
沈向洋教授:AI算率年均增长400%,说卡伤感情,没有卡没有感情。







11 月 22 日举办的 2024 年 IDEA 会议上,IDEA 美国国家工程院外籍院士沈向洋以“从技术突破到产业融合”为主题发表演讲,最新思考了人工智能的“三件套”(算率、算法、数据)。
沈向洋指出,在R&D爆发阶段创新对技术的深刻理解非常重要。他认为,从计算率来看,未来十年 AI 发展可能需要增长 100 一万倍的算率,远远超出摩尔定律所推测的 100 成倍增长,而英伟达则成了 AI 一家行业内最伟大、最成功的公司。
根据 EPOCH AI 数据显示,每年最新的大模型对计算能力的需求都在以惊人的速度增长,平均年增长率超过4倍(400%)。到目前为止,世界已经“烧毁”超过了 1000 万张 GPU 算力卡。
“英伟达突然把自己从硬件和芯片乙方变成了甲方。如果他今天能拿到英伟达的卡,他就成功了一半。”沈向洋说,“说说吧。(GPU)卡伤感情,没有卡没有感情。”
沈向洋现场透露,黄仁勋明天会去香港科技大学接受荣誉博士学位的授予,他准备和黄仁勋讨论一些关于技术、领导力和创业的故事,尤其是关于计算率的发展,讨论未来十年是否会像过去十年一样实现。 100 一万倍的增长。
会后,沈向洋还向钛媒体报道 App 透露,Scaling Law(尺度定律)放缓的原因是 GPT-5 尚未发布,背后主要与数据有关。
据报道,粤港澳大湾区数字经济研究所(International Digital Economy Academy,简称" IDEA 研究所")于 2020 年于微软公司原全球执行副总裁、美国国家工程院外籍院士沈向洋,是一家面向美国国家工程院外籍院士沈向洋的公司 AI 国际创新型科研机构,以及数字经济产业和前沿技术。
IDEA 研究所致力于 AI 以及数字经济领域的前沿研究和产业落地。目前,我院包括低空经济研究中心、计算机视觉与机器人研究中心、AI 金融与深度学习研究中心,基础软件中心,AI 安全性普惠系统研究中心等。
此次,IDEA 发布视觉,具体智能,生成数据,AI for Science、AI for Coding、新技术、新模型前沿研究、低空经济等多个领域的产业落地成果,实现 AI 从技术突破到产业融合。
视觉大模型:IDEA 这次团队会议发布了该系列的最新版本。 DINO-X 具有真实物体等级理解能力的通用视觉大模型,实现开放世界(Open-world)目标检验,无需客户提醒,直接检验万物。在零样本评估设置中,DINO-X Pro 这是业界公认的 LVIS-minival 已经获得了数据 59.7% 的 AP,在 LVIS-val 数据上,DINO-X Pro 还表现出亮眼,得到了 52.4% 的 AP。具体到 LVIS-minival 在每一个长尾类别的数据评估中,DINO-X Pro 获得了稀缺类别 63.3% 的 AP(比 Grounding DINO 1.5 Pro 还要高出 7.2%),在常见类别中取得了成绩。 61.7% 的 AP,获得了频繁的类别 57.5% 的 AP。 产业平台架构:IDEA 团队还推出了行业平台架构。通过大模型底座和通用识别系统的结合,模型可以在不重新训练的情况下使用和学习,支持各种类型。 B 终端应用需求。 具身智能:IDEA 研究院此次连续宣布三项合作:与腾讯合作,在深圳福田区、河套深港科技创新合作区建设福田实验室,聚焦人居环境智能技术;与美团合作,探索无人机视觉智能技术;与比亚迪合作,扩大工业机器人的智能应用。 生成数据:IDEA 该团队开发了情境图谱技术,解决了过去文本数据生成方案的多样性不足。该技术将“指导手册”引入生成数据,以图谱为纲,指导生成情境取样。测试数据显示,IDEA 团队计划可以持续提升大模型的技能,表现超过目前的良好实践。(SOTA);从 token 就消耗而言,平均节约成本 85.7%。当前,该技术内测平台已经开放,通过 API 提供服务。 AI for Science:就预测而言,IDEA 在化学领域开发了多种专家模型,分子特性预测和化学变化预测能力均处于行业领先水平;在数据方面,IDEA 联合晶泰科技发布专利数据挖掘平台,开发了化学文献多模式模型。 PatSight,挖掘药物领域的专利化合物数据时间,从几周缩短到几周 1 小时。 AI for Coding(编程语言):IDEA 研究院的 MoonBit 该团队展示了其强大的开发平台。 AI for coding 感受。MoonBit 它是专门为云计算和边缘计算设计的 AI 云原生编程语言和工具链,已经具备了更多的后端支持和跨平台能力,可以直接在硬件上运行,支持 RISC-V。MoonBit 开源开发平台,将在 12 月份正式开放。 低空经济:IDEA 推出低空服务管理操作系统 OpenSILAS 1.0 Alpha 版,还携手 17 家庭产业合作伙伴发起 OpenSILAS 《低空经济白皮书》创新联合体 发布低空安全系统3.0等。
