
8B新AI英伟达发布 模型:精度高,效率高,可在。 RTX 在工作站上运行
2024-08-24








IT 世家 8 月 23 日消息,英伟达于 8 月 21 每天发布博文,发布 Mistral-NeMo-Minitron 8B 小语言 AI 该模型具有精度高、计算效率高等优点。,可在 GPU 加速数据中心,云和工作站运行模式。

英伟达携手 Mistral AI 上个月发布开源 Mistral NeMo 12B 在此基础上,英伟达再次推出了更小的模型。 Mistral-NeMo-Minitron 8B 模型,共 80 亿次参数,可搭载英伟达 RTX 工作站运行显卡。

英伟达表示,通过总宽修枝(width-pruning)Mistral NeMo 知识蒸馏12B(knowledge distillation)经过轻微的再次训练后得到 Mistral-NeMo-Minitron 8B,有关结果已经发表《Compact Language Models via Pruning and Knowledge Distillation》文章中。
通过清除对精度贡献最小的模型权重,修枝可以减少神经网络。 " 蒸馏 " 在此过程中,研究小组在小数据上再次对修枝后的模型进行训练,以显著提高修枝过程中的精度。
就其规模而言,Mistral-NeMo-Minitron 8B 在九个流行的语言模型基准测试中遥遥领先。这些标准包括语言逻辑、常识推理、数学推理、总结、编码和生成真实答案的能力。IT 这个家庭的其他相关测试结果如下:
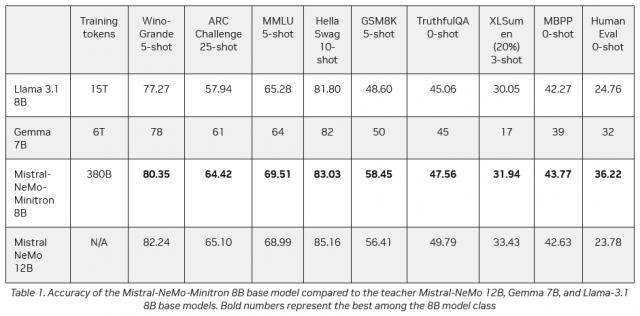
参照
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com