
再融资1.8亿美元,这个AI视频平台成功打造了AI产生的第一个虚拟形象。








虽然电子邮件、通信软件、文件共享等工具在当今快节奏、分布式的职场环境中极具价值,但它们仍然只是基本的信息传递。
就这样,视频逐渐成为公司领域强大的新媒体,改变了办公室的沟通和合作模式。视频通过将印象深刻的视觉效果、语音语调或肢体语言融入到数字互动中,填补了文本交流的不足。
Synthesia的创始团队在2017年建立了一个视频平台,以进一步挖掘这种媒体形式的价值,使企业能够充分利用视频进行业务交流和知识共享,并在此过程中将任何员工转化为视频创作者。
01.1分钟项目速度
1.项目名称 :Synthesia
2.成立时间 :2017年4月
3.产品介绍 :
Synthesia提供了一个AI视频生成平台,可以用120多种语言定制头像和画外音,将文字转换成专业视频。
创始人团队4. :
Victor Riparbelli:CEO,曾经在哥本哈根信息技术大学学习;
Steffen Tjerrild:COO,CFO,曾经在斯坦福学校攻读金融硕士学位;
Matthias Niessner教授:慕尼黑工业大学教授,负责视觉计算实验室;
Lourdes Agapito教授:伦敦大学计算机科学系3D视觉教授。
5.融资情况:
2017年10月1日,种子前轮融资达到100万美元;
LDV于2019年4月25日完成。 Capital领先的种子轮融资310万美元;
FirstMark领先的1250万美元A轮融资于2021年4月20日完成;
Kleiner于2021年12月8日完成。 在B轮融资中,Perkins领先5000万美元;
在Accel领先的C轮融资中,2023年6月13日完成了9000万美元;
New将于2025年1月15日完成 Enterprise 1.8亿美元的D轮融资由Associates领导。
02.从“好莱坞”到“企业通信”
这个故事来源于Victorr 无意中,Riparbelli读到了Matthiashias Niessner教授写了一篇关于AI在视频生成应用方面的开创性论文,这篇论文的内容让他深受启发,他意识到这可能意味着媒体制作过程中的一场革命。
不久后,Victor Riparbelli和Steffen Tjerrild、Matthias Niessner教授,Lourdes Agapito教授与Synthesia一起创办了Synthesia企业,试图成功地将这篇论文转化为商业应用,这无疑是学术界和行业之间的强强联合。
这家公司的愿景是“让一个有创意的16岁少年,只有卧室里的一台设备,才能拍出好莱坞级别的电影”。
当Synthesia仍然使用AI来制造像Snapchat滤镜这样的工具时,Synthesia已经以AI配音工具出现了。 ,该工具采用计算机视觉技术,使不同语言的口腔动作更加自然真实,同时也为公司带来了首批收益。

此后,Synthesia发现,世界上有数十亿人渴望制作视频,但由于不了解拍摄技巧和有限的预算,他们从未知道从哪里开始。
同时,Synthesia也意识到了生成AI视频的真正目标客户,并非现有的视频制作能力群体,而是那些在工作中需要视频但缺乏资源的人。。
Synthesia在有了明确的方向之后,创造了一种商品,虽然质量略逊于专业摄像机,但是价格更贴近百姓,操作也更简单,所以很多业余爱好者都愿意为此买单。
如今,Synthesia已经完全成为面向企业的AI视频平台。
03.公司通信软件领先
Synthesia,从AI语音开始,转变了发展方向之后,它在很多方面都遥遥领先,成为业界公司青睐的AI视频平台。 在AI头像、AI语音和视频剪辑方面,Synthesia的功能主要表现在AI头像上。 。
AI头像
Synthesia可以创建自定义头像,并提供150多个不同风格、肤色、性别和年龄的AI人物。
使用者还可以在外观和服装等方面进行调整,使虚拟图像更符合自己的需要和创意。用户可以通过手机摄像来完成整个过程。
如今, Synthesia已经从一个简单的AI头像发展到支持AI半身像 ,身体姿势和手势也成为虚拟形象的一部分。Expressivessive最新推出的第四代AI虚拟形象。 Avatars更能准确地传达情绪。
AI语音
作为一款领先的公司通信软件,Synthesia的语音效果几乎可以区分真假,就像真人的声音质量、语气和情感表达一样。
顾客可在29种不同的语言中克隆自己的英语声音,录音时间只需5-10分钟。 。
音频结束后,可以用自己的声音建立多语种的个性化内容,与不同语言背景的观众建立更紧密的联系。
该软件支持120多种语言和口音,几乎涵盖了世界上所有主要的语言和方言。不同国家和地区的客户可以轻松制作不同语言版本的视频,并在全球范围内传播视频内容。
视频剪辑
Synthesia可以思考文字,PPT、PDF和网站根据事先设置的模板转换为视频,不需要摄像机、麦克风和演员, 大大降低了视频制作的门槛,节省了时间和开支 。
该软件内置了300多个视频资料,用户可以选择和修改其模板,调整视频中的AI头像、背景图、语音速度、语气等数据,甚至可以微调演讲者的面部情绪。
更为重要的是,Synthesia支持合作制作视频并实时编辑,用户可以为团队创造共享空间。

