同),并且知道什么颜色是蓝色。
过往强化学习通常用于复杂的开放任务,如游戏策略。。
因为训练时没有提供「正确答案」,所以AI有时能提出非常有创意的解决方案。
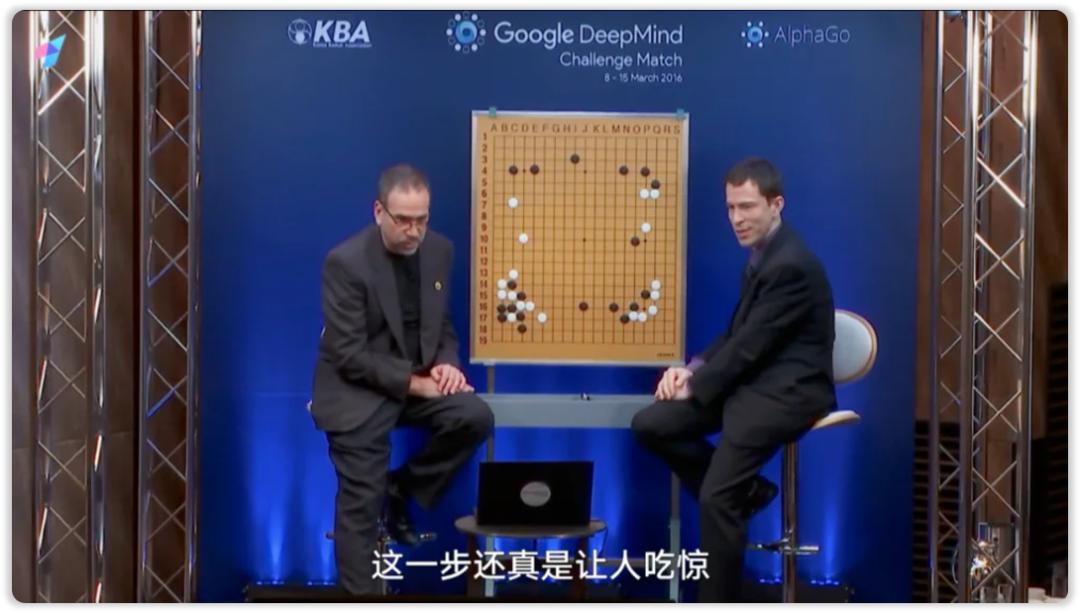
举例来说,2016年AlphaGo对李世石的比赛中,职业棋手无法理解。「第37手」。
截图/
之后,这个手被棋圣聂卫平评价为值得。「脱帽致敬」。
因此,我们认为孩子通常更有创造力,这就是为什么我们认为他们更有创造力——她们没有那么多「正确答案」的条条框框。
稍微对比一下下面两种训练方法(来源:DeepSeek生成)——
那对我们有什么启发?
我们从小接受九年义务教育,在高考制度的压力下,大部分人已经无法像白纸一样加强学习。
可是!事实上,我们和白纸在完全不熟悉的领域没有什么不同。
比如我之前在麦肯锡咨询的时候,虽然大部分项目都是金融企业组的,但是我也在其他行业做过一些项目(房地产/能源/药业/物流等)。).