此外,IDEA 还展示了包括学术大模型和 AI 科研神器 ReadPaper、大型营销创作模式,经济金融领域的大型经济模式,大型运营决策模式,大型投资模式等。 AI 技术和产品。
沈向洋说,以前所有流行的编程语言中,没有一种是由中国开发者创造的,而现在,AI 新的编程范式必将在时代产生,中国开发者将发挥关键作用。
" ChatGPT 展示了一种新的可能性:当技术突破达到一定水平时,可以跳过传统的产品市场匹配 ( PMF ) 直接实现技术市场匹配的过程 ( TMF ) 。"沈向洋说,如果 GPT-5 根据它的估计,它可能需要出来。 200T(200 万亿规模数据。
沈向洋强调,AI 科学研究方法正在改变。“确定方向”(ARCH)到“选择题目”(Search),然后“深入研究”(Research),每一个环节都将被重塑。今日 o1 不但可以做数据、编程,还可以做物理、化学等。
“我认为在接下来的几年里,算法遵循 SRL(加强学习)这条路走下去,一定会有令人惊叹的全新突破。”沈向洋说。
(本文首发于钛媒体 App,作者|编辑林志佳|胡润峰)
下面是沈向洋演讲的主要内容,钛媒体 AGI 编辑精心整理了其中的精彩部分:
今天是 IDEA 第四届研究院在深圳举行。 IDEA 大会。
回顾发展历程,三年前的第一次会议,IDEA 我们第一次向公众展示了研究所的工作成果。在第二次会议上,我们邀请了李泽湘教授、徐扬生教授、高文教授等学术领袖进行深入对话。大家开玩笑说,我们四个叫深圳。 F4。
值得注意的是,这些学者都是我。 90 中国学者最早在20世纪初赴美留学。30年后,我们可以在深圳重聚,这正好印证了深圳作为创新创业热点的独特魅力。
经四年的发展,IDEA 研究所已经发展成为拥有者 7 一个研究所,约定 450 员工的科研机构。在双向选择的过程中,我们强调“科学家头脑、企业家素质、企业家精神”的理念。来深圳,来福田,来福田。 IDEA 他们都想做点什么。
近年来,随着人工智能的蓬勃发展,整个行业充满了期待和期待。在人工智能的发展过程中,“算率、算法、数据”一直是关键因素。接下来,我将从这三个方面详细分享我的观察和思考。
首先从计算率开始。
作为计算机行业的从业者,我们一直见证着过去整个计算行业。 40、50 多年来,计算能力不断提高。最初有著名的“摩尔定律”,英特尔提出每次都要提出。 18 月度计算率翻了一番。
但是,近十年来,随着人工智能,特别是深度学习的发展,对计算能力的需求呈现出前所未有的增长趋势。
根据 EPOCH AI 数据显示,每年最新的大模型对计算能力的需求都在以惊人的速度增长,平均年增长率是4倍以上。
这个数字是什么意思?如果按照这个增长速度,计算能力需求的增长将在十年内实现惊人的增长 100 一万倍。与传统摩尔定律相比, 18 一个月的增长翻了一番,十年也不过是 100 倍的增长。
计算率是关键,计算率就是生产力。为何如此?在过去的十年里,可以毫不夸张地说,IT 无论从哪个角度来看,行业、人工智能行业最伟大的一家公司、最成功的一家公司,都是 NVIDIA 英伟达。
英伟达已经从一个简单的硬件芯片供应商转变为整个行业的核心支柱。现在业内流传着这样一句话:英伟达已经把自己从硬件和芯片的乙方公司变成了甲方,但是如果你今天拿到了英伟达的卡,你就成功了一半。
让我们来看看具体的数据:2023 年英伟达最新产品 H100 出货量持续上升,各大公司争相采购。包括马斯克最近在内的一个拥有者 10 万张 H100 大规模的卡集群。到达 2024 2008年以来,微软、谷歌、亚马逊等科技巨头大量采购。 H100 芯片。
为何需要如此巨大的计算率?它与大模型的发展密切相关。
Scaling Law 告诉我们,大模型不仅参数巨大(从100亿到1000亿,再到1000亿),而且训练所需的数据量也在增加。更重要的是,为了提高模型性能,计算能力的需求会随着参数的平方而增加。这就解释了英伟达过去十年的市值为什么会增加。 300 倍,也说明了“计算率就是生产力”这一论点的深刻含义。