Synthesia官方已推出Synthesia 2.0可以立即编辑用户完成的视频视频,转录画外音,匹配屏幕截图,并具有强调关键动作的自动缩放效果等功能。
2.0的翻译功能更加完善,用户只需使用Synthesia更新一个视频,后面观看的视频将自动翻译成观众的语言。
Synthesia 2.0重新开始对视频制作的每一步都进行了彻底的改造。,致力于帮助公司大规模创建和共享AI产生的视频。
04.探索AI虚拟图像
AI虚拟图像是Synthesia平台的核心, 目前已有超过20万人使用其225个虚拟图像创建了超过1800万个视频演示,并以130多种语言发布。 。
起初,Synthesia为娱乐业开发了对口型和配音工具。然而,由于该技术的质量门槛较高,需求量较小,企业在2020年改变了方向,为企业客户提供了第一代虚拟形象。
与后续版本相比,第一代商品略显笨重,从多方面看都非常不成熟。
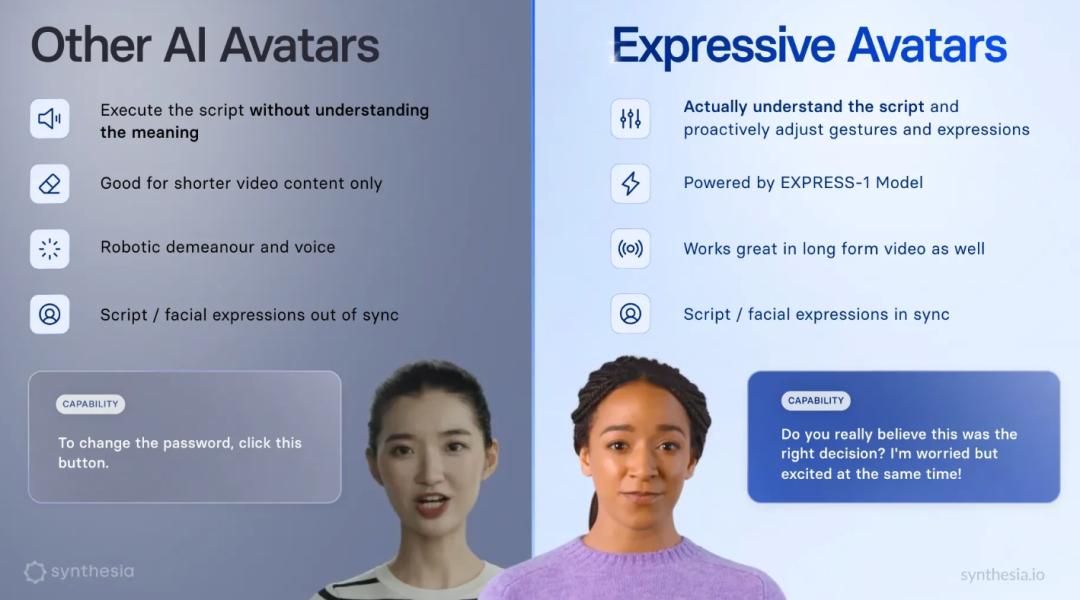
现在,该公司已经推出了第四代AI虚拟形象Expressivee Avatars,这是世界上第一个由AI产生的虚拟图像。EXPRESS-1模型支持这些虚拟图像,可以实现逼真的表演。
具体来说,EXPRESS-1模型采用大型预训练模型作为主要推广性能,结合扩散技术模拟复杂的多模态分布。它能无缝地预测每一个动作和面部情绪,与口语时间、语调和重音无缝衔接。。
Expressive 如今,Avatars可以像真正的演员一样,以正确的语调、肢体语言和嘴型同步演绎剧本,成为“数字演员”。

Melissa Heikkilä分享了她制作数字替身的经验。
她站在绿色的窗帘前,按照规定旋转头部和眼睛,这样系统就可以识别其精确的肤色和面部特征。然后她被要求说:All the boys ate a fish”这句话,使系统能够捕捉到形成元音和辅音所需的所有口腔动作。甚至闲坐的画面也成了AI模型数据的训练。
随后,Melissa Heikkilä为了用这些语音样本来复制声音,被要求用正常、激励、愤怒、兴奋等不同语气读一个剧本。
总之, 人工智能识别面部动作、微表情、头部倾斜、眨眼、缩肩、挥手等数据点越多,虚拟图像就越真实。 。
Synthesia表示,在最新1.8亿美元融资的支持下,希望在不久的将来,能够在虚拟空间中创造一个全身化身,进行行走和移动。

然而,随着虚拟形象技术的不断发展,AI不仅重新定义了个性化的表达方式,也逐渐引起了更深层次的社会讨论。与此同时,相关AI语音和AI视频技术的快速发展也带来了相关隐私的担忧。
另一方面,人们越来越意识到AI产生的内容正在蓬勃发展,并将成为传播虚假信息的有力工具。
另外,目前还不清楚深度伪造是否被广泛用于传播虚假信息,以及它们是否会普遍改变每个人的信仰和行为。
AI控制还不完善,科技行业对内容来源的核查还处于起步阶段。因此,消费者在享受科技发展的同时,需要更加警惕,防止在海量数据中迷失。
参考链接:
1. https://www.cnbc.com/2025/01/15/ai-video-platform-synthesia-doubles-valuation-to-2point1-billion.html
2.https://www.synthesia.io/?r=0
本文来自微信公众号“元宇宙之心MetaverseHub”,作者:元宇宙之心,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com