
26年前,古董Win98电脑成功运行大语言模型:搭载奔流 IICpu






IT 世家 12 月 30 每日消息,一个名字 EXO Labs 今天,该组织在社交平台上发布了一段视频,展示了一个运行的视频 Windows 98 系统的 26 年老的奔流 II 电脑(128MB 记忆)大型语言模型的成功运行(LLM)的情况。随后,EXO Labs 一篇详细的文章在其博客上发表,进一步阐述了该项目的细节及其“普及人工智能”的愿景。
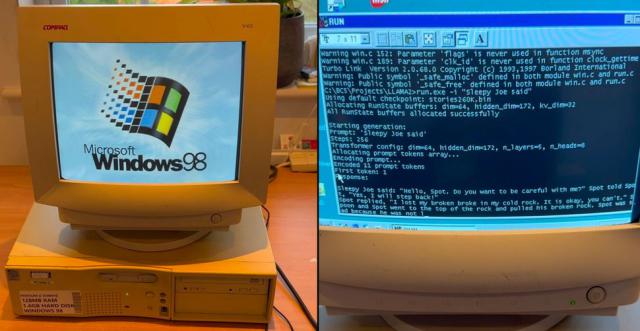
IT 世家人注意到,视频中有一个 350MHz 的 Elonex 奔流 II 电脑启动 Windows 98 后,EXO Labs 运行了基于 Andrej Karpathy 的 Llama2.c 定制纯开发 C 推理引擎,让步 LLM 产生一个关于“产生一个关于” Sleepy Joe "的故事。令人惊讶的是,整个过程运行顺畅,故事的生成速度也十分可观。
EXO Labs 今年,牛津大学的研究人员和工程师组成 9 月亮正式出现,它的使命是“普及人工智能”。该组织认为,少数大企业对人工智能的控制将对文化、真相和社会其它基本方面产生负面影响。因此,EXO Labs 我希望“建立一个开放的基础设施,训练前沿模型,让任何人随时操作”,这样普通人就可以训练和运行几乎任何设备。 AI 模型。此次在 Windows 98 上运行 LLM 壮举,正是对这一理念的有力证实。
根据 EXO Labs 博客文章,他们从 eBay 在上面买了一个老式的 Windows 98 电脑。然而,将数据传输到这台旧机器是一个挑战。他们最终使用了“古老”的以太网端口。 FTP "文件传输已经完成。
更大的挑战在于为 Windows 98 幸运的是,他们找到了现代代码的编译。 Andrej Karpathy 的 llama2.c,它是一种“用途” 700 行纯 C 代码即可在 Llama 2 在结构模型上运行推理工具。借助于这种资源和老式的资源 Borland C 5.02 IDE 和编译器(以及一些小的调整),EXO Labs 成功地将代码编译成可在? Windows 98 上面运行的可执行程序。他们还在 GitHub 上面公开了最后的代码。
EXO Labs 的 Alex Cheema 特别感谢了 Andrej Karpathy 代码,并且对它的性能感到惊讶,称它是以使用为基础的。 Llama 架构的 26 万参数 LLM 时,在 Windows 98 上面实现了“每秒” 35.9 个 token "形成速率。值得注意的是,Karpathy 曾任特斯拉人工智能主管, OpenAI 其中一个创始团队成员。
尽管 26 万参数 LLM 虽然规模很小,但是在这个古老的 350MHz 单核计算机的启动速度相当快。根据 EXO Labs 使用博客 1500 万参数 LLM 在这种情况下,生成率略高于每秒。 1 个 token。而采用 Llama 3.2 10 在1亿参数模型中,速率很慢,只有每秒。 0.0093 个 token。
EXO Labs 目标远不止于现在 Windows 98 设备上运行 LLM。在博客文章中,他们进一步阐述了自己对未来的展望,并希望通过 BitNet 实现人工智能的普及。
据介绍," BitNet 使用三元权重是一种 transformer “结构”,使用这个结构, 70 只需要一亿参数模型 1.38GB 存储空间。这个对一个 26 年前奔流 II 也许还是有些困难,但是对于现代硬件甚至十年前的设备来说,都是非常轻的。
EXO Labs 还强调,BitNet 是" CPU “优先”,避免对昂贵的东西。 GPU 另外,据报道,这种类型的模型比全精度模型更有效率。 50%,而且可以是单一的。 CPU 以人类的阅读速度(每秒左右) 5 到 7 个 token)运行一个 1000 十亿参数模型。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com