
KG 超越传统架构的LM,海德堡提出了GLM全新的图形语言模型





【导读】最近,海德堡大学的研究人员推出了图语言模型。 (GLM),把语言模型的语言能力和知识图谱的结构化知识统一到同一个模型中。
语言模型(LM)成功似乎掩盖了别人的光辉。
比如知识图谱(knowledge graph,KG),这是一个结构化的知识库,融合了实体关系。
一般而言,语言模型代表语言能力,而知识地图则包含构造信息。
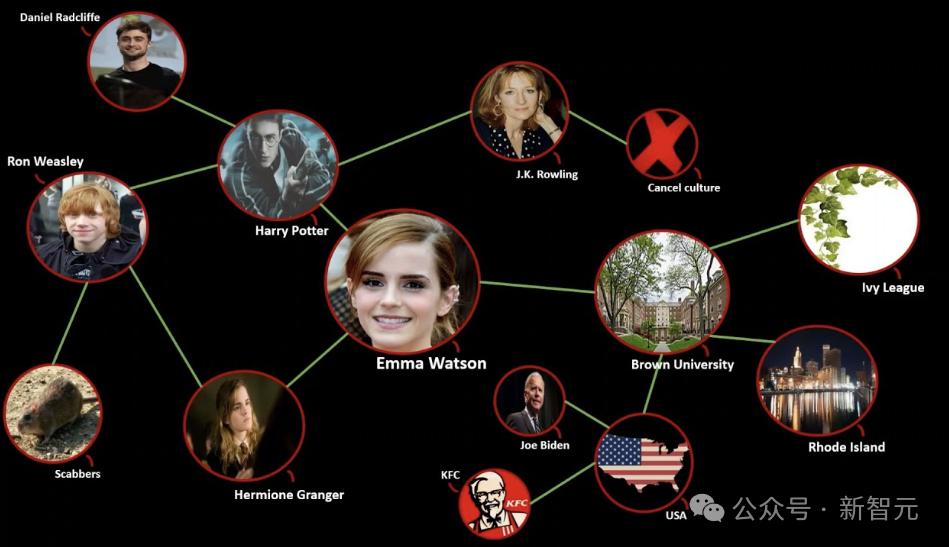
长期以来,KG的应用大致可分为两类:
首先是将KG线性化后嵌入LM,这种行为不能充分利用其结构信息;
二是使用图神经网络。 (GNN) 为了保留图形结构,但是GNN不能表达文本特征,也不能结合LM的预训练特征。
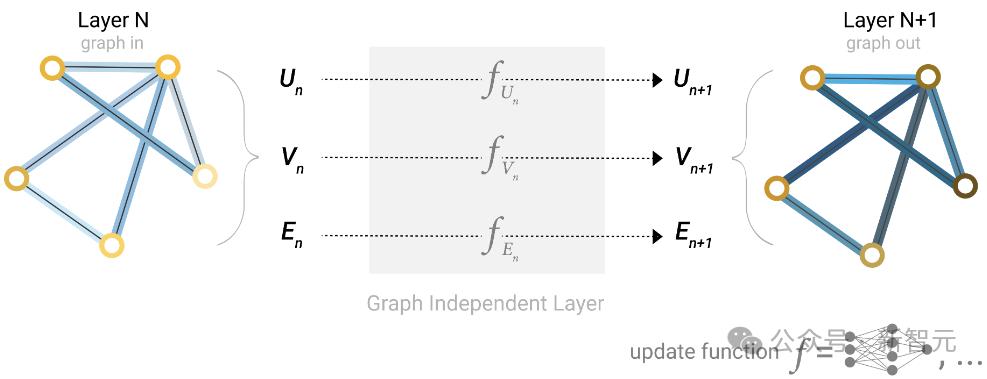
——有什么方法可以结合两者的优点,既保留LM的预训练能力,又可以充分利用KG来提高模型对图形概念和三元组的认识?
