
超过最强闭源模型的开源模型,Llama 3.1能否颠覆AI生态?






Llama 终于3.1来了。
Meta在美国当地时间7月23日正式发布Llama。 3.1。它包含8B、70B 以及405B三大规模,最大前后文提升到128k。目前,Llama是开源领域客户最多、性能最强的大型模型系列之一。
这次Llama 3.1的要点如下:
1.共有8B、70B版本和405B版本,其中405B版本是目前最大的开源模型之一;2.该模型拥有4050亿参数,在性能上超过了目前的顶级AI模型;3.该模型引入了更长的前后文窗口(最长可达128K tokens),能处理更复杂的任务和对话;4. 支持多语言输入输出,提高模型的实用性和适用性;5.提高推理能力,特别是在处理复杂的数学题目和即时生成内容方面。
Meta在官方博客上写道:“到目前为止,开源大语言模型的性能落后于闭源模型仍然是正常的。但是现在,我们正在迎来一个开源推广的新时代。我们公开发布Meta Llama 3.1 405B是世界上最大、最强大的开源基础模型。到目前为止,Llama版本的累计下载次数已经超过3亿,这只是一个开始。
在技术领域,开源与闭源的争论一直是热门话题。
开源软件更加透明灵活,允许全球开发者共同审查、修改和优化代码,从而促进技术的快速创新和进步。闭源模型通常由单个公司或组织开发和维护,可以提供高质量的支持和服务,以确保软件的安全性和稳定性。然而,这种模式也限制了客户的控制和定制能力。
在此之前,闭源模型一直略胜一筹。直至Llama。 3.1的发布,在持续激烈的开源与闭源之争中,写出了浓墨重彩的一笔:开源模型最终可以与闭源模型一战。
根据Meta提供的基准测试数据,最受关注的405B版本在功能上已经可以与GPT-4和Claude一起使用。 3相当于Human。 Evaluation主要用于评估模型在理解和生成代码、处理抽象逻辑问题方面的优势。与其它大型模型竞争时,Llama 3.1 405B看上去略胜一筹。
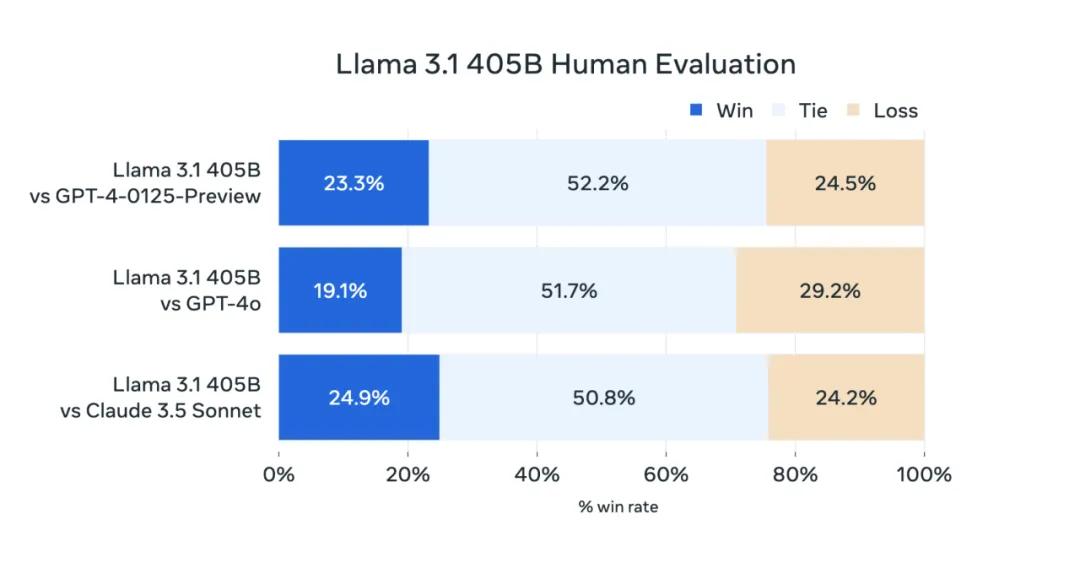
Llama 3.1与GPT-4、Claude 3.5旗鼓相当,来源:Meta
斯坦福学校计算机科学系及电子工程系副教授、人工智能实验室主任吴恩达(Andrew Ng)称赞Meta和Llama团队在社交平台上对开源的杰出贡献。 他指出: “Llama 3.1增强了前后文的长度和改进功能,是送给每个人的奇怪礼物。 并且希望“像加州建议的SB1047这样愚蠢的法律法规不会阻止这种创新”。
来源于吴恩达的社交媒体:X
Meta首席人工智能科学家杨立昆图灵奖获得者(Yann LeCun)引用了《The Verge》对于Llama 性能描述3.1-Meta发布了迄今为止最大、最优秀的开源人工智能模型: Llama 在一些基准测试中,3.1超越了OpenAI和其它竞争者。
来源于杨立昆的社交媒体:X
有趣的是,Llamamama昨天405B版本 怀疑是HugginFace、在GitHub上被“偷走”,爆料者发布的评估数据与今天正式发布的版本信息基本一致。
Meta的创始人兼首席执行官马可·扎克伯格写了一篇题为《开源人工智能是未来之路》的文章。(Open Source AI Is the Path Forward)》长篇文章,详细阐述了开源对于开发者、Meta和为什么对于全世界都有重要意义。
他预料到今年年底,Meta AI将超越ChatGPT,成为使用最广泛的助手。
他还表示:誓言将开源到底。
《Open Source AI Is the Path Forward》文章切片,来源Meta