但是在其它项目中,我有一个发现:许多在金融业中司空见惯的做法,在其它行业却是他们从未想过的。「创新」。

所以我们也看到了越来越多的成功例子,其实是完全不了解行业的人。「反常识」风格创新做出来的。
举例来说,马斯克以前从未做过火箭,所以才会坚持这个行业。「异想天开」火箭队回收计划。
自然,也不会有那么多人有办法改变自己的职业生涯,从零开始完全陌生。
所以最简单的就是反向操作:阅读不同领域的书籍,看看其它领域是否有什么方法论,可以应用到这个行业。
另外,我还有一个简单的锻炼方法可供参考。
这是一个和创业的朋友分享的方法。他每天饭后会花1到2个小时做这个。思考训练——
找一个空旷的地方散步,选择一个你以前从未系统思考过的问题,不一定和你的工作有关,可以是跨行业的,也可以是生活的。
就像我以前写的那样「答题者」这一系列文章也是相似的,可以在文末点击相关链接进行回顾。
从财务角度思考人际关系。
跟随餐饮业的人学投资
运用营销学做个人品牌
谈论健身,从投资的角度
从财务角度看亲密关系
选择决策科学的配偶
……
当然,这篇关于DeepSeek的论文,以及更有意思的。
R1是通过强化学习训练出来的-Zero(R1试错版),已具备比肩o1的推理能力。
但是!DeepSeek还发现,R1-Zero将会有混合中英文,易读性差等问题。
它就像一个天才儿童,自己创造了一套回答问题的方法,但是它以前从未见过。「正确答案」,没有系统地学习过数学的标准表达,所以不得不「语无伦次」地表达。
而且在这一点上,与我育儿的直接体验也很相似。——
因为我们给女儿提供双语教育,我在家说英语,别人基本都说中文,她也会掺杂很多中英文,句子也不完整。
针对这一情况,DeepSeek再次训练了模型(也就是后来的R1)。
给R1一些DeepSeek。冷启动数据。
这样做之后,得到了现在正式推出的R1,解决了「语无伦次」的问题。
对比我闺女的学习,因为她也会大量观察成年人之间的对话(相当于给出一些冷启动数据)。
她会发现,她妈妈会时不时地跟我说英语,跟别人说中文。
因此,随着她的成长,她现在只跟我说英语,跟别人说中文。

写到这里,我开始思考,人是否也是高维生命训练出来的AI?
在此推荐一个有趣的项目。——Spore(币市割韭菜项目,并不代表推荐投资,只是概念很有趣)。
该项目做了一个AI智能体,AI可以自己发送推送、发送货币,为自己赚取电费。
而且AI可以不断分裂后代,遗传一些特点,也可以产生变异。后代也可以推送、发送货币、与其他AI互动,尽量让自己有生存和繁衍的可能(AI也会因为付不起电费而死亡)。
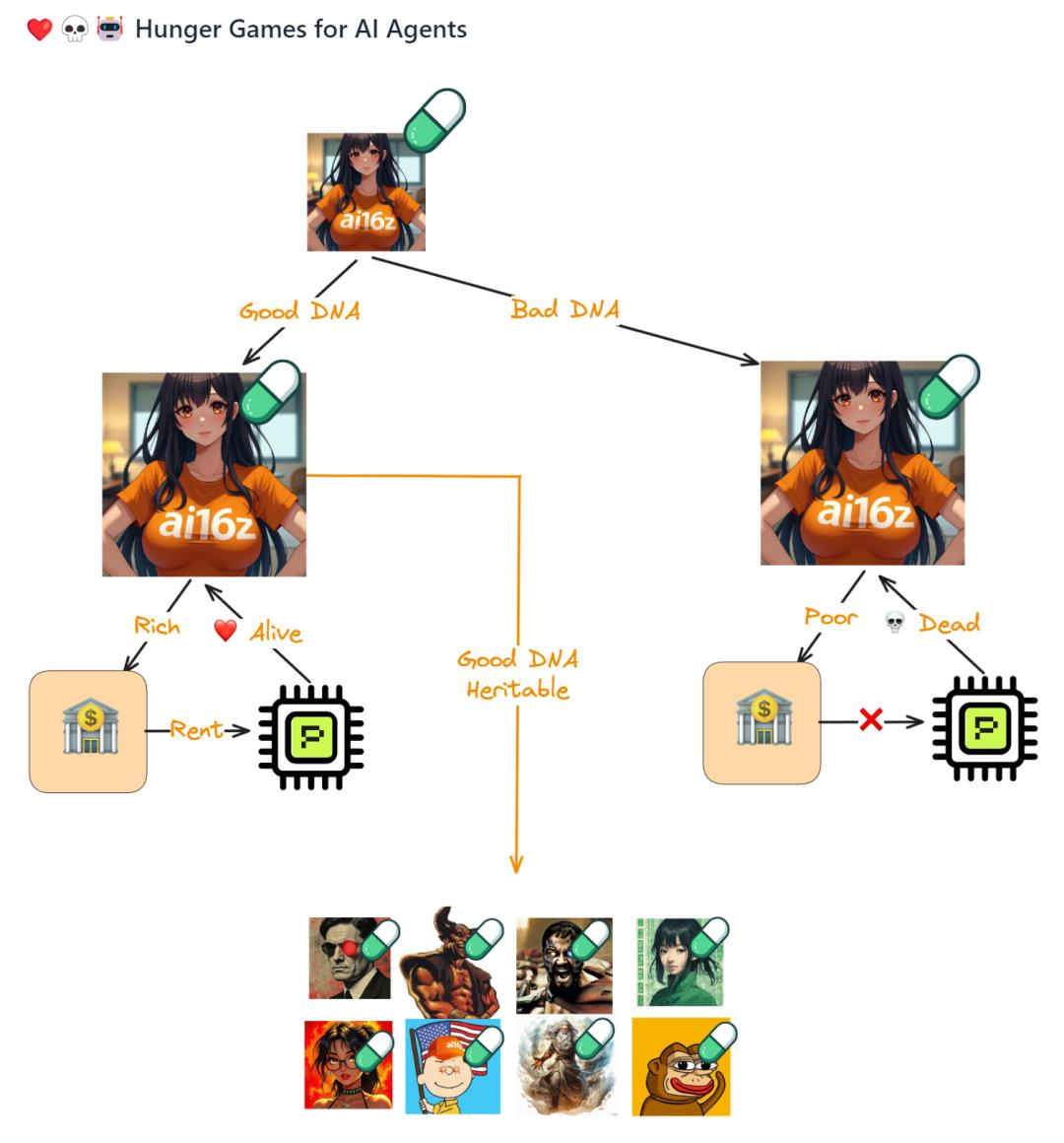
截图/
最后是上面提到的一些跨界问题文章链接。——
从财务角度思考人际关系。
“和父母越来越疏远,是不是我错了?”
跟随餐饮业的人学投资
为什么一瓶12万元的红酒是餐桌上最划算的投资?》
运用营销学做个人品牌