肯定有,否则小编就不会写了,也就是海德堡大学的研究人员推出的图语言模型 (GLM)。

论文地址:https://aclanthology.org/2024.acl-long.245.pdf
GLM整合了两种方法的优点,弥补了它们的缺点。
采用预训练LM对GLM参数值进行初始化,同时还设计了一种新的结构来促进有效的知识分配,使GLM能够同时处理图片和文本信息。
以下是关系分类任务的实证评价结果。在这些复杂的任务中,模型需要推断文本和图片的互补输入,推断文本中不会有信息。
资料表明,GLM已经超过了基于LM和GNN的基线进行监管和零样本检测。
另外,通过线性检测试验,作者还证明了GLM的结构变化与原LM的权重高度兼容。
图语言模型
对于组织大量数据,促进信息检索,揭示决策中隐藏的意见,KG尤为重要。
KG擅长准确表达各种关系。一般采用三元组的方式:节点是实体,代表两者的关系。以下是这种复杂的结构,统称为GoT。
为有效地使用GoT,我们需要对其部件进行有价值的编码。
上面提到了使用语言模型和GNN的问题。本质上,两种结构是由不同的基本原理驱动的,LM使用语义代码,而GNN实施结构推理。
结合
作者通过文本与结构信息的初步结合,在图语言模型的设计中解决了这一问题。
第一,利用LM现成参数进行初始化——一是保持预训练的能力,二是从零开始训练过于昂贵。
通过对LM的自注意模块进行一些非侵入性的改变,将LM转换为Graph。 Transformers(GT),与预训练参数同时保持兼容性。
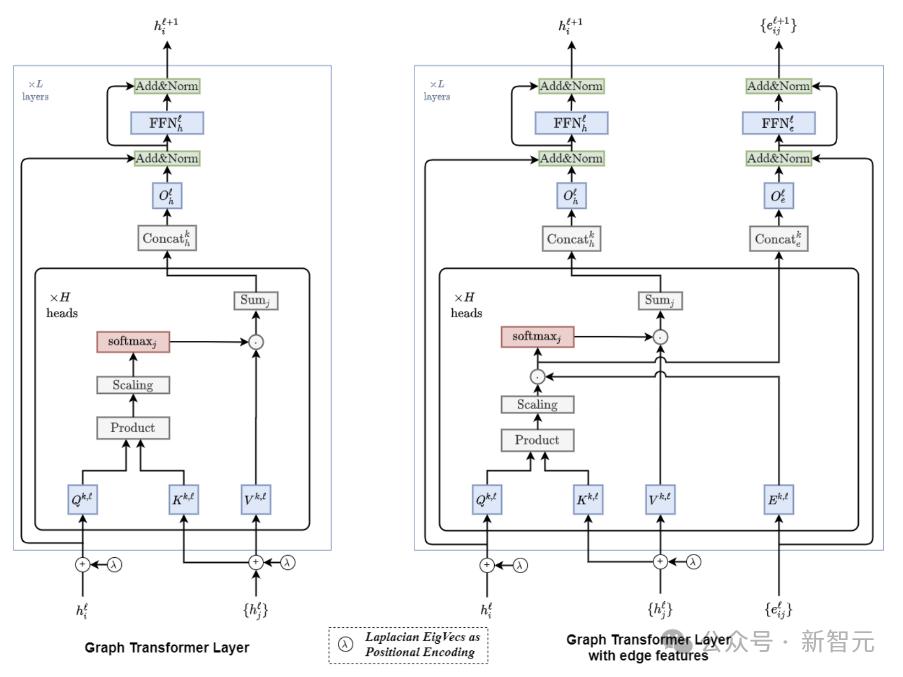
对图表进行编码时,LM用于处理三元组线性组织的文本信息,而GT则沿图表结构汇集信息。
所以,GLM继承了LM对三元组文本的理解,而且GT模块可以在没有额外GNN层的情况下直接进行构造推理。
重要的是,文本序列可以看作是一种特殊类型的图表,GLM中的处理方式与原始LM相同。
Graph 设计Transformer
Self-Attention中的Attention可以写成
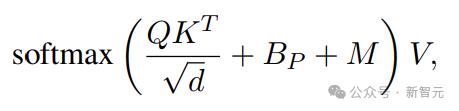
熟悉的Q除外、K、V, Bp代表位置代码,M代表mask矩阵。
位置编码在Transformer中。 (PE) 用来告知token在语言模型文本中的顺序。
包含绝对PE(编码token的绝对位置)和相对PE(token之间的位置关系),一般在输入序列中加入绝对PE。
与PE相比,学习每一个可能的距离的标量:
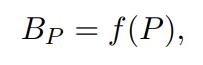
对GT来说,定义节点或边缘的绝对位置并不容易。所以,本文选择了相对PE。
给出图中的非循环路径。我们可以将路径上任意一对节点之间的距离定义为节点之间的跳数,从而获得相对距离。(PE)。
M(mask)矩阵
在传统的Transformer中,自我注意是为了计算输入中所有可能的标记。
相比之下,GNN中的节点通常只关注相邻节点,远程节点之间的信息必须跨越多个GNN层进行传播。
对图片而言,这种稀疏的信息传递方式有时是首选,因为在大多数图片中,随着半径的增加,该领域的大小呈指数增长。
所以,在GT中引入图先验可能是有益的,比如只计算局部领域的自注意力(M中连接的节点对应设置为0)。
另一方面,事实证明,图表的整体视图可以实现快速和远程的信息流。因此,作者创建了两个版本:本地GLM和全局GLM。
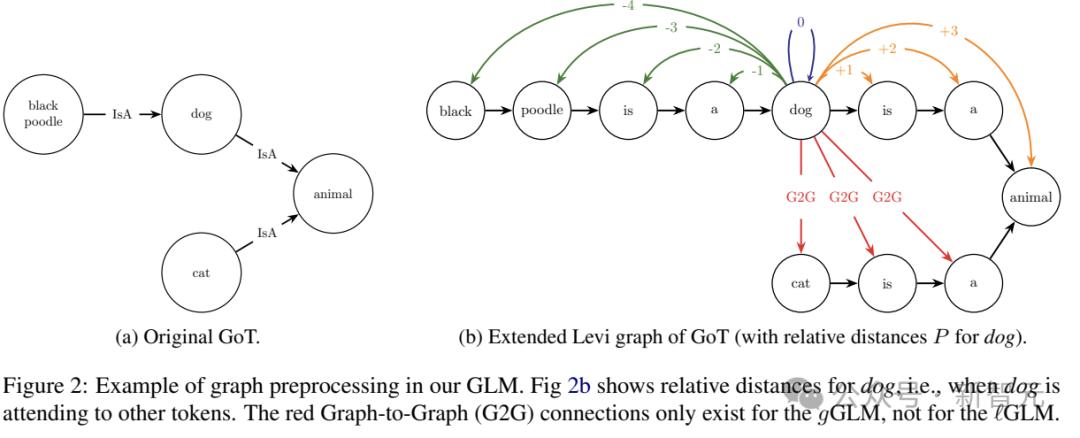
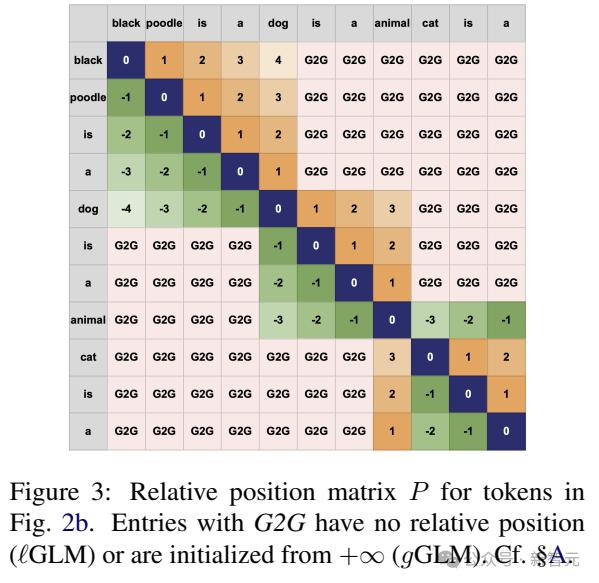
如上图所示,G2G连接属于全局视野,当地GLM并没有处理这种关系。
自注意力机制仅限于同一三元组的token,而在当地GLM中,所有外部token的注意力都被设定为 0(所以也不需要PE)。
即便如此,由于属于一个概念的token可以由多个三元组共享,消息可以通过图片跨越多个层进行传播(类似于GNN中的标准消息)。
因此,即使非相邻节点没有直接连接,共享信息仍然可以通过消息传递。
举例来说,在第一个本地GLM层中,「狗」通过三元组「黑贵宾犬是一只狗」和「狗是一种动物」来表达吧。所以,在第二层,「动物」这个表达会被接受「黑色贵宾犬」尽管两者之间没有直接的联系,但影响。
此外,研究人员还将全局GLM形式化,可以将任何节点连接到每个其他节点(比较自我关注)。这种形式需要为随机token设置PE,包括不存在于同一三元组的token。
所以,GLM引入了新的图到图(G2)G)位置关系。在LM中,G2G连接参数值没有被学习,所以在这里使用位置关系( ∞ )初始参数表示相应的token出现在文本段落中很远的地方。
预处理
图先验引入了GT架构,而LM的参数初始化赋予了其语言理解能力。
修改模型的整体思路是,三元组应该尽可能地类似于自然语言,这样LM才能学习,图片推理应该通过信息传递来工作。
GoT还需要同样的处理方法,以便GLM能像LM一样处理图表,类似于LM分词器将文本转换为词表中的向量。
