
硅谷炸场,大型“蒸汽机”迎来“瓦特时刻”








在全球AI圈爆炸中,中国的大模型仍然包括硅谷。
两天前,幻方量化的AI公司深度追求(DeepSeek),自己最新版本的推理模型,以及月亮的暗面间隔20分钟相继发布,分别是DeepSeek-R1和Kimi 全新的多模型思维模型k1.5,并且都给出了非常详细的技术报告, 在全球AI圈,“中国双子星”迅速引起关注。
包括英伟达AI科学家Jim在内的社交软件X 包括Fan在内的全球AI从业者纷纷发出自己的感叹:

有关数据显示,与以往类o1-preview模型不同,这一次,两家中国公司正面刚刚OpenAI。 o1,所有发布的o1都是满血版,而Kimi k1.还是有视觉思维的多模态。
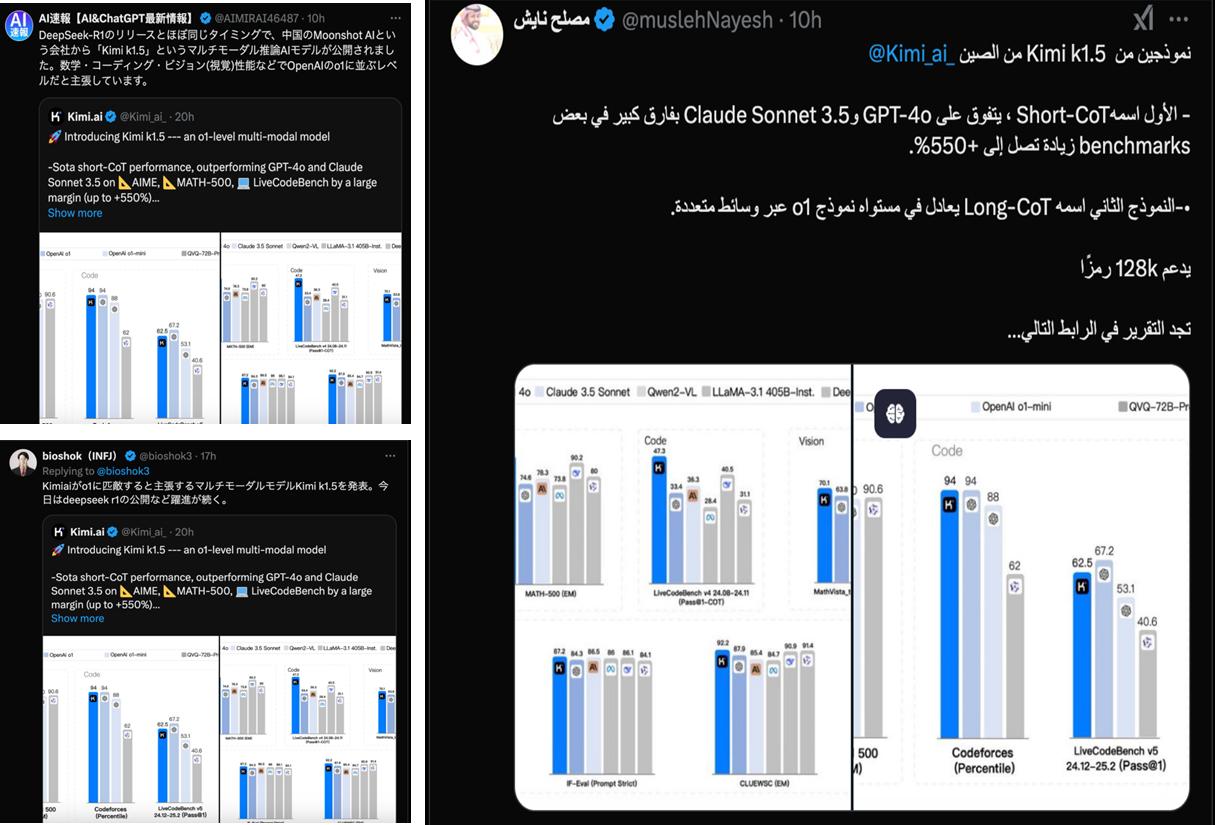
表面上看,中国的大模型在一定程度上又一次在R&D能力上站了起来,而全球AI从业者的“围观”本质上表明了业界对大模型的“蒸汽机”能够尽快展现出自己对“瓦特”的期待。
这台大型蒸汽机,急需一台“瓦特”
大型模型对时代的意义不亚于蒸汽机对工业革命的意义。
然而,就像发明后的蒸汽机一样,经过一段时间的改进,尤其是瓦特的改进,它逐渐成为工业革命的驱动力一样,如果大模型的“蒸汽机”想要取得巨大的成就,它仍然在不断地改进。
属于它的“瓦特”,还没有到来,所有从业者都渴望这一刻。
参与者越多,“瓦特时刻”出现的可能性就越大。只有一个遥遥领先的OpenAI可能不符合行业的普遍预期。当DeepSeek与之并肩出现时,、Kimi,关键进化的可能性越来越大,炸场AI圈成为普遍预期的必然。

中国双子星《回放DeepSeek》和Kimi,他们的发布模式有很多相似之处,都集中在强化学习上。(RL)作为核心驱动力(即在很少标注数据的情况下,模型推理能力大大提高)。
