
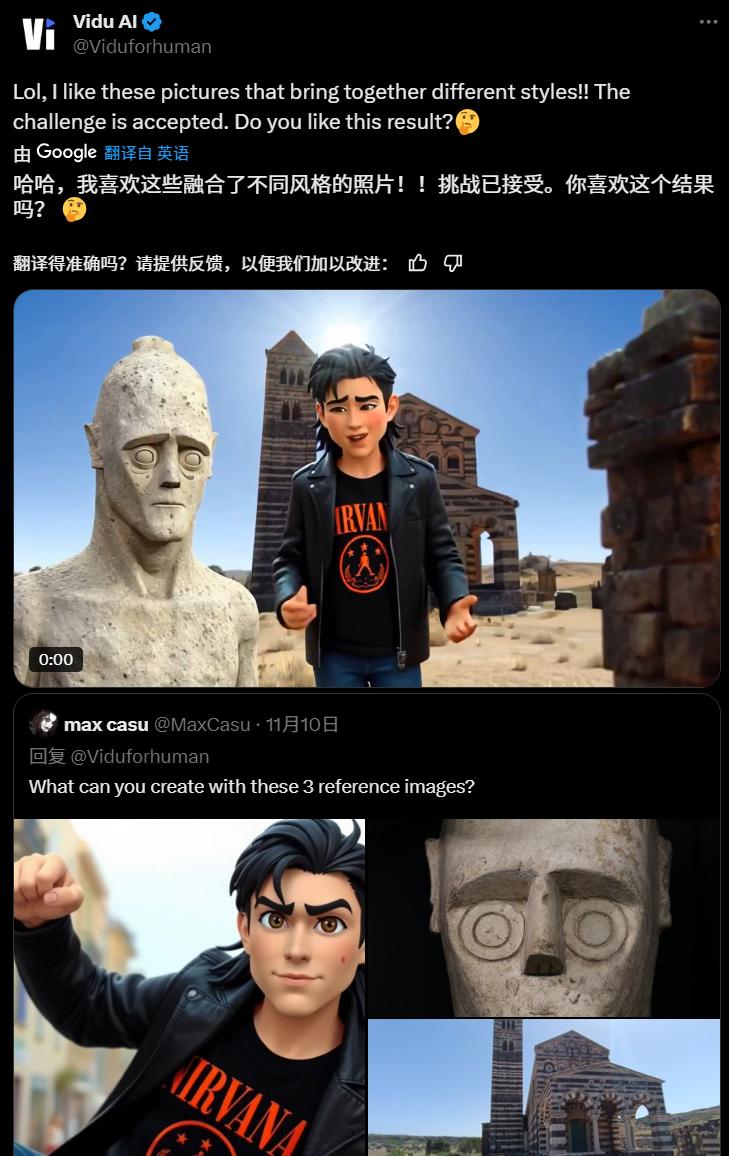
这位清华大佬的整个工作,让李白换上了吊带裤。







粉红连衣裙,黑色大波浪的美女,惊恐转身后,露出一张像张宋小宝一样迷人的脸庞。
嘴唇微微张开,欲语还休。

身穿东北大花外套的美国三好青年马斯克,站在白宫前,风吹雨打。
双手一揣,略带紧凑地露出一丝拘谨、正直的微笑。

而且在另一边,魔卡少女小樱也在拉着隔壁的蕾姆,在三里屯商场购物。
世超当然知道自己见过各种各样的东西。 P 图软件和 AI 技术上的你。估计看到这些效果,也是轻轻一笑:
一年前,哥哥就看到了这个效果。
哥哥不但可以让马斯克改装,就是让他跳舞,也是手拿捏。

但是慢,上边这类视频的形成方法,也许和你以前见过的不一样。
这是由清华团队推出的生数科技联合推出的视频模型。 Vidu 1.5 ,该模型具有新的能力:多主体一致性。
就大白话而言,就是为了生成视频,我们可以上传多张图片。并确保这些复杂的元素不会变形。
举例来说,上传角色、物体和地点的图片,它可以利用你指定的这些元素,制作一个视频。
通过这种方式,我们可以在产生时自己设置人物、物体和场景。
像马斯克这样的视频,就是用一张马斯克的大头照,一件花袄,还有一张白宫的照片,生成的。
丢掉一个简单的提示, Vidu 你可以复制一个以假乱真的视频。让马斯克,穿上你给的大花袄,在白宫前展示一段。

如此整体的好处不言而喻,AI操作可手动操作 生成材料,让视频更符合我们的心意。
在此之前,我们只能扔一句话,或者扔一张照片, AI 自由发挥。最终的结果很容易脱离我们的期望。
举例来说,如果你直接说让马斯克穿一件大花袄,它也会真的在马褂上画几朵大花。