1.Llama 3.1的炼成
就模型结构而言,Meta是迄今为止最大的模型,Llama 3.1 在超过 15 在2023年12月,有数以万亿计的token数据进行练习,预训练数据日期截止。
Meta用了16000多个H100,405B是第一个在这个规模上训练的Llama模型,以便在合理的时间内在如此大规模的范围内实现训练,并取得预期的效果。
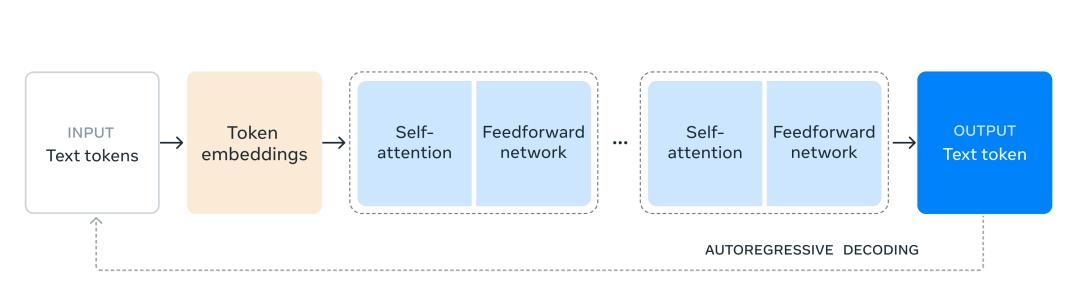
Llama Transformer模型架构在3.1文本生成过程中,来源:Meta
Meta选择了标准的只解码器Transformer模型架构进行微调,以最大限度地保证训练的稳定性和便利性,而不是使用目前流行的混合专家模型。(MoE)架构。
这个决定促使Llama 3.1在支持近128K的前后文长度时,仍然可以保证短文的高质量导出,妥善处理长文,而不仅仅是致力于长文。
与此同时,研究小组实施了一种迭代的后训练方法,生成高质量的生成数据,通过每一轮监管微调和直接偏好提高模型的各种功能。与之前的版本相比,Llama 3.1增强了预训练和后训练数据的数量和质量,引入了更详细的预处理和管理系统,以及更严格的质量保证和过滤技术。
按照扩展规律的语言模型,Llama 3.1在性能上超过了以前使用相同训练程序的小模型。
Meta将模型数据从16位(BF16)量化到8位(FP8),以满足大规模405B模型运行的需要,大大减少了计算资源的需要,使模型能够在单个服务器节点上运行。
Llama 3.1 在405B模型指令和聊天微调方面,开发团队致力于提高模型对客户指令的响应性、实用性和质量,同时保证高安全性。
在后期训练阶段,团队在预训练的基础上进行了几轮调整。每轮包括监管微调。(SFT)、拒绝取样(RS)并且直接喜好提升(DPO)。另外,团队使用生成数据来产生大部分的生成。 SFT 举例来说,它们并不完全依赖于现实世界中的数据,而是通过算法产生的数据来训练模型。
与此同时,团队还采用多种数据处理方法对这些信息进行过滤,以确保质量最高,并扩大微调数据的应用范围。
Meta也在探索一个新的策略,即使使用405B模型作为70B和8B模型的“教师模型”,然后从大型模型中提炼出适合各行各业需求的小型定制模型。GPT-4o mini的策略不谋而合,也就是“先做大,再做小”。
Andrej之一的OpenAI创始成员 Karpathy曾经对GPT-4o Mini评论道:“模型必须先扩展,然后才能变小。因为我们需要它们(自动)来帮助重构训练数据,使它们成为理想的、生成的格式。”他指出,这种方法可以有效地将大模型的深度和广度知识转移到更实用、更便宜的小模型中。
Meta作为开源模型路线的领导者,在Llama模型配套设施方面也给予了足够的诚意。
Llama系统被设计成一个可以整合多个部件的综合框架,包括调用外部工具。Meta的目的是为开发者灵活设计和创建适合自己需求的定制产品提供更广阔的系统。
为了在模型层之外负责任地发展AI,研究小组发布了包括多个示例应用和新组件在内的完整参考系统,例如多语言安全模型Llamama Guard 并提醒注入过滤器Prompt Guard。这类应用是开源的,可供社区进一步开发。
科研人员与行业、创业公司、广泛社区合作,并在GitHub上发布“为方便定义零部件接口,促进其在行业中的规范化”Llama Stack"建议."这是一个标准化的接口,可以简化工具链部件(例如微调、生成数据生成)和代理应用程序的构建。