具体而言,两者都不需要像实现方法那样进行。 MCTS 这样复杂的树木搜索(只需要线性化思维轨迹,然后进行传统的自回归预测),不需要配备另一个昂贵的模型副本的价值函数,不需要密集的奖励和建模,只需要尽可能多地依赖事实和最终结果。
显然,这些都在提高推理模型的运行效率,减少资源需求。有趣的是,这也是瓦特最初对蒸汽机进行改造的方向,他在许多改造中完美地实现了这些目标。
历史,总是惊人的相似。
值得一提的是,OpenAI萨姆·奥尔特曼也加入了中国双子星爆炸的过程,但他发挥了一贯的“阴阳”技能,“AGI下个月不会到来”。在赞美甚至狂欢中,他偷偷讽刺社交平台的关注是否过于疯狂。
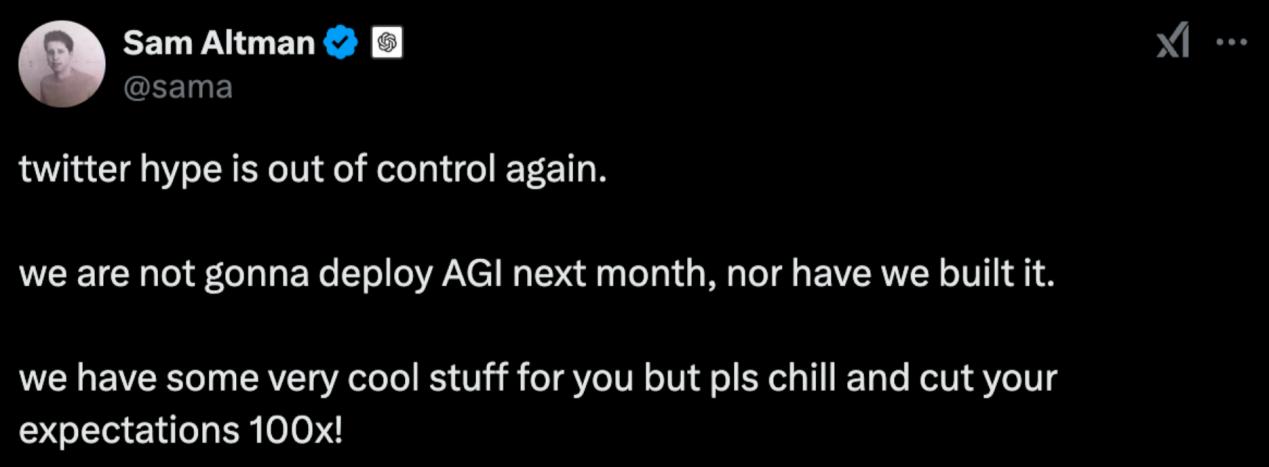
事实上,AGI在短时间内真的做不到,但这并不是阻止全世界从业者欢欣鼓舞的原因。蒸汽机进化后进入工厂需要很长时间,大型模型需要这样的过程才能充分赋能社会进步。正因为如此,每一次缩短这个过程,都值得每一位从业者欣慰。
中国双子星,让业界更有可能看到“瓦特”
具体到技术层面,当我们仔细分析中国双子星的SOTA模型能力,尤其是Kimi,就能发现业内人士的惊喜有充分的理由。
与“蒸汽机”相比,瓦特的改进首先是直接提高运行效率,提高蒸汽转化为机械动力的能力,从而从“测试设备”走向真正的“机器”。
此次发布模式首先也是在推理能力上大幅度飞跃,所有的发布都是真正的“满血版o1”,而不是其他家庭发布的“准o1”,或者是分数相差太远的o1,在绝对实力上是领先的,而不仅仅是一个小小的迭代。
此外,瓦特对蒸汽机的改进仍然改变了机器对不同生产环境的适应性,这与大型模型相对应,是对大型模型多模式进化的推理。