如果 AI 在词库里,没有大花袄这种东西。不管我们如何调整提示,最终都无法生成。
但是现在,你不必使劲憋提示词,只要闭上眼睛甩一张图片。
以前还没有视频模型能做到这一点,很多时候能够把一张上传的图片处理好,就已经很得劲了。
因此, Vidu 这一模型一发布。各种外网网友,立刻惊呼,然后开始上手。
每个人都可以直接打开 Vidu 官员们,试一试。但是,现在只有三次免费的机会,后面每次试用都会消耗掉。 4 个积分。
为让大家整体了解,世超试用了一天。每个人都可以向下滑动,看看我的效果,然后决定是否要玩。
根据编辑部门的惯例,我们的吉祥物通常是我第一次尝试。
这次,我整理了两张火锅戴头盔的照片,又上传了一辆抹茶绿色的雅迪电瓶车。
输入提示词:骑雅迪电瓶车的金毛犬。

大约几十秒钟后,火锅上戴着黑色防风镜,就这样顺利地骑上了小电驴。
甚至胸前的蓝色吊坠,还有雅迪的橙色车标,都完全保留了下来。这种一致性效果还是挺亮眼的。
同时还加入了伸舌头和摇尾巴的小细节。

虽然像火锅这种滑板一样的骑车动作,肯定是不能上路的。
但是,因为狗本来就不会骑电驴,所以我们也不能强求。后边,世超换了张乔布斯的大头照,这个效果非常好。
而且,我还特意上了一些困难。使乔布斯也像马斯克一样,穿上了我们特色的军装外套。

硬朗的五官配上笔挺外套,效果还是很板正的。
乔布斯应该也没有想到,自己有一天会坐上雅迪的橙色雅座。
尽管只是正脸照,但镜头转向侧面时,人物的特征 (比如小秃头)还是恢复得相当准确。

然而,这些仍然是单一的人物主体,加上一个场景或物体。抓取起来还是比较简单的。
一般而言,我们加入的主体越多,大模型就越有可能抓住错误。
于是我试着上传了一张唐伯虎点秋香的经典图片,然后要求把它脸部换成了我给的另一张图片。

这是一堆人的背影,准确地找到了秋香。让她慢慢地转过脸来,稍微露出侧脸。
尽管没有全脸观人,但是眉目足够一眼丁真。

后面,我又增加了难度。
不仅要换衣服,还要加上动作。让李白和蔡徐坤在语文教材上互换一下:李白穿着吊带裤打篮球。

这次, Vidu 给予的效果相当抽象。
这直接改变了坤的画风,创造了一个动画版本。尽管保留的格子裤纹路小细节,足以体现用心。
但这个李白 260°水调大扭头,画面实在太怪异了。而且没有完成我输入“打篮球”的指令。

世超在后来的测试中发现 Vidu 尽管可以挑主体。但是,如果动作比较大,或者画面变化比较大,很容易出现上边突然扭头的小事。 bug 。
举例来说,让它把胖虎的玩具娃娃放在冰雪女王手中。

它的确可以处理多个主体,让塑料胖虎凭空变出来,而且,冰雪女王的动作与情景的连接,基本上可以真假难辨。
但是,换进去的胖虎的动作,显然有点小崩溃。五秒钟之内,不断的抽动和变形。

通过一个下午的测试, Vidu 形成效果总是时好时坏。
上一秒,世超一直惊艳,下一秒惊恐的重复。 回。
例如让雷军坐在问界的车里挥手。雷军就这样水灵灵灵地掉到车外,而且,脸也早就崩溃了。

然而,与此同时,它可以完美地让乐高国王在城堡上举起长剑,激情地发表演讲。保持情境和人物,都是一致的。

在崩溃之后,我甚至发现了一些门道。假设你看了文章之后,准备去试一试,那么在给主体拍照时,尽量找一些背景比较干净的图片。
主体挖掘得越好,产生的准确率就越高。
与此同时,将多角度的图片上传给一个主体,也可以使其移动得更加自然。因为模型可以构建一个更加完整的角色。

尽管根据 Vidu 根据官方声明,他们这次放弃了行业主流。 LoRA 微调法。因为这种方法,很容易发生拟合,也就是在理解主体的过程中,会忘记很多原来的知识。
所以,主体的动作和肢体容易崩溃,难以控制。图片中的物品越多,变化越大,就越容易失控。
而 Vidu 新模型采用类似大语言模型的技术,将所有输入处理成视觉数据,这些输入数据可以像大语言模型一样“前后记忆”处理。
这确实让 Vidu 对多主体的处理,迈出了一大步。
但是另一方面,经过简单的测试,世超感到 Vidu 这项技术还有很长的路要走。
其实, Vidu 暴露的问题与早期的文成视频非常相似。也就是说,意思都到了,但是细节还不够,效果不稳定,时不时的抽风。
就像这辆电动车和道路情景一样,无论怎样切换镜头都不会变形。正是在运动时,人物出现了影分身。
指定照片:初音未来,雅迪电动汽车及道路
假如你想用它来完全取代视频工作者的工作,世超认为还是要等待的。
但 Vidu 肯定是值得上手玩的。
不管怎样,谁不希望自己喜欢的角色穿上我们选择的衣服,不希望自己喜欢的角色。 IP 角色或明星,跨界同框呢?
本文来自微信微信官方账号“差评X.PIN”,作者:star,编辑:江江& 36氪经授权发布面线。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com