一旦参数这么大,就要能训练出这样的模型,信息量也要增加。从某种意义上说,要提高性能,计算能力的需求与参数的平方有关,这对整个计算能力的需求是巨大的。
这一年我常说的一句话,“说卡伤感情,没卡没感情”。

前不久,我在上海演讲的时候,台下有一个大学校长。老师们应该同情校长,校长也不好。老师说你给我。 100 张卡,我可以做一些科研,给你。 100 张卡,校长上千万就没了。
就职位招聘而言,计算资源已成为一项重要指标。一些企业将使用“千卡人才”、用“百卡人才”来形容人才的规模,真正的顶级人才甚至被称为“万卡人才”。IDEA 研究所已拥有千张卡算率储备,在深圳堪称“小土豪”级别的规模。
这也解释了为什么英伟达在过去十年的市值上升。 300 倍,这是一件难以想象的事,
这种计算能力需求的变化被业界称为从摩尔定律到黄氏定律的变化。黄氏定律不仅体现在硬件计算能力的增长上,也体现了模型训练对计算能力需求的指数级增长。这个问题值得我们密切关注和思考,看看未来十年的计算能力需求是否会保持如此惊人的增长速度。
在此之前,我还在大湾区论坛上提到过去十年计算能力的增长。 100 万倍,有一篇文章写得不准确,他说沈向洋说,未来十年会有计算能力的需要。 100 一万倍的增长。其实我也没说什么,也没看清楚。未来十年的计算能力需求会增加吗? 100 万倍。
明天中午,我有机会咨询香港的黄仁勋博士。黄仁勋博士去香港科技大学接受荣誉博士学位,以后会和我谈技术、领导力、创业的故事。我有机会问他未来十年的发展会不会有机会。 100 一万倍的增长。
其次是算法。

关于算法,自我 2017 年 Transformer 自从架构问世以来,人工智能、深度学习和大型模型的发展基本上都是沿着这一方向,通过堆数据和计算率来推进。但在 GPT-4 之后,我们看到了算法范式的新突破。尤其是 OpenAI 包括多模态在内的新技术推出 GPT-4V 以及最新的 o1 推理学习能力,展示了算法创新的新方向。
令人高兴的是,最近几个月,国内也有一些公司,包括创业公司在内。 o1 这一方向取得了显著进展。
下面我想详细介绍一下算法突破的想法。 o1 在出现之前,大家都在讨论。 GPT 系列,所有的工作都集中在预训练上,核心任务是预测“下一个” token "。在这些技术背景中,高效地压缩所有数据,使模型能迅速地给出答案,实现“一问即答”。
而且目前的范式变革引入了强化学习(Reinforcement Learning)概念,模型具有自我提升的能力。这一新方法的特点是,它更接近人类的思维方式。与以往的快速思维模式不同,现在的模式在给出答案时会经历后训练、后推理的过程。正如学生在解决数学题时会先打草稿,验证一条路径是否正确,如果不正确,就回去尝试另一条路径。
虽然强化学习本身并非一个新概念——比如几年前 AlphaGo 用强化学习打败了围棋世界冠军——但是今天的创新在于它的实用性。过去的强化学习系统往往只能处理单一的问题,就像 o1 这种新系统可以同时解决数据分析、编程、物理、化学等诸多领域的问题。在接下来的几年里,我感觉, Self-Reinforcement Learning ( SRL ) 在这条路上,我们将看到更多惊人的突破,期待 IDEA 研究所和国内研究人员可以在这个方向上有更多的思考和创新。
最终是数据。
在讨论数据之前,我提到大模型的蓬勃发展不仅取决于参数规模的增加,还取决于海量数据的支持。让我和你分享一些关于数据规模的具体数据。

三年前 GPT-3 发布时,使用 22Trillion(22 万亿)的 token 数据。到了 GPT-4 在时代,模型训练中使用的数据增加到了 在不断的训练过程中,12T可能已经实现。 20T。这一规模大致相当于当前网络上可以获得的优质数据总量。未来如果 GPT-5 根据我的估计,问世可能需要。 200T 大小数据。
但是问题是,因特网上已经很难找到如此庞大的优质数据。它引出了一项新的研究内容:生成数据。
为使大家对这些数据规模有更直观的了解,我举几个例子:1 万亿 token 大约相当于数据量 500 万本书,或 20 一万张高清照,或者 500 万篇论文。从人类历史的角度来看,到目前为止创作的所有书籍都可能包括 21 亿 token,微博上有 38 亿 token,而 Facebook 上约有 140T 的数据。但社会媒体上的数据质量普遍不够高,真正有价值的内容相对有限。