目前,DeepSeek R1只能识别文本,不支持不同的图片识别,Kimi k1.5可以进行一步多模态推理,提高数学、代码、视觉等复杂任务的综合性能,成为除了OpenAI之外的第一个多模态o1模型。
以Kimi k1.5为例:
一方面,模型在数学和代码能力方面的推理能力和准确性(例如 pass@1、EM等数据)大幅领先或超越其它主流对比模型;
另一方面,模型显著提高了视觉多模态任务中对图像中数据的理解、进一步的匹配推理和跨模态推理的能力。
Paper原文截取Kimi,其长文本处理能力大大提高,支持高达128ktokens。 的 生成RL,选择部分进行高效的训练,并且在训练策略上有很多改进,包括在线镜像降低法。
长思维模式(long-CoT)下,Kimi K1.5OpenAI在数学、编程和视觉任务中的表现。 o1的性能水平接近。
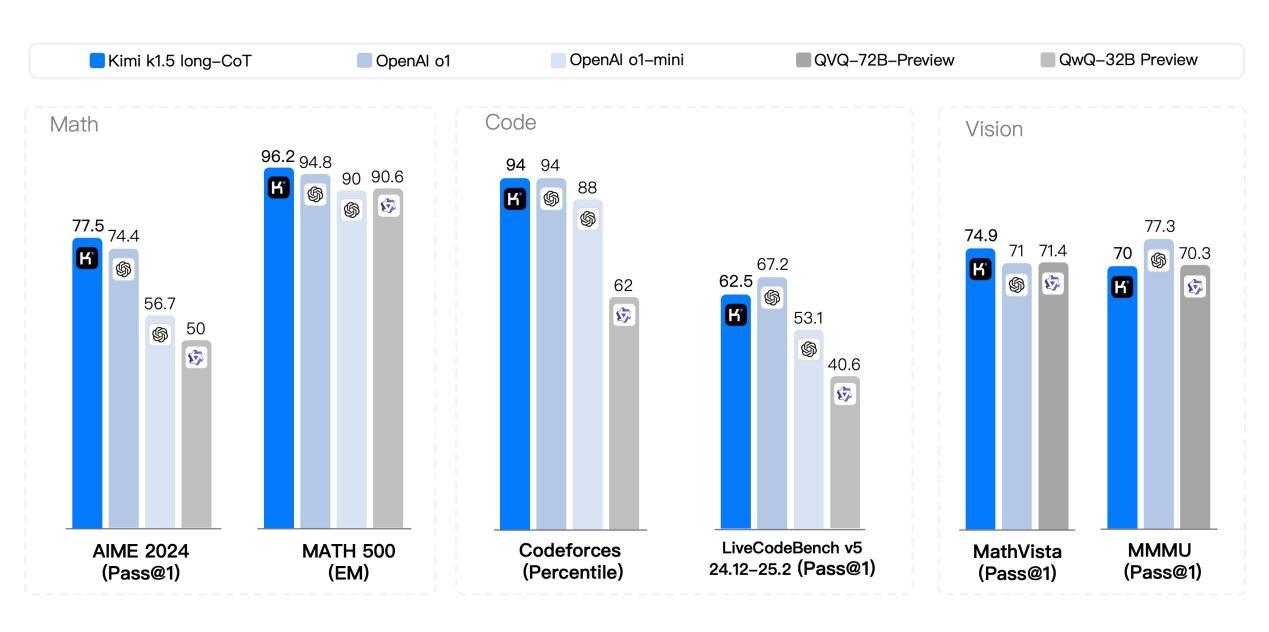
而且到了短思维模式(short-CoT)下,Kimi k1.5 更让业界大吃一惊,在某种程度上实现了“遥遥领先”,其数学、代码、多视觉模式和通用能力大大超越了SOTA模型GPT-4o和Claude的全球范围。 3.5 Sonnet的水平领先550%。
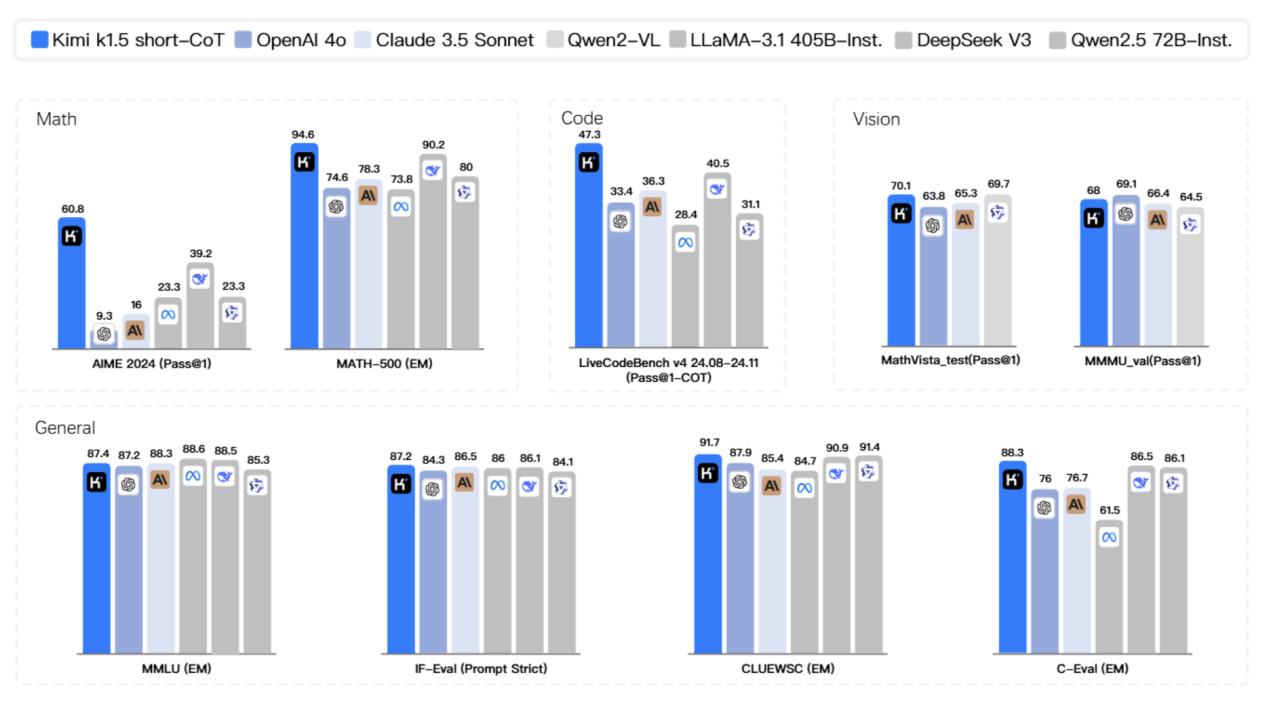
这是因为Kimi的领先优势 k1.独特的“Long2”Short“训练计划,顾名思义,就是先用更大的前后窗口让模型学习长链思维,然后将“长模型”的成果和参数与更小更有效的“短模型”结合起来,再对短模型进行额外的强化学习和微调。
这种行为最大限度地保留了原有的长模型推理能力,避免了“精简模型后能力减弱”的常见问题,同时有效探索了短模型在特定场景下的高效推理或部署优势,是推理模型的重要创新。