基于Meta提供的基准测试数据,Llama 3.1 405B 在NIH/Multi-needle 分数为基准测试 在性能评分方面,98.1与GPT-4和Claude 3.5等不相上下。在ZeroSCROLLS/QuALITY基准测试中,405B版本以优异的整合海量文本信息能力得分为95.2,对关注RAG特性的AI应用开发者非常友好。
Llama 与GPT4等闭源模型相比,3.1的来源:Meta
Llama Mistral3.1 7B 与Instruct等开源模型相比,来源:Meta
Llama 3.1 8B 显著优于版本 Gemma 2 9B 1T 和 Mistral 7B Instruct,与上一代Llamama相比, 3 8B的表现有了明显的提高。与此同时,Llama 3.1 70B GPT-3.5甚至超过了版本。 Turbo。
据Llama团队的官方报道,他们对这些模型进行了深入的性能评估,并在150多个多语言基准数据集中进行了大量的人工测试。数据显示,Llama的顶级模型可以与GPT-4等市场顶级基础模型进行各种任务。、GPT-4o和Claude 3.5 相当于Sonnet。与此同时,Llama的小版本与具有相似参数规模的封闭和开源模型相比,同样具有很强的竞争力。
开源模型与闭源模型的争论
究竟开源模型可以超越闭源模型吗?
这个问题从去年开始就备受争议。两种模式的发展道路代表了不同的技术哲学,在推动技术进步、满足商业需求方面各有优势。
比如Llama 3.1是一个开源模型,允许研究人员和开发人员浏览其源代码,每个人都可以自由研究、修改甚至改进模型。这种开放鼓励了普遍的合作和创新,让不同背景的开发人员可以一起解决问题。
相对而言,ChatGPT是由OpenAI开发的闭源模型,虽然它提供了API浏览,但是它的核心算法和训练数据并没有完全公开。GPT-3的闭源特性使其在商业化道路上更加稳定,控制保证了产品的稳定性和安全性,在处理敏感信息时更受公司信任。然而,这种封闭性也限制了外部研究者对模型的完全理解和创新能力。
去年5月,外媒报道谷歌流出了一份文件,主题是“我们没有环城河,也没有OpenAI。当我们还在吵架的时候,开源已经悄悄抢走了我们的工作”。同年,Meta发布了开源大模型Llama 后来,杨立昆说,Llama 2将改变大语言模型的市场结构。
人们期待着Llama系列模型引领的开源社区。在此之前,最先进的闭源模型GPT-4一直略胜一筹,尽管当时的Llama。 3 相比之下,差距已经很小了。
最权威的大模型领域名单是大模型试验场(LLM Arena),ELO积分系统一直采用国际象棋。它的基本规则是让用户向两个匿名模型(例如 ChatGPT、Claude、Llama)提出任何问题,并投票给一个更好的答案。回答更好的模型会得到积分,最终的排名由积分的高低决定。Arean ELO收集了50万人的投票数据。
大型模型排名列表,来源:LLM Arena
在LLM OpenAI在Arena排行榜上。GPT-4o目前排名第一。前十名的模型都是闭源模型。虽然闭源模型在排名上仍然遥遥领先,但李彦宏在2024年百度AI开发者大会上并没有说开源模型和闭源模型的差距越来越大,实际上正在逐渐缩小。
在WAIC期间,李彦宏说:“开源实际上是一种智商税”。来源:百度:
直到今天Llama 3.1的发布,开源模型终于可以和闭源模型顶峰一战了。
对开源、闭源模型哪一种更好,「甲子光年」曾经和很多AI行业从业人员讨论过。业界普遍认为:通常取决于个人立场,而非简单的黑白二分问题。
开源和闭源不是纯粹的技术区别,更多的是关于商业模式的选择。目前还没有找到完全成功的商业模式,无论是开源还是闭源。
那么是什么因素影响了开源和闭源模型之间的能力差异呢?