就个人而言,一个人读完大学后,真正学到的知识量大概就是 0.0018T,相当于 1000 这本书的内容。假如你觉得自己还没有读过这个量级,也许从现在开始就应该多读一些书。
有趣的是,ChatGPT 等 AI 模型化训练数据主要来自因特网。回顾因特网的发展 40 2008年,大家都热衷于在网上分享信息,现在看来, GPT 准备练习。AI 之所以如此智能,很大程度上归功于我们贡献的数据。另一个值得注意的现象是:无论训练哪种语言, AI 模型,底层的优质数据主要是英文的。这意味着在 AI 英语在时代的重要性可能会像网络时代一样进一步加强。
由于网络数据已经接近极限,AI 要进一步发展,就必须依靠生成数据,这可能会带来新的百亿美元创业机会。
与 GPT 该系列主要使用不同的网络文本数据,新一代模型(例如 o1)需要更强的逻辑,通常在网上找不到这些信息。比如在编程领域,我们需要知道具体的过程是如何一步一步完成的。现在 IDEA 在郭院长的带领下,研究院开展了高质量的培训数据项目,不断为大型模型提供新的“养分”。
我们的数据生成方法不是盲目的,而是基于严谨的方法论。首先,我们建立一个情境地图,并在此基础上生成数据。经过大型预训练,这些生成数据已经取得了良好的效果。
此外,我们还在探索另一个维度的问题:私域数据安全荒岛。由于数据安全考虑,许多私域数据无法直接共享。所以,我们开发了它 IDEA Data Maker,将这两个方面结合起来,通过情境图谱生成新的语料,解决过去文本数据生成方案的多样性不足等问题。该技术将“指导手册”引入生成数据,以图谱为纲,指导生成情境取样。测试数据显示,IDEA 团队计划可以持续提升大模型的技能,表现超过目前的良好实践。(SOTA)模型;从 token 就消耗而言,平均节约成本 85.7%。当前,该技术内测平台已经开放,通过 API 提供服务。
在探讨了 AI 在“三件套”之后,我想分享一下 IDEA 在过去的一年里,研究所进行了探索和实践。特别是大模型的蓬勃发展给我们带来了机遇。
在谈到大模型之前,我将谈谈最近的学习经验,ChatGPT 出来之后,大家都很震惊。ChatGPT 这个产品出来的时候,原本只是几个技术演示,它出来后2个月全球。 1 亿万用户,成了一个伟大的现象。
这一状况打破了我们对产品发展的传统认识。因特网时代,人们常说 PMF(Product-Market Fit,产品市场匹配)。对于这个概念的理解,我多次咨询美团的王慧文。在清华的一节课上,他特意介绍了。 PMF 的含义。
但 ChatGPT 告诉我们成功,它实际上跳过了。 PMF 过程,直接完成 TMF(Technology-Market Fit,技术市场匹配)。如果技术发展到一定程度,就有可能实现这种跳跃突破。
在 IDEA,我们每天都在追求一些极致的技术,我们也在思考:如果有技术,能不能一步到位?当然,这是我们的期望。我们一直在朝着这个方向努力。
沿着 TMF 我想谈谈我们最近特别关注的一个方向:计算机编程语言。作为一个学计算机的人,我自己写了十几种不同的编程语言,在不同的阶段做不同的项目。
在这里,我想提出一个重要的观点:纵观世界,有那么多编程语言,包括小语言、大语言和中型语言,但基本上没有一种语言被中国人发明和创造,被广泛使用。这种情况是有机会改变的。
让我给你举几个例子,解释一下什么是现象级语言。
在过去七八十年的计算机科学发展过程中,不超过十种现象级语言。这里的“卓越”是指至少有数百万、数千万用户使用这种语言进行编程。例如早期的 Fortran,当时是和 IBM 大型机器绑定,做三角计算都要用 Fortran 语言。70 时代出现的 C 语言,是和 Unix 操作系统紧密相连,甚至可以说 Unix 系统就是用 C 建立语言。到了 90 随着时代互联网的兴起,我师哥开发的 Java 语言被广泛的程序员选择,主要用于开发 Web 服务器。但是在过去的十年里,Python 由于方便的科学计算,特别是在云计算平台上的广泛应用,成为主流语言。假如你问问你的孩子学习什么编程语言,很有可能是 Python。
所以,在今天的大模型时代,会不会出现新的现象级语言?我并不是唯一一个思考这个问题的人。举例来说,GitHub Copilot 的创始人 Alex Graveley 就指出,AI 新的编程语言范式尚未形成。编程语言是最基本的技术创新方向之一。
有了语言,我们需要探索大模型的技术创新方向。目前,当模型能力达到一个新的高度时,一个关键问题是:如何将这种能力转化为实际应用?在哪些场景下可以充分发挥其最大价值?