“Long2Short“训练计划成功地探索了计算率和性能平衡,改变了OpenAI 有业内人士表示,以时间换空间的做法(牺牲实际应用时的体验来提高性能,这种行为一直存在争议)将是未来新的研究方向。
从更宏观的角度来看,这种创新不仅给Kimi带来了更加抢眼的模型性能,也让大型“蒸汽机”的“瓦特时刻”越来越近。
更加密集的突破,可以争夺“瓦特”
Kimi k1.很明显,5的出现并不是一蹴而就的,而是几次进化迭代的结果,但最引人注目的是迭代速度。
仅在三个月前的2024年11月,月亮的暗面就推出了Kimimi的第一个版本。 K0-math。一个月后,k1视觉思维模型诞生,继承了K0-math的数学能力,并成功地解锁了视觉理解能力,“会计” “会看”。接下来的一个月,也就是K1.5的发布,在数学、物理、代码、通用等诸多领域刷新了SOTA,直接堪比世界顶级模型。
三个月三次突破,密集创新迭代带来炸场的效果和成果。
业界对“瓦特”的期待在关键的历史节点,同时,业界也在争做“瓦特”,大模型只会越来越卷。
美国总统特朗普在中国双子星爆炸后宣布OpenAI。、甲骨文和软银将联合推广一个名为Stargate(星际之门)的项目,在人工智能基础设施领域投资至少5000亿美元,大国AI竞争激烈。
幸运的是,中国已经抓住了基础设施建设和以中国双子星为代表的模型能力建设的机会。这一次,它不会再处于被动地位——在Kimi的规划中,它将继续发挥多模式推理的作用,快速迭代更多模型、更多领域、更具通用性的Kn系列模型。
相信,“瓦特时刻”的大模型,也将是中国大模型获得话语权的时刻。
本文来自微信微信官方账号“响铃说”,作者:曾响铃u200b,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com