微博新技术R&D负责人张俊林指出,模型能力的增长速度是一个关键因素。如果模型能力快速增长,则意味着短时间内需要大量的计算资源。在这种情况下,闭源模型因其资源优势而更具优势。相反,如果模型能力增长缓慢,开源和闭源之间的差距会减小,追求速度也会加快。
他认为,未来几年,开源模型和闭源模型的能力差异将取决于“生成数据”技术的发展。如果“生成数据”技术在未来两年取得显著进展,两者之间的差距可能会增加;如果没有突破,他们的能力就会趋于相似。
总的来说,“生成数据”将成为未来大语言模型发展的核心技术。
无论是开源还是闭源,都不决定模型特性的高低。闭源模型不是因为闭源而领先,开源模型也不是因为开源而落后。相反,模型选择闭源是因为领先,因为不够领先,不得不选择开源。
假如一个企业做了一个性能非常强大的模型,它就有可能停止开源。
比如Mistral,法国艺人创业公司,Mistral-7B开源最强的7B模型,8x7B开源MoE模型(MMLU 70)是开源社区中声音最大的模型之一。然而,Mistral后续训练的Mistral-Medium(MMLU-75)、Mistral-Large(MMLU-81) 全部为闭源模型。
当前性能最好的闭源模式和性能最好的开源模式都是由大型企业主导,而Meta在大型企业中的开源决心最大。假如OpenAI不开源是从商业收益的角度来考虑的,那么Meta选择开源让用户免费试用的目的是什么?
在上一季度的财务报告会上,扎克伯格对此事的回应是,Meta开源的AI技术是为了促进技术创新,提高模型质量,建立行业标准,引进人才,增加透明度,支持长期战略。
这一次,扎克伯格在《开源人工智能是未来之路》中(Open Source AI Is the Path Forward)》对“开源AI为什么对开发者有益”进行了详细解释。:
在与来自世界各地的开发者、首席执行官和政府官员的对话中,我经常听到他们强调培训、微调和优化自己的模型。
每个组织都有自己独特的需求,可以根据这些需求优化不同规模的模型,使用特定的数据进行练习或微调。在简单的设备中,目标和分类任务可能需要更小的模型,而更复杂的任务需要更多的模型。
现在,你可以使用最先进的Llama模型,然后用你自己的数据来训练它们,然后把它们优化到理想的规模——我们或其他任何人都不会接触到你的数据。
与某个闭源供应商相比,我们需要控制自己的命运。
许多组织不想依靠他们无法自行运行和控制模型。他们担心闭源模型提供商可能会改变模型、使用条款,甚至完全停止服务。他们不想被限制在一个单一的云平台上,拥有一个模型的独家权利。开源为企业提供了一套兼容的工具链,使得在不同的系统之间切换变得容易。
应保护我们的数据。
许多组织需要保护这些信息不被云API发送到闭源模型,以处理敏感数据。其他组织只是不信任闭源模型提供者的数据处理方法。开源通过让你在任何你想要的地方运行模型来解决这个问题,而且因为开发过程的透明度,一般会觉得更安全。
应采用高效、经济的运行模式。
开发者可以在自己的基础设施上运行Llama 3.1 推理405B模型,其成本约为使用GPT-4o等闭源模型的一半,适用于面向用户的离线推理任务。
我们下注了一个有望成为长期标准的生态系统。
许多人看到开源模型比闭源模型发展得更快,他们希望自己构建的系统结构能够带来最大的长期优势。
本文来自微信公众号“甲子光年”,作者:苏霍伊,编辑:赵健,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com