我特别强调,在所有应用方向中 AI For Science(科学智能)的重要性。在现阶段,很难想象有什么比现阶段更重要。 AI For Science 更重要的方向。如果要做人工智能研究,一方面要全力推进大模型技术的落地,另一方面要注意其在科学研究中的应用。
这让我想起了20多年前,我在微软亚洲研究所做了一份关于如何做研究和学习的报告。我把研究工作分为三个不同的层次:ARCH(确定方向)、Search(选择题目)、Research(深入研究,反复探索)。现在,我们希望 IDEA 在做科研的时候,工作可以为中国的科研人员、年轻学生提供更好的支持。
事实上,人工智能的发展对社会有着深远的影响。这个问题太重要了,我们需要认真思考。我们今天要讨论的是 AI 治理问题,包括它对人民的影响,对企业的影响,对控制的影响,对社会发展的影响。

到底是怎么发生人工智能影响的?八年前,人们还在讨论社交媒体的影响力,而今天我们必须讨论人工智能的影响力。
过去十年的发展令人震惊:人类引以为傲的能力正在一个接一个地被发展。 AI 超越。下象棋,下围棋就不用多说了,现在 AI 阅读理解、图像识别、检查等方面的能力已逐渐超越人类。
更令人震惊的是,这些能力的提升不再是单一的突破,而是一般人工智能整体能力的提升,使得人工智能对社会的影响非常长远。
现在,全世界都在讨论。 AI 处理问题。在今年的上海人工智能大会上,我有幸与导师瑞迪教授、布卢姆教授、姚期智教授进行了讨论。
就社会发展而言,我们习惯于使用它。 GDP 去衡量发展水平。但 GDP 事实上,这个概念非常新。以前,农业社会根本不存在。 GDP 成长的概念,因为人们甚至很难解决温饱问题。随着农业社会的发展,每个人都有剩余的产能, GDP 平均年增长仍然只有 0.1% 至 0.2%。在工业社会,这一数字已经增加到工业社会。 1% 至 2%。信息社会的 GDP 平均年增长已经达到 3%、这里所说的4%都是全球大概数字。
然后,接下来 AI 社会发展会发生什么?一些经济学家预测,随着人工智能数量超过人类数量,机器人数量将急剧增加,生产效率将大大提高。在这种情况下 AI 世界里,GDP 平均年增长可达十几个百分点。
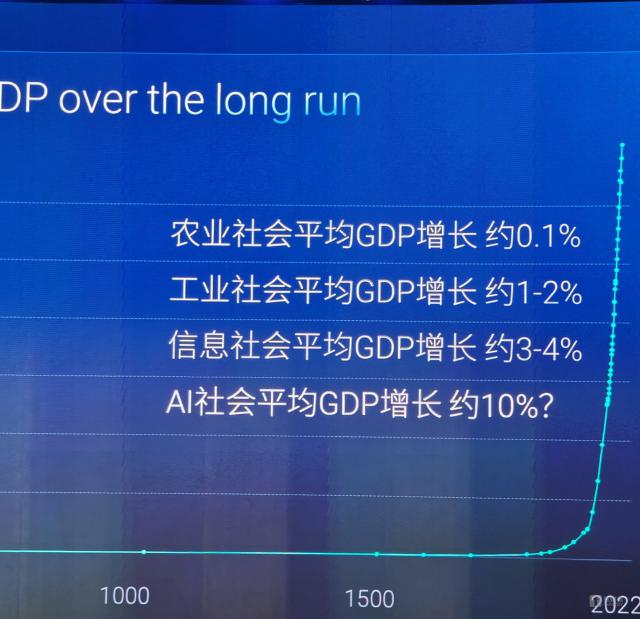
这种增长给社会带来了什么问题?有一句话我想问 AI 从经济最大增长到人类最大福祉的发展,是否可以转化为?那就是为什么在座,在座, IDEA 在人工智能发展的道路上,研究所从事技术研发的同事们,产业落地这些同事都是必须考虑的问题。
谢谢大家!期待明年再见。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com