
TeleAI 星星语音模型升级,支持中英双语和 40 各种方言随意混说
2024-11-04





IT 世家 11 月 3 中国电信人工智能研究院日新闻(TeleAI)在今年 5 每月发布行业首次支持 30 各种方言自由混合语音识别大模型 —— 星星超多方言语音识别大模型。
时间不到半年,TeleAI 多方言能力的星辰语音模型再一次升级,攻克了湛江话、宜宾话、洛阳话、烟台话等方言,从方言类型出发 30 种提升至 40 种类,并引入英语识别。。
与传统的标注训练方法相比,TeleAI 通过语音识别模型的预训练,使用大量的无标记数据进行预训练,然后通过少量的有标记数据进行微调。
由于方言语音数据普遍具有无标注数据多、标注数据少的特点,这种“”预训练 微调“模型方案与方言场景的需求可以高度契合。
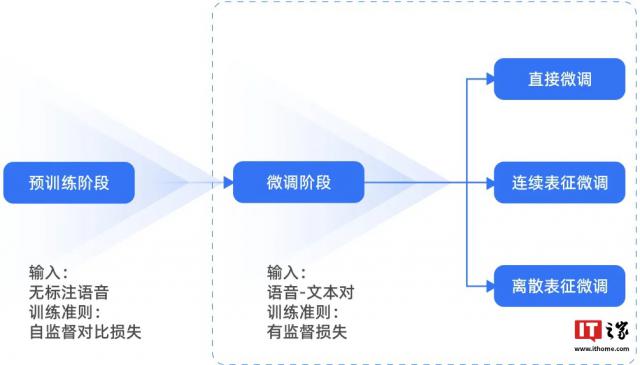
TeleAI 仍然在模型结构和成本优化方面进行了创新,大大降低了对人工标注数据的需求。 50 倍,并保证模型效果等于有监督训练的方言模型。
IT 世家附 GitHub 开源地址:https://github.com/Tele-AI/TeleSpeech-ASR
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com