为了实现这一点,研究人员首先将GoT转换为Levi图,用包含关系名称作为文本特征的节点更换每个边缘,并将新节点连接到原始边缘的头部和尾部,以保持原始边缘的方向。
下一步,将每一个节点拆分成多个节点,每一个新节点对应一个token,重新建立边缘连接相邻节点,保持原来的方向。
每一个三元组都被表示为一个token序列,就像标准LM一样。
位置编码
如上所述,用token编码它们之间的位置关系——只需将三元组视为一段文本,并计算文本中的token距离。
请注意,转换后的谷歌序列可能与输入三元组的谷歌序列不完全一致。在这里,我们独立标记Levi图中的每个节点,以确保多个三元组共享概念的一致性。
在token不属于同一三元组的情况下,为了确定这些token之间的距离,之前的工作考虑了两者之间最短路径的长度。
但是,PE对LM来说并不自然,因为如果在最短的路径上以错误的方向遍历,三元组就会以相反的顺序出现。
所以,本文省略了token之间没有构造数据的PE,并使用局部PE。 (ℓGLM) 和全局 (gGLM)。
实验结论
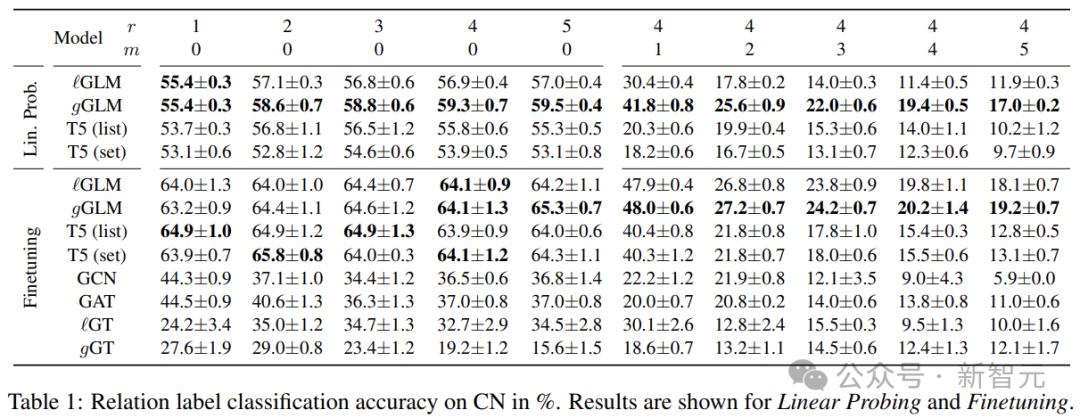
在两个关系(标签)分类试验中,作者评估了GLM嵌入GoT的能力(对哪些关系属于给定的头部实体和尾部实体进行分类)。
ConceptNet子图试验用于分析框架图属性的影响;但是在维基数据子图和关于维基百科摘要的实验中,用来检测文字和图形的交错输入能力。
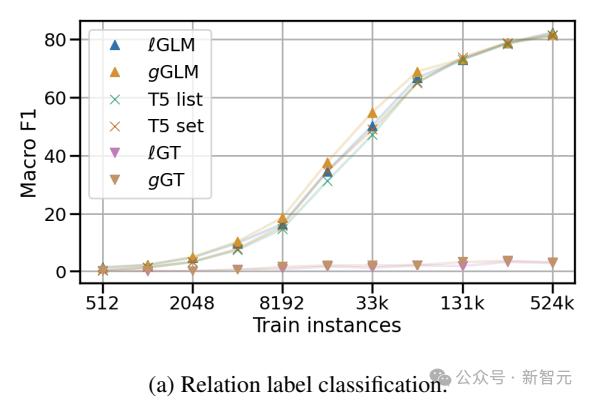
研究人员构建了包括13,600个训练案例、1,700个开发案例和1,700个检测案例在内的均衡英文CN子图数据,并以17个不同的关系作为标签,即用T5模型的第一个掩码替换预测关系。
GLM对图片进行编码,嵌入每个token。线性分类头根据掩码的嵌入给出最终预测。在这里,静态模板被用来表达未屏蔽的关系。
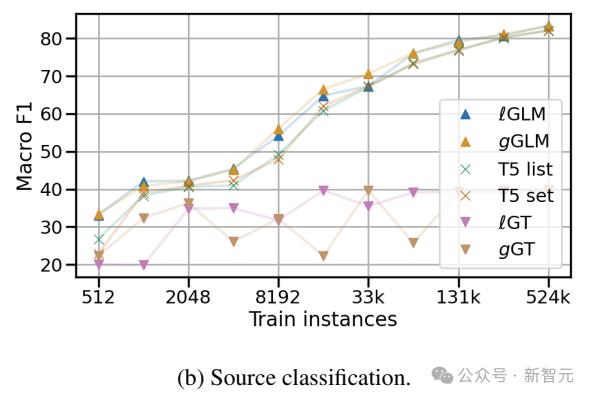
在ConceptNet子图中,关系分类的实验表明,即使继承的LM参数在GLM训练期间没有更新,GLM也优于基于LM和GNN的编码方法。
KG人群在维基数据子图和维基百科摘要中的实验表明,GLM能够推断GoT和文本的交错输入,这是LM所不具备的新能力。
参考资料:
https://aclanthology.org/2024.acl-long.245/
本文来自微信微信官方账号“新智元”,编辑:alan,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com