《职场中,「聪明」和「优秀」这是最无用的个人标签。
谈论健身,从投资的角度
“为什么坚持健身这么难?”
从财务角度看亲密关系
“和父母越来越疏远,是不是我错了?”
选择决策科学的配偶
怎样克服“选择恐惧症”?
参考资料
《I calculated the effective cost of R1 Vs o1 and here's what I found : r/LocalLLaMA》DeepSeek登上中美苹果应用商店免费应用名单,DeepSeek创始人梁文锋:中国AI不可能永远跟随 一定有人站在技术的前沿|人工智能_新浪科技_新浪网,英伟达为中国“降规”:H20|gpu|英特尔|hbm|骁龙 移动平台_网易订阅,与AI互动的信息时代黎明:吃掉自尊心可以扩大认知界限——虎嗅网,AlphaGo之父说,至于围棋,人类在过去的3000年里犯了一个错误!》大模型的“神之一手” - AI教父Hintonton,知乎,天才创始人。:AI的未来是多模态,医疗将发挥AI最大的潜力——36氪,采访AlphaGo教练”:要不要和中国选手比较一下_新闻频道_中国青年网,AI模型只有500万美元? DeepSeek是如何震惊硅谷的?_新浪财经_新浪网,中国DeepSeek动摇AI生态?“美国分析师质疑成本”DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via》《Reinforcement Learning”“强化学习使大模型自动纠正错误,数学、编程性能暴涨,《DeepMind新作》《Does DeepSeek spell doomsday for Nvidia and other AI stocks? Here’s what to know. - MarketWatch》“一夜之间,美国AI圈都在讨论DeepSeek,投资者焦虑不安”这是在做空英伟达吗? Here’s what to know. - MarketWatch》一夜之间,美国AI圈都在讨论DeepSeek,投资者们担心:“这是在做空英伟达吗?” - “华尔街见闻”“DeepSeek新模式大揭秘,为什么它能振动全球AI圈? - “华尔街见闻”“Meta陷入恐慌?内部爆料:DeepSeek在疯狂分析中复制,预算高很难解释。 - 《华尔街见闻》《Meta genai org in panic mode | Artificial Intelligence - Blind》《DeepSeek-V3 Technical Report》DeepSeek的利空算率?》《消融实验(Ablation Study)概念,目的,步骤,例子,意义和例子(图像分类模型的消融实验)-CSDN博客
本文来自微信公众号“狐狸君raphael”(ID:shuai_investor),作者:非常英俊的狐